A Comprehensive Discussion on Autonomous Driving Cameras
 05/06 2025
05/06 2025
 795
795
Cameras in autonomous vehicles constitute a vital component of the perception module. Their low cost, high resolution, and ability to capture rich semantic information render them indispensable for tasks such as lane recognition, obstacle detection, and traffic sign and signal light identification. Various types of cameras—monocular, binocular, surround-view fisheye, and infrared—each have their unique strengths in terms of field of view (FOV) and depth estimation methods. Core design indicators for cameras include high resolution, high frame rate, wide dynamic range, and low-light performance.
Processing camera data necessitates multi-level algorithmic treatments, including distortion correction, image enhancement, object detection, depth estimation, and bird's-eye view (BEV) reprojection, to furnish reliable information for the decision-making layer. Precise internal and external parameter calibration, along with microsecond-level clock synchronization, is crucial for ensuring the seamless coordination of multiple cameras. Current cameras are prone to missed and false detections in adverse conditions like rain, snow, backlight, and long-tail scenarios, thereby imposing stringent demands on computing power and power consumption.
The Role and Significance of Cameras in Autonomous Driving
Cameras are celebrated as the "eyes of vision" in autonomous driving systems, capable of capturing high-level semantic information such as colors, textures, and text, which active sensors like radars and LiDARs cannot directly provide. For instance, the status of traffic lights (red or green) and the text content of road signs require precise recognition based on the high-resolution images captured by cameras. In comparison to the high cost of LiDARs and the limitations of millimeter-wave radars in detecting low-reflectivity targets, camera solutions offer natural advantages in cost-effectiveness and detail capture, making them widely utilized in key perception tasks like lane recognition, traffic sign detection, and pedestrian and vehicle classification. With the aid of deep learning algorithms, visual perception has swiftly evolved from traditional feature-based methods to end-to-end neural networks, providing a more detailed environmental understanding for autonomous driving decisions.
Mass-produced autonomous driving solutions typically integrate multiple cameras to compensate for the limitations of single-viewpoint and depth estimation. Forward-facing monocular cameras, owing to their simple structure and low cost, are frequently employed for long-distance target detection, estimating depth through inter-frame motion or structured light algorithms. Conversely, binocular cameras directly generate depth maps using the parallax between left and right lenses, making them suitable for detecting obstacles at medium to close distances but necessitating higher camera calibration accuracy. In parking and low-speed maneuvering scenarios, surround-view fisheye cameras offer close-range panoramic monitoring with an ultra-wide FOV of 180°–190°, enabling drivers to obtain a bird's-eye view around the vehicle. To enhance imaging quality in low-light environments, many systems integrate infrared or near-infrared illumination modules with traditional RGB cameras, making nighttime pedestrian detection and animal warning more reliable.
Analysis of Key Camera Technologies
When designing a camera system, resolution, frame rate, field of view (FOV), dynamic range, and light sensitivity are the five most crucial indicators. High resolution (e.g., 8MP and above) enhances the accuracy of long-distance target detection but also brings about greater data bandwidth and computational pressure, necessitating a balance between resolution and real-time performance. Camera frame rates are typically set at 30–60 fps to ensure smooth motion capture and timely environmental feedback. Wide dynamic range (HDR) technology preserves more details in scenes with both bright light and shadows, which is essential for complex scenarios such as entering tunnels or driving against the light. Moreover, low-light noise design based on back-illuminated CMOS sensors and LED flicker suppression technology significantly improves image quality in rainy and nighttime low-light conditions.
The images captured by cameras undergo rigorous algorithmic processing. Distortion correction using calibration parameters rectifies geometric distortions from fisheye or ultra-wide-angle lenses to real-world scales. HDR synthesis, rain/snow removal, and temporal denoising algorithms enhance image contrast and clarity to cope with extreme weather disturbances. Deep learning models (e.g., YOLO, Mask R-CNN, SegNet) perform object detection and semantic segmentation, combined with optical flow or multi-view structured light algorithms to estimate depth and motion information, providing 3D scene elements for trajectory prediction and path planning. BEV reprojection technology maps data from multiple cameras to a top-down plane, generating a panoramic environmental map for path optimization and obstacle avoidance planning by the decision-making layer.
Multi-camera systems have exceptionally high precision requirements for calibration and synchronization. Internal parameter calibration (focal length, principal point, distortion coefficients) and external parameter calibration (camera position and orientation in the vehicle coordinate system) are typically performed offline using chessboard calibration boards or scenes and require periodic re-inspection to mitigate drifts caused by temperature changes and vehicle body vibrations. To avoid motion artifacts resulting from timing inconsistencies across multiple image frames, cameras must be triggered synchronously at the microsecond or sub-millisecond level to ensure simultaneous data capture across all channels, enabling seamless image stitching and fusion. In advanced systems, timestamps and coordinate transformations are also shared with sensors such as radars, LiDARs, and IMUs to achieve true spatial-temporal alignment.
What Are the Drawbacks of Cameras?
Cameras present several challenges in autonomous driving applications. Variations in lighting and weather conditions (rain, snow, fog, backlight) can cause image blur, reduced contrast, and increased noise, leading to an increased risk of missed and false detections. "Long-tail" scenarios (rare traffic signs, special obstacles, emergencies) are difficult to fully cover in limited training data, and deep learning models often perform poorly in these extreme cases, necessitating the integration of large-scale simulations and online learning to improve robustness. High-resolution, high-frame-rate video streams impose stringent demands on the computational power and power consumption of in-vehicle computing platforms, particularly impacting the range of electric vehicles, prompting chip manufacturers (such as NVIDIA Drive, Mobileye EyeQ, Tesla FSD chips) to continuously optimize hardware architecture and power management.
To address these issues, solutions have been proposed that combine end-to-end deep learning with self-supervised pre-training, leveraging unlabeled big data to enhance model generalization in extreme scenarios. Furthermore, the fusion of multimodal information from low-cost solid-state radars, LiDARs, or high-definition maps provides necessary redundancy and priors for purely visual solutions. During vehicle operation, online calibration and intelligent alignment technologies are employed to dynamically correct calibration parameters, reducing the impact of environmental changes on perception accuracy.
Future Trends in Autonomous Driving Cameras
In the future, autonomous driving vehicle cameras may exhibit the following trends. Firstly, higher-performance embedded computing platforms will continuously improve visual inference efficiency and energy efficiency, enabling a better balance between high-resolution, high-frame-rate algorithms, real-time performance, and power consumption. Secondly, end-to-end neural networks and self-supervised learning technologies will further enhance the model's adaptability to rare scenarios, reducing the dependence on manual annotation. Multimodal fusion will remain the mainstream approach, achieving comprehensive redundant perception of complex environments through deep collaboration with LiDARs, millimeter-wave radars, and high-definition maps. Additionally, online intelligent calibration and reconfigurable optical module technologies will become pivotal in enhancing long-term system stability and maintenance convenience, laying a solid foundation for large-scale commercial deployment.
-- END --
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
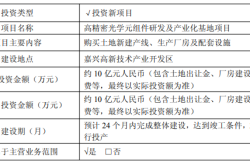
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?