Comprehending Visual Language Action (VLA) Models and Their Diverse Applications
 06/12 2025
06/12 2025
 582
582
VLA stands as one of the most talked-about AI terms at the forefront of autonomous driving and robotics. Our earlier article, "2025: The Imminent 'Revolution' of End-to-End Large Models 2.0 for Autonomous Driving - VLA (Vision Language Action)", predicted it as the Large Model 2.0 for autonomous driving.  Li Auto's VLA is expected to soon be implemented in vehicles, and Xpeng has announced that its next-generation Turing chip models will adopt VLA. Essentially, all models utilizing NVIDIA's Thor chips with over 500 Tops of computing power will shift to the VLA algorithm concept. This article delves into why VLA is significant, its structure, origins, research and application landscapes, and its current state in autonomous driving, both domestically and internationally.
Li Auto's VLA is expected to soon be implemented in vehicles, and Xpeng has announced that its next-generation Turing chip models will adopt VLA. Essentially, all models utilizing NVIDIA's Thor chips with over 500 Tops of computing power will shift to the VLA algorithm concept. This article delves into why VLA is significant, its structure, origins, research and application landscapes, and its current state in autonomous driving, both domestically and internationally.
1. The Significance of VLA
Despite its high computational power requirement, VLA boasts numerous advantages. 
- Improved Data Efficiency through Pre-training: VLA models can be pre-trained on extensive internet or simulation datasets using vision-language pairs (e.g., images and captions or instructional videos), reducing reliance on task-specific data. For instance, in autonomous driving, pre-training VLA can guide functions, enabling it to generalize well to downstream tasks with minimal fine-tuning.
- Enhanced Human-Instruction Interaction: VLA models, capable of understanding human language and recognizing human environments, can interpret and execute human instructions, like "turn left at the traffic light ahead" or "enter the parking lot ahead." This represents a shift from manually coded action strategies.
- Unified Training of End-to-End Large Models: Essentially, the VLA model integrates perception, task understanding, and control into a single module, performing joint inference on scenarios, objectives, and actions. This holistic approach enhances robustness and simplifies system design.
- Cross-domain and Cross-platform Generalization: The shared embedding space of vision and language allows a single model to transfer knowledge across tasks, objects, and robot instances, supporting the development of both cars and robots.
2. The Structure of VLA
Both autonomous driving and robotics require fusing visual and linguistic signals. Typically, VLA models encompass the following structures: 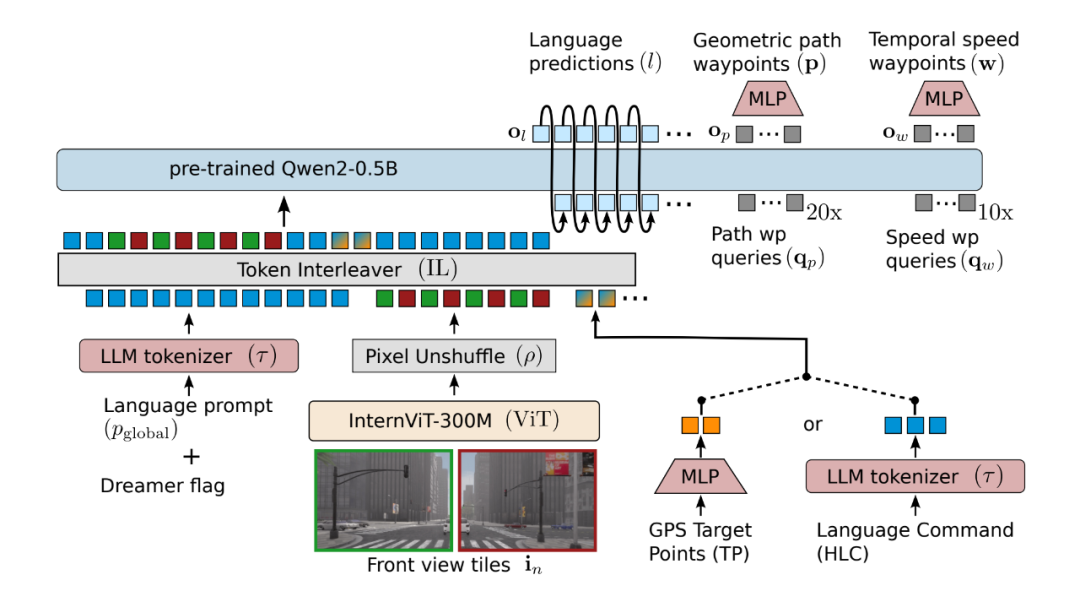
- Visual Encoder: Segments and classifies objects in the scene, converting pixels into conceptual tokens (e.g., CNN, ViT, CLIP).
- Language Model: Encodes instructions into high-dimensional embeddings (e.g., Deepseek, LLaMA-2, Alibaba's Qwen-category LLM, Transformer).
- Policy Modules or Planners: Enable vehicles to reason about high-level goals and translate them into low-level movements. These models often employ multimodal fusion techniques to align visual information with textual instructions.
3. The Origins of VLA
The VLA model concept emerged around 2021-2022, pioneered by projects like Google DeepMind's Robotic Transformer 2 (RT-2). The term VLA first appeared in the Google RT-2 paper, which used PaLI-X and PaLM-E as the backbone for "transforming pixels into actions." 
4. Research and Applications of VLA
VLA is progressing rapidly, particularly in the robotics industry due to lower costs of startup and experimentation. As of 2025, advanced VLA models adopt a two-tier expert system combining VLM and Diffusion decoders, mimicking Daniel Kahneman's dual-process theory. 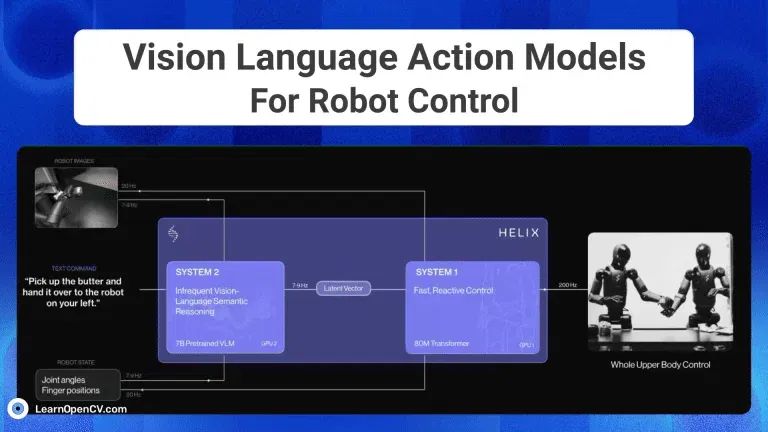
- Expert System 2 ("Slow Thinking"): The Visual Language Model (VLM) uses vision and text to make decisions about complex scenes, guiding the robot's overall behavior.
- Expert System 1 ("Fast Thinking"): The Transformer decoder or Diffusion model acts as an action expert for low-level control and dexterous motion.
Examples include Nvidia's Groot N1 and FigureAI's Helix, which adopt such strategies. 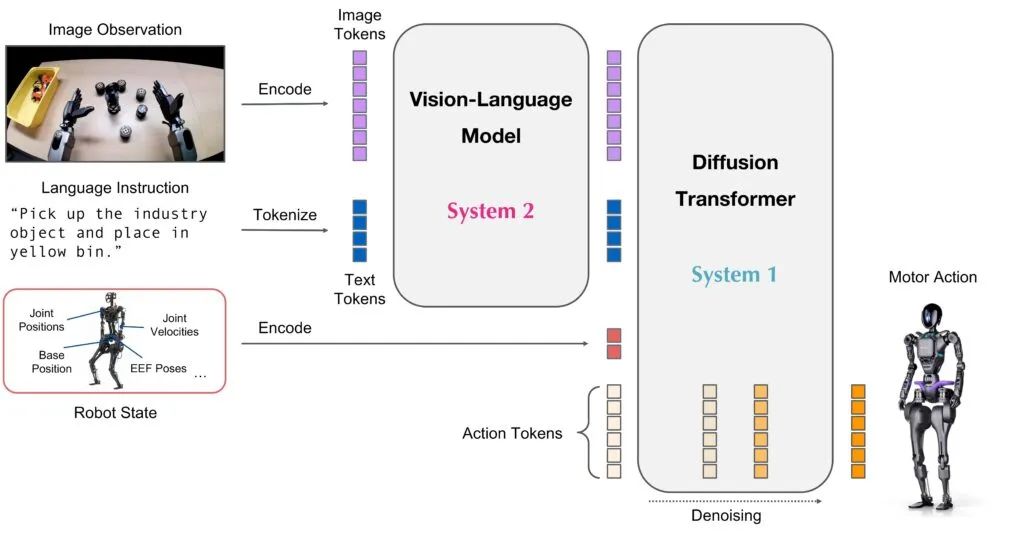
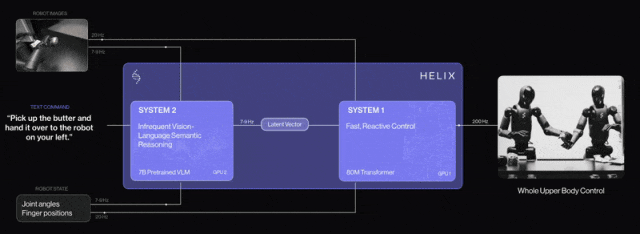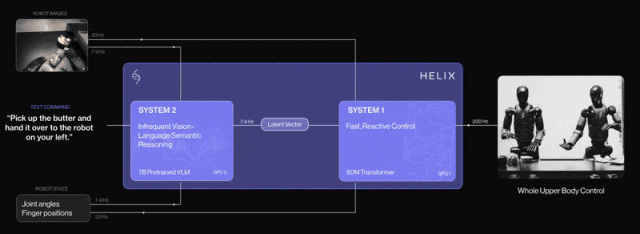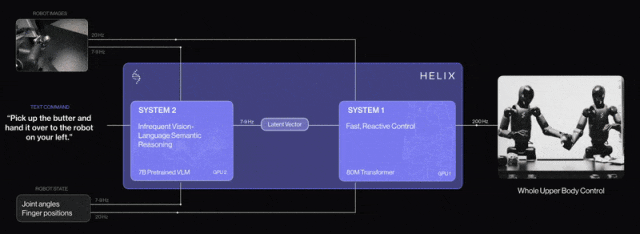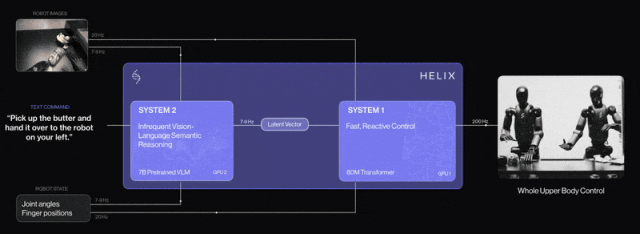
Other notable VLA models include OpenVLA, Google's Robotic Transformer (RT-2), and Physical Intelligence's π-introduced foundational VLA flow. 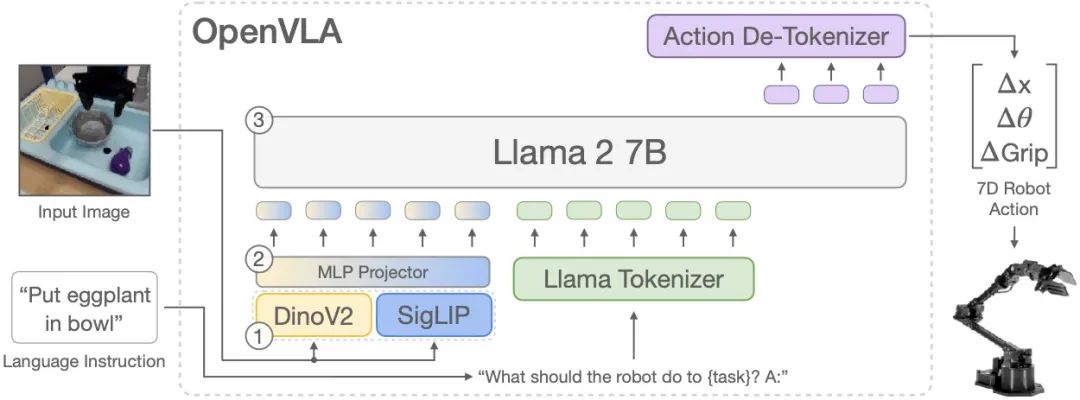
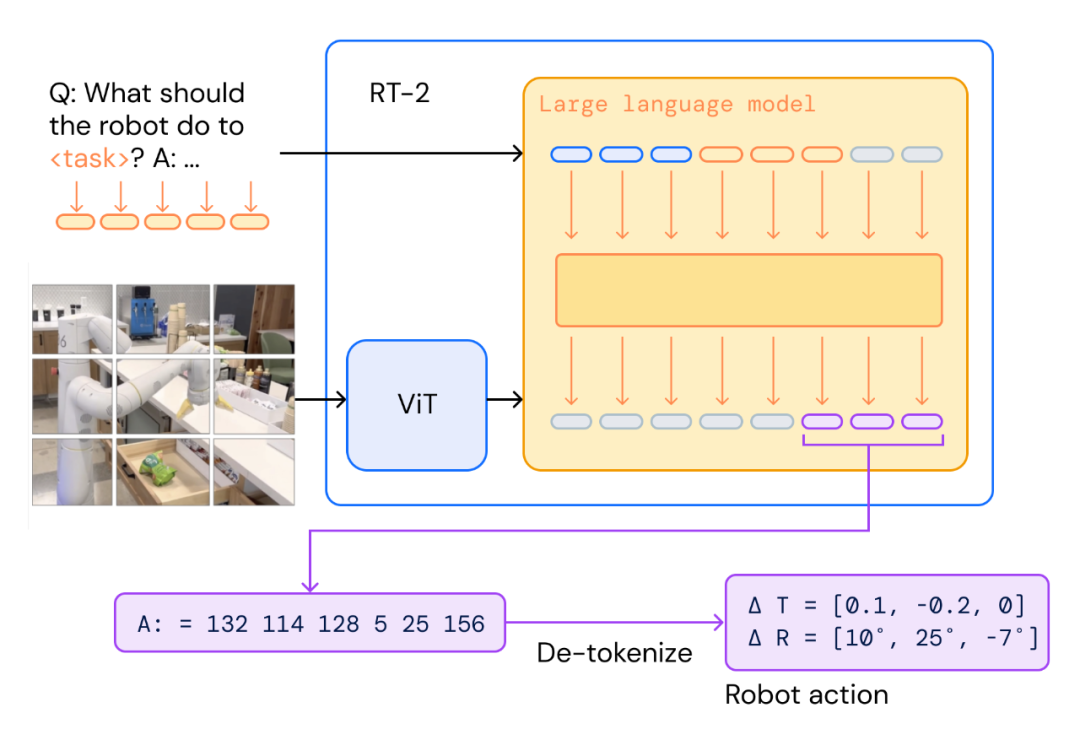
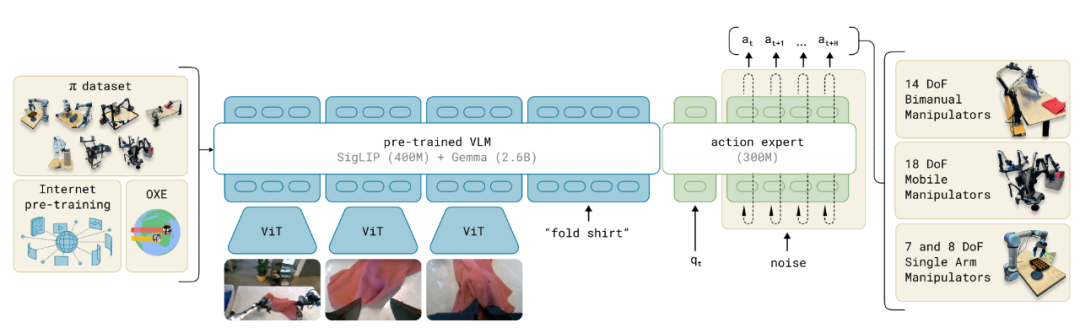
5. Current Application of VLA in Autonomous Driving
The earliest VLA application in intelligent automotive driving was by Wayve, a UK-based autonomous driving startup. Its LINGO-1 algorithm, introduced in September 2023, applied VLM to autonomous driving, generating commentaries to explain driving behaviors. By March 2024, Wayve released its VLA model, LINGO-2. 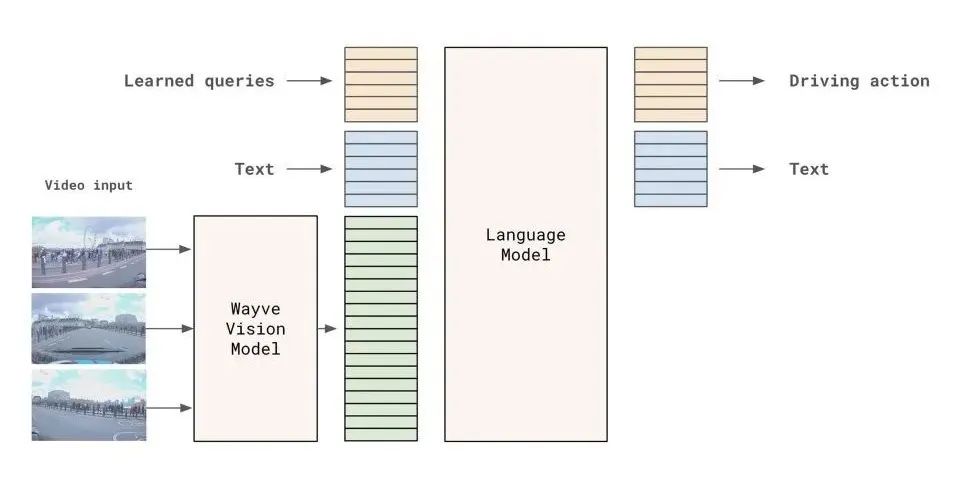
Wayve has partnered with Uber to deploy L4 robotaxi services in the US and UK, while Nissan will launch its next-generation ProPilot intelligent driving assistance system based on Wayve's technology in 2027. Google's Waymo also explored a VLA concept with its EMMA project, released in October 2024. 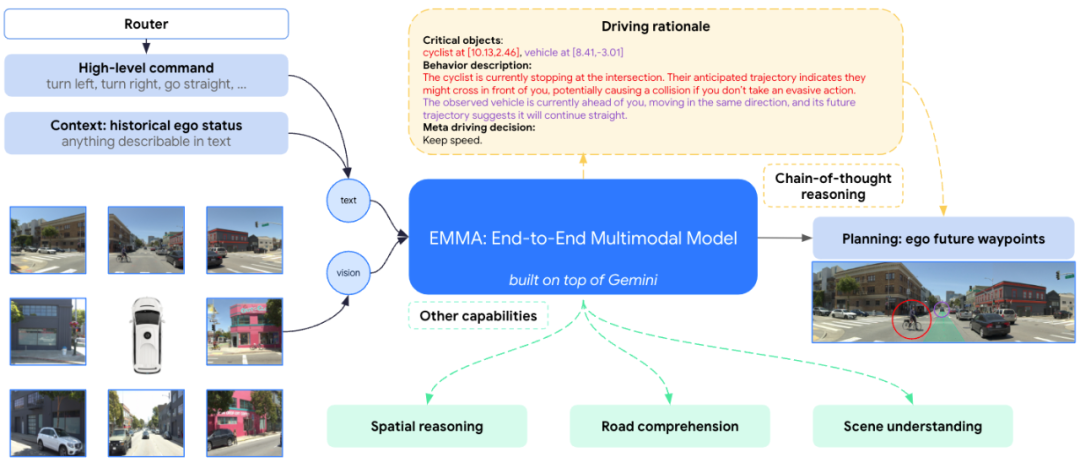
In China, Li Auto has been closely following this trend. Li Auto released its VLM paper around February 2024 and announced its integration into vehicles around July. By the end of the year, it began releasing VLA-related papers and will launch new intelligent driving assistance with VLA based on NVIDIA Thor and the dual Orin platform in July 2025. 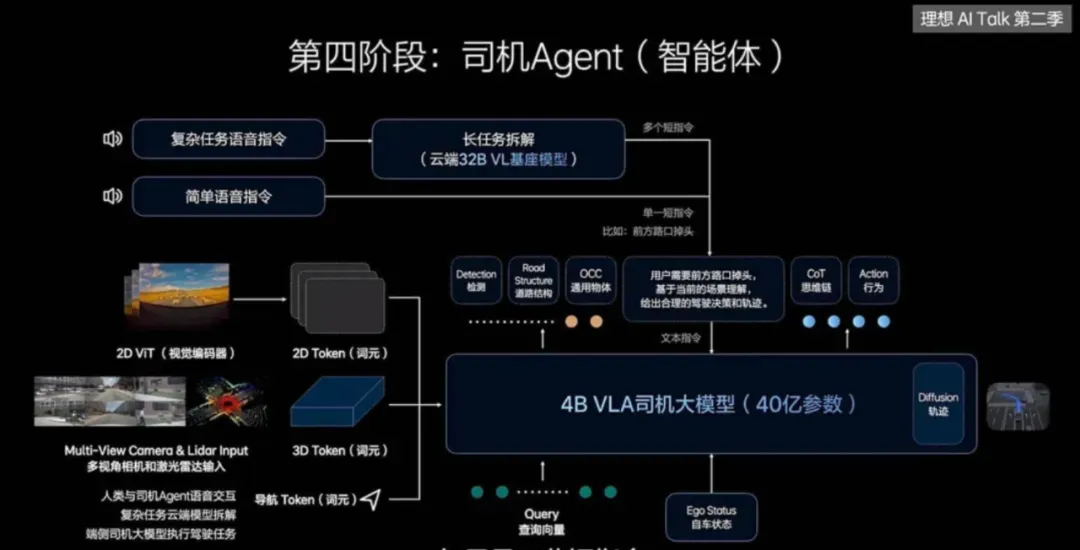
XPeng has clearly stated that its newly launched G7 model incorporates Visual-Linguistic Action (VLA), though the specific implementation details remain unclear. However, its unveiled 72 billion (72B) cloud algorithm architecture diagram reveals a cloud-based VLA structure that could potentially be refined into a vehicle-end VLA model tailored for onboard chips. At XPeng's G7 launch event on June 12, it was announced that the company's intelligent driving system utilizes three Turing chips, collectively boasting a computing power of 2200 Tops, to support a vehicle-end VLA+VLM architecture. Comparing this to Li Auto's VLA architecture, it appears that both companies are converging towards similar solutions, with the key difference being that Li Auto's VLM resides in the cloud, whereas XPeng, leveraging its high-performance chips, places the VLM on the vehicle side. 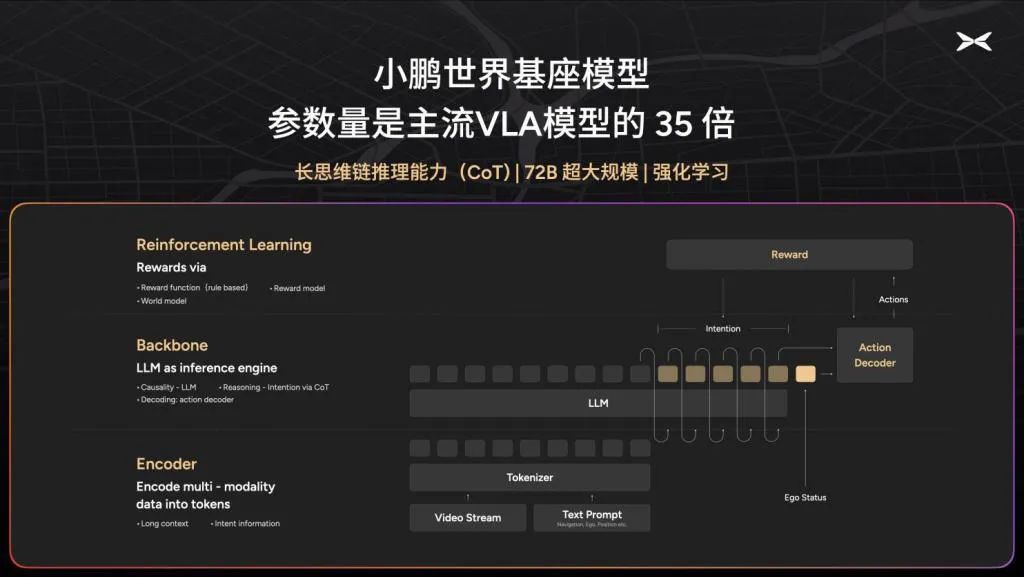
Earlier this year, Huawei released its ADS 4.0, which adopts the WEWA framework, showcasing Huawei's end-to-end capabilities. The WE World Engine applies the World Model to generate virtual verification scenarios. WA is presumably an end-to-end paradigm, and currently, Huawei lacks chips capable of running VLA. 
6. Conclusion: VLA integrates visual and linguistic information, essentially mimicking human behavior, as humans interact with the physical world in a similar manner. Consequently, VLA is inherently designed to address Physical AI, with autonomous driving and robotics being its largest application domains. The logic of AI algorithms, energy storage, and core components like motion motors are analogous in both industries. As a result, companies developing intelligent vehicles often venture into humanoid robots as well. This begs the question: Does VLA need to be self-developed? In reality, at least the Large Language Model (LLM) within it does not necessitate in-house development. An LLM is a fundamental component of AI, and there's no need to reinvent the wheel. Currently, foreign autonomous driving and robotics companies predominantly utilize LLMs from OpenAI, Meta, and Google. Domestically, Li Auto and XPeng likely employ Deepseek or Alibaba's Qwen. Ultimately, all parties employ AI models to integrate with their VLA for practical applications. Nevertheless, it's crucial to note that advanced technology does not always equate to a superior product experience.
Reference Articles and Images:
SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment - wayve
ZERO-SHOT ROBOTIC MANIPULATION WITH PRETRAINED IMAGE-EDITING DIFFUSION MODELS - University of California, Berkeley; Stanford University; Google DeepMind
π0: A Vision-Language-Action Flow Model for General Robot Control - Physical Intelligence
ORION: An End-to-End Autonomous Driving Framework Based on Vision-Language Guided Action Generation - Huazhong University of Science and Technology; Xiaomi EV
HybridVLA: Unified Diffusion and Autoregressive in Vision-Language-Action Models.pdf - State Key Laboratory of Multimedia Information Processing, School of Computer Science, Peking University; Beijing Academy of Artificial Intelligence (BAAI); CUHK
Vision-Language-Action Models: Concepts, Progress, Applications, and Challenges.pdf - Cornell University, Biological & Environmental Engineering, Ithaca, New York, USA; The Hong Kong University of Science and Technology, Department of Computer Science and Engineering, Hong Kong; University of the Peloponnese, Department of Informatics and Telecommunications, Greece
A Comprehensive Review of Global Autonomous Driving Models - Tuo Feng, Wenguan Wang, Senior Member, IEEE; Yang Yi, Senior Member, IEEE
*Reproduction and excerpts are strictly prohibited without permission - For access to the references of this article:
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




