Multi-modal 2025: A Clash of Titans in Technical Routes, Video Generation Soars to New Heights
 06/11 2025
06/11 2025
 658
658

A conference that convenes half of China's multi-modal large model experts.
During the two-day forum of the BAAI Conference 2025, prominent participants from academia, startups, and major tech companies gathered, pushing the focused discussion on multi-modality to unprecedented heights. Founders and CEOs from six startups—Aishi Technology, Shengshu Technology, Sand.ai, Zhixiang Future, Luma AI, and Zhipu—shared their insights. Leaders in multi-modal technology from tech giants like ByteDance, Tencent, and Baidu, along with relevant experts and scholars from Renmin University and MIT, were also present.
Autoregressive, diffusion, native multi-modality... Discussions and practical sharing centered around various technical routes all underscore one point: Compared to the solitary battlefield of large language models, the technical routes for multi-modal large models are far from converging.
"Multi-modal large models have been deployed in specific scenarios, but have yet to achieve a high degree of universality," said Wang Zhongyuan, president of the BAAI. He emphasized that fundamental breakthroughs still hinge on more powerful foundation models. If multi-modal models reach a sufficiently usable level, they will propel further industrial development.
Among the various gaps, multi-modality still has a long way to go before opening the gate to the second half.
Multi-modality has yet to usher in its "ChatGPT moment."
"For multi-modal models, it's still too early to define the second half. We haven't even glimpsed the boundaries of the first half yet," said Zhang Zheng, co-founder of Sand.ai, when asked about his perspective on the second half of large models.
The "slow-paced" development of multi-modal large models limits the performance capabilities of the application side. Taking video generation as an example, Mei Tao, CEO of Zhixiang Future, pointed out that current video generation is still at a stage between GPT-2 and GPT-3. He summarized the three elements of video creation as narrativity, stability, and controllability.
Narrativity ensures that the video "tells a complete story, whether it's 5 minutes or 1 hour," maintaining IP consistency. In terms of stability, it's necessary to ensure the stability of image quality, motion coherence, temporal consistency, etc., and current performance is relatively good. Controllability measures the accuracy of video content generation, with high demands for what shots appear at what second and what expressions characters make. However, today's large models cannot yet reach such a level.
At this stage, to enhance the model generation effect, data quality becomes crucial.
"The reason why we see Google's Veo 3 and many other models performing well and realistically is that, if everyone converges on the model architecture, the real competition actually hinges on high-quality data," said Mei Tao, CEO of Zhixiang Future. "In fact, we haven't produced so-called new intelligence; we're just replicating the world we see."

Google Veo 3 model demonstration
Regarding how to bolster the capabilities of multi-modal large models, the technical routes pursued by various companies differ.
Compared to the fields of text-to-image and text-to-video, which generally adopt the Diffusion Transformer (Dit, or diffusion Transformer) model, there's no consensus within the industry on whether multi-modal large models should adopt autoregressive models, diffusion models, or other methods.
At the conference, Cao Yue, CEO of Sand.ai, shared his thoughts on the issues brought about by diffusion models:
"At the technical level, there are still significant problems with the mainstream training schemes for Diffusion and Transformer. The core issue lies in insufficient scalability," said Cao Yue. "On the Diffusion Transformer path, it has now been proven that generating 5-second videos can yield good results, but as the model scale increases, it will quickly reach a bottleneck."
Even when the generation mechanisms are consistent, differences in model architecture and training methods also impact the model generation effect.
In Song Jiaming's view, the prerequisite for multi-modal large models to enter the second half is that the first half must first unify the processing of different modalities like language, both using the same model for modeling and ensuring that inference is fast enough.
The question is whether to train multiple modalities by concatenating them or to adopt a unified architecture from the outset and unify the training of information from various modalities. This distinguishes between the multi-modality and "native multi-modality" routes.
"The current learning path for multi-modal large models, especially multi-modal understanding models, typically involves first training the language model to a high level of proficiency and then learning other modal information," said Wang Zhongyuan. "It's like first achieving a doctoral degree level before exposing oneself to other knowledge."
However, during the above process, the model's capabilities may decline. In Wang Zhongyuan's words, the model's capabilities may drop from a "doctorate" level to a "university" or even "high school" level.
To address this issue, the BAAI launched Emu3, the world's first native multi-modal large model, as early as October last year, attempting to unify data from multiple modalities within a single architecture.
As a native multi-modal model, Emu3 adopts an autoregressive generation method, unifying multi-modal learning based on the next token prediction paradigm. By developing a new visual tokenizer, it encodes images/videos into discrete symbol sequences that are isomorphic to text, constructing a modality-independent unified representation space to enable the arbitrary combination, understanding, and generation of text, images, and videos.
In other words, you can freely throw text, speech, and video at Emu3 for processing, and it can also generate content in these three forms, enabling cross-modal interaction.
Expanding the form of multi-modal data is also crucial for accessing the second half of multi-modal large models. Li Tianhong, a postdoctoral researcher in the He Kaiming group at MIT CSAIL, believes that the true "second half" of multi-modality should involve models capable of processing data beyond human senses.
At the conference, the BAAI also shared an expansion of multi-modal data forms beyond images, text, sound, and video: brain signals.
"Brain signal data is the first attempt," said Wang Zhongyuan. "There are more modalities in embodied domain data, such as 3D signals, spatio-temporal signals, etc., which can all be fused as a modality."
It can be said that building native multi-modal large models is costly and technically challenging, making it a risky endeavor for companies focused on deployment speed. As a research institution, the BAAI is paving the way for the industry.
Inflection point for multi-modal generation deployment, video models accelerate commercial competition
While academia and industry explore technical paths, companies are accelerating the deployment process of multi-modal large models in the industry. This is a defining feature of China's AI development—commercialization and model development proceed hand in hand.
Huang Weilin, head of image & video generation at ByteDance Seed, provided two sets of data to confirm: 2025 is the first year of image generation commercialization.
"Taking efficiency data as an example, the download rate for users generating 100 images has tripled over the past year, now reaching over 60%, indicating that it has crossed the critical threshold for commercialization," said Huang Weilin. "In terms of user retention, such as 30-day retention, it has increased from the original ten percentage points to around 40%."
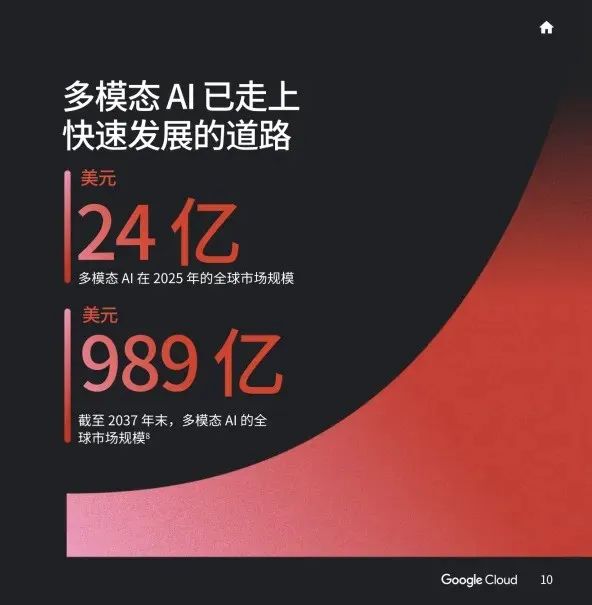
Google's estimate of the multi-modal market size
As technical barriers gradually decrease and cost efficiency meets requirements, AI video generation has also ushered in a golden period of market growth.
Huang Weilin said that the annualized revenue (ARR) of current leading video generation products is expected to reach $100 million this year and may grow to $500 million to $1 billion next year.
Luo Yihang, CEO of Shengshu Technology, also believes that this year marks the inflection point for the large-scale production deployment of multi-modal generation: with rapid technological iteration and improvements in effectiveness, speed, and cost, industry demand is growing vigorously, and the pace of deployment in video-related industries is also accelerating.
Although the current large model technical routes are not converging, at the current stage of application deployment, AI video production is already capable of assisting humans in completing shooting requirements that are time-consuming, labor-intensive, and costly, while compressing the generation time to an extremely low level.
Zhang Zheng believes that AI video generation will have completely different product-market fits (PMFs) at different stages of development.
For example, in the early stages, many videos that are extremely difficult for humans to shoot, even if the quality is poor or requires a large number of attempts to obtain, still cost several orders of magnitude less than setting up a scene and shooting content.
Zhang Zheng gave an example, such as shooting an aircraft carrier in space, which requires a special effects team to work frame by frame. But now, by using the model, even if it requires 100 attempts and costs 500 yuan to obtain a clip, this cost is still much lower than before.
In a myriad of application scenarios, China's multi-modal large model companies have offered different answers regarding which commercialization route to take first, focusing on the B-end or C-end market.
At this stage, a prominent example of AI video applications in the C-end market is AI video special effects relying on video generation.
Having provided AI video technology support for the TikTok team, Wang Changhu, founder of Aishi Technology, shared that the breakthrough milestone for their product PixVerse came from the launch of special effects templates.
According to Wang Changhu, through the spread of special effects video templates on Douyin and various social media platforms at home and abroad, PixVerse gained popularity. That month, PixVerse ranked second on China's product overseas growth chart, with an 80% increase in visits. He also shared an impressive data point—in April this year, the only AI product with more monthly active user (MAU) growth than PixVerse was DeepSeek.
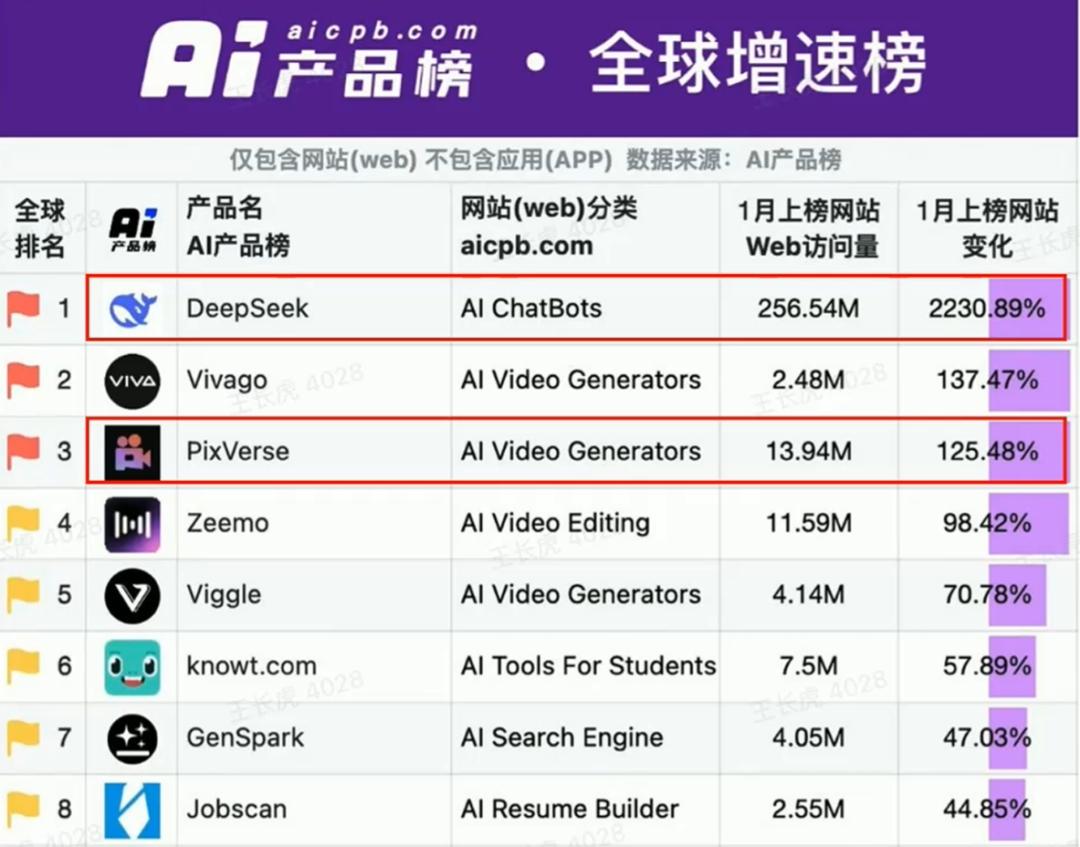
While technology is rapidly iterating, Aishi Technology has made its own choice in commercialization—focusing on the C-end market first and then the B-end market. Relying on the popularity gained from the C-end market, Aishi Technology expanded its territory to the B-end market this year, supporting APIs and customized video generation for various industries, including the internet, marketing, e-commerce, etc., starting in January this year.
In contrast, Shengshu Technology focused earlier on how to deploy video generation large models in the industrial sector. In the two years since its establishment, Shengshu Technology has spent a year and a half pondering deployment issues. Regarding industry segmentation, Luo Yihang presented a blueprint of "eight major industries and thirty major scenarios," among which the internet, advertising, movies, and animation account for 80% of applications.
In considering how to penetrate the B-end market, Shengshu Technology emphasizes reducing costs and improving production efficiency.
"To meet technical requirements, it's crucial that (AI video generation) production efficiency be increased 100-fold and production costs be reduced 100-fold. It's necessary to deeply adapt to the industry and meet its professional needs," said Luo Yihang.
Luo Yihang shared that an overseas animation studio cooperated with VIDU to create an "AI animation" workflow capable of generating creativity in batches. They produced 50 episodes of AI animation shorts in two months.
When efficiency and generation reach nodes that satisfy commercial use, and AI companies successively put commercialization on the agenda, it's foreseeable that in the second half of the year, AI generation in the multi-modal field will witness more intense competition in commercialization.
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




