Pioneering AI to Forge the Most Reliable Driver: Waymo's Autonomous Driving Model Algorithms
 04/21 2025
04/21 2025
 605
605
At NVIDIA GTC 2025, Drago Anguelov, Vice President and Head of Research at Waymo, presented a keynote titled "Pioneering AI to Forge the Most Reliable Driver." The crux of his address emphasized that becoming the world's most trusted driver necessitates the integration of advanced AI models with real-world driving experience to create a safe, dependable, and socially astute autonomous driving system. During the conference, Drago delved into Waymo's practices in autonomous driving algorithms, notably "Building the Driver" and "Validating the Driver."
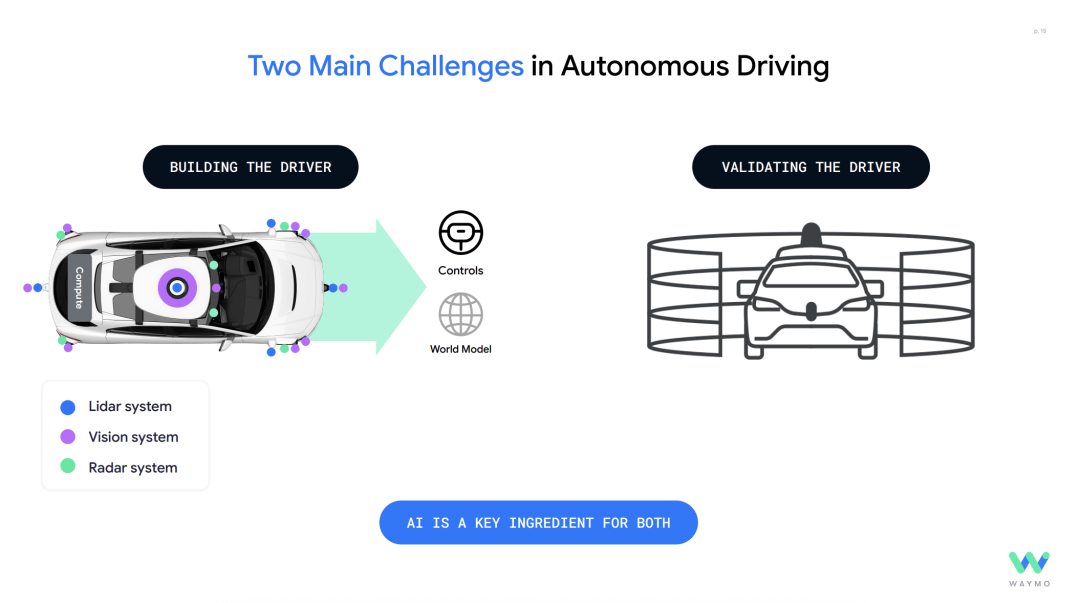
This speech garnered acclaim from numerous technical experts on external networks as the most enlightening content on autonomous driving at GTC 2025. This article summarizes the pertinent details, focusing on Waymo's AI algorithm implementations in autonomous driving, aiming to provide insights and clarity on key terms in cutting-edge AI autonomous driving algorithms. "Building the Driver" - The Evolution from Human to AI Driving Human driving is a multifaceted skill, typically requiring individuals to be at least 16 years old, pass written and practical driving tests, and then be permitted to drive on public roads.
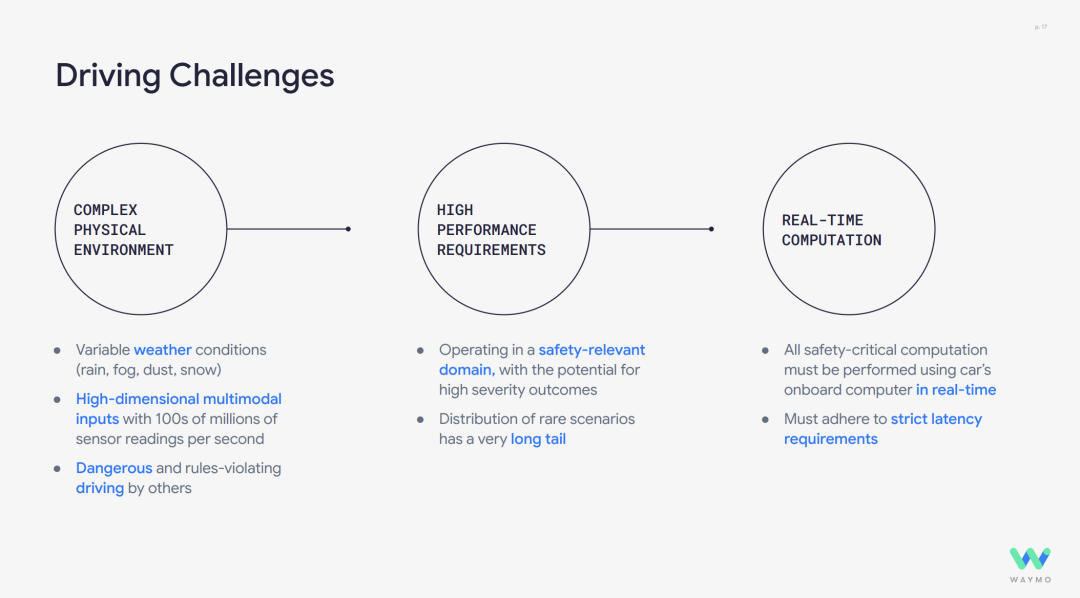
Transitioning to machine driving presents similar challenges: intricate physical environments, real-world driving conditions encompassing various weather, lighting, and dust; and driving hazards posed by other road users. Human eyes process high-dimensional multimodal inputs, interpreting up to 100 million sensor readings per second. High-performance computing is paramount as automotive driving operates in safety-critical areas where errors can have dire consequences. Additionally, various accidents often fall under rare long-tail cases. Real-time computation is essential, with all safety-critical computations needing to be executed in real-time using the vehicle's onboard computer, adhering to stringent latency requirements. Waymo's approach to building drivers leverages AI technology through its Foundation Model.
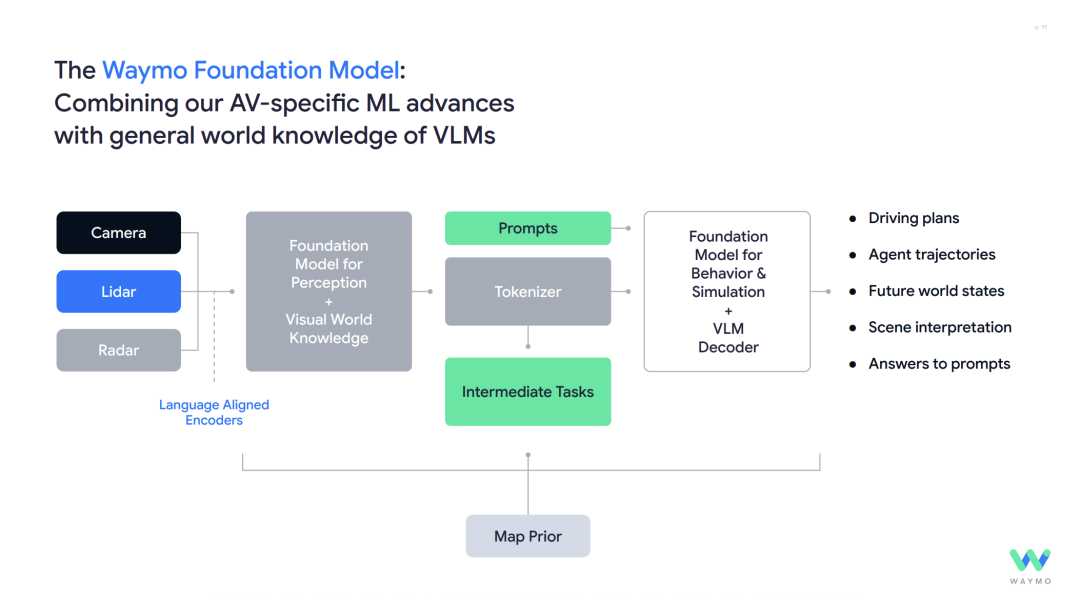
Perceptual Input Data: Integrates data from multiple sensors such as cameras, lidars, and radars. Tokens and Decoder: Processes through Tokenizer and Decoder to generate a unified scene representation, forming a structure akin to language, facilitating processing by large language models (LLMs). Intermediate Tasks: Utilizes Intermediate Tasks (e.g., object detection, semantic segmentation) to extract scene features and enhances spatial reasoning capabilities by combining perceptual results with map priors using Language Aligned Encoders.
The above constitutes Waymo's foundational model framework for driving. Within this framework, Waymo has undertaken more detailed practices. MotionLM Architecture Expansion As earlier mentioned, the most challenging aspect of driving is interaction. Waymo introduced the MotionLM model, which models the behavior of multi-agents, i.e., other traffic participants, as a "conversation," using an LLM-like architecture to predict trajectories (similar to sentences in language), supporting interaction decisions in long-tail scenarios. The model's performance is validated through large-scale computations (FLOPs) to demonstrate the pattern of improvement with increasing scale.
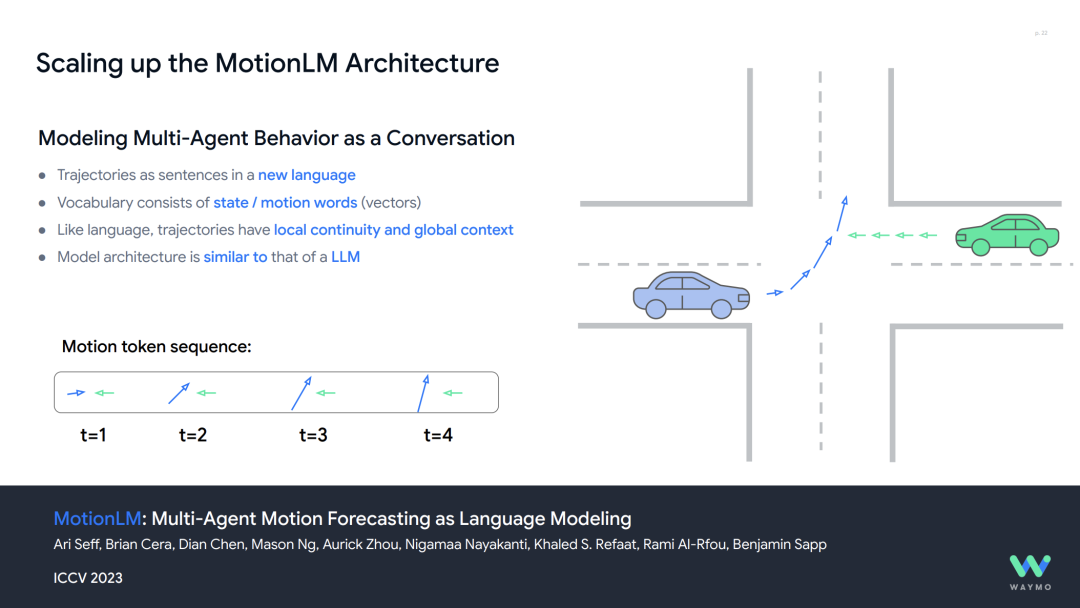
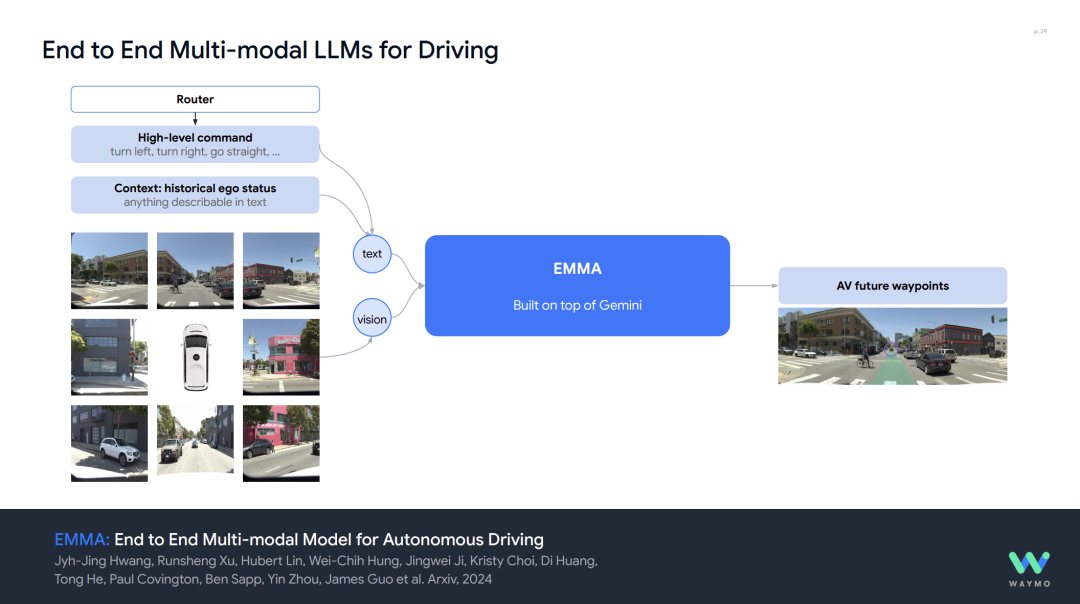
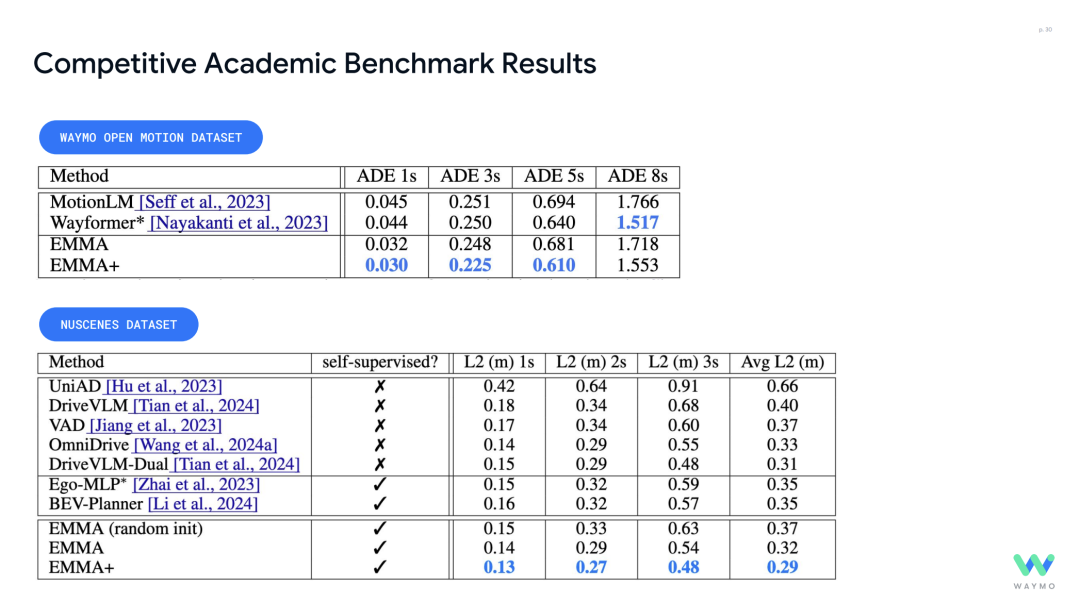
End-to-End Multimodal Model (EMMA) This was previously discussed in our article "Waymo's End-to-End Multimodal Algorithm EMMA Using ChatGPT-Like Large Models as the Core of Autonomous Driving Algorithms." It is based on the Gemini architecture, supporting a unified model for multiple tasks (e.g., 3D object detection, drivable area estimation, path planning). It achieves state-of-the-art (SOTA) performance on Waymo Open Motion and nuScenes datasets (e.g., L2 error of only 0.29m for EMMA+).
It is evident that domestic models such as Horizon's UniAD and Ideal Auto and Tsinghua's Drive VLM exhibit larger errors compared to Waymo's EMMA.
The above are some of Waymo's explorations in "Building the Driver" for autonomous driving. How does one ensure that the built driver is accurate and safe? This is where "Validating the Driver" comes into play. "Validating the Driver" - Addressing the Constraints of Vision-Language Models Why validate the built driver? Methodologically, it is feasible, but the current core technology relied upon in autonomous driving is vision AI, and current vision-language models have their limitations. The constraints of Standalone Vision-Language Models primarily include the following four points:
1. Insufficient Multi-modal Sensor Support: Existing models struggle to effectively integrate data from multi-modal sensors such as lidars, cameras, and radars. However, current autonomous driving requires fusing complementary information from different sensors (e.g., precise 3D localization from lidars and semantic understanding from cameras), and standalone models face performance bottlenecks in such cross-modal alignment and joint reasoning.
2. Limited Accurate Spatial Reasoning: Current models lack sufficient dynamic perception and reasoning capabilities for three-dimensional physical spaces, such as accurately predicting the trajectories of vehicles and pedestrians in complex traffic scenarios (e.g., error accumulation in ADE metrics). For example, the speech mentioned that the ADE error of the EMMA+ model still reaches 1.553 meters in an 8-second prediction window (Waymo Open Motion dataset), indicating that long-term spatial reasoning still needs improvement.
3. Lack of Long-term Memory: Current large models lack the ability to maintain continuous memory of historical scenarios, making it difficult to maintain context consistency in long-duration driving tasks (e.g., tracking continuously moving targets or responding to periodic events). For instance, in complex urban roads (e.g., multiple lane changes, continuous intersections), short-term memory may lead to fragmented decision-making, increasing risks.
4. Insufficient Robust Reasoning without Hallucinations: Current large models are prone to making erroneous inferences (e.g., misjudging obstacle positions) or "hallucinations" (e.g., fabricating non-existent traffic participants) in noisy data or ambiguous scenarios. Similar to Deepseek or ChatGPT, such hallucinations may at most lead to misinformation, but in driving on public roads, any accident risk is a matter of life and death, so it is crucial to validate the "driver" of autonomous driving.

The primary focus of validation is to address the interplay between different driving participants in various scenarios, ensuring the perceived content is accurate. Waymo's practice in "Validating the Driver" includes:
1. Scalable Simulation Validation Platform: Developed the AI-based traffic simulator Scene Diffuser++, which simulates city-level multi-agent traffic flow through a generative world model. This model employs multi-modal tensor diffusion techniques to jointly predict the motion trajectories and state validity of all traffic participants (vehicles/traffic lights) in future time steps. Block-NeRF technology is used to reconstruct the 3D environment of urban blocks through the vehicle's own sensor data, enabling high-fidelity sensor simulation (e.g., lidars, cameras).
Currently, 3D Gaussian Splashes (3DGS) are used to replace NeRF technology. NeRF: Relies on neural networks to implicitly model the scene's radiance field, generating images through volume rendering, requiring complex ray tracing calculations. 3DGS: Uses explicit anisotropic 3D Gaussian models (geometric voxels with appearance information) to directly render scenes, compatible with traditional graphics engines without the need for complex ray tracing.

Adopting 3D Gaussian Splashes (3DGS) real-time rendering technology is 57 times faster than NeRF, enhancing simulation realism and efficiency.
2. Real-Scene Generation and Generalization Validation: Learns a simulator (Real2Sim) based on large-scale real driving data, supporting Controllable Editing, multi-view scene reconstruction, and global editing (e.g., weather, time changes), focusing on addressing the challenge of system generalization in unseen scenarios.
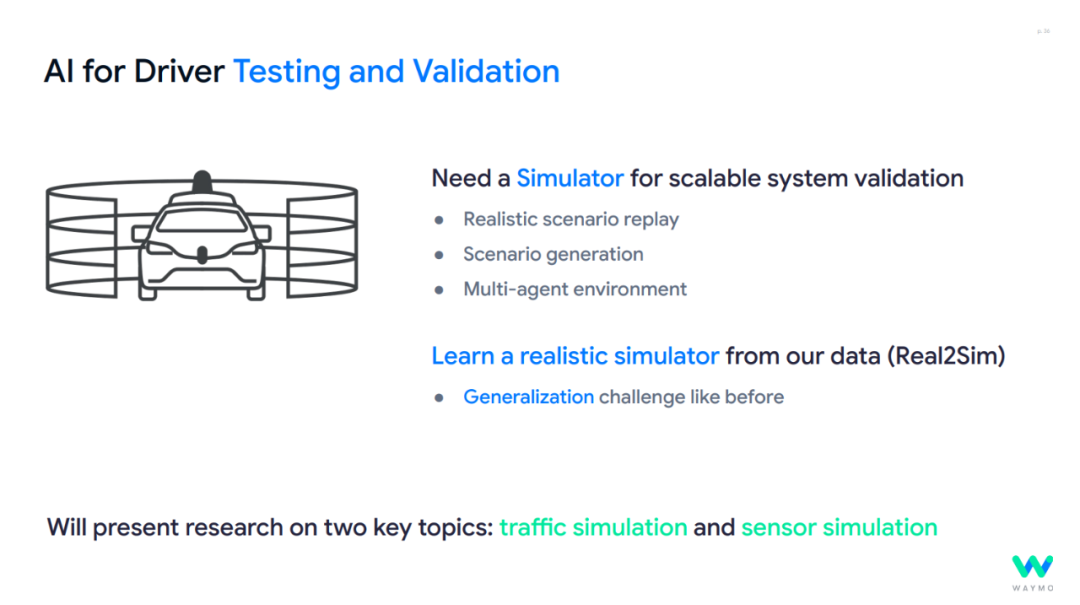
By randomizing vehicle dynamics parameters (e.g., acceleration limits, steering response) and road user behaviors (e.g., simulating inattentive drivers), diverse test scenarios are generated to validate the system's robustness in extreme conditions.
Final Thoughts Waymo is a highly compliant and cautious company. Initially started as a self-driving car project by Google in January 2009, Waymo was spun off from Google in December 2016. However, after 16 years of exploration in autonomous driving, it is still only operational in four cities in the United States and is about to expand to two more cities.
Their business and investment environment, as well as their company philosophy, are admirable and worth learning from. Unauthorized reproduction and excerpts are strictly prohibited. Advancing AI to Build the World’s Most Trusted Driver pdf - VP, Head of AI Foundations Team WaymoDriveVLM: The Fusion of Autonomous Driving and Large Visual Language Models pdf - Relevant personnel from Ideal Auto and Tsinghua University. Join our knowledge platform to download a vast amount of first-hand information in the automotive industry, including the above reference materials.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?