What is VLA in Autonomous Driving?
 06/18 2025
06/18 2025
 670
670
With the advent of autonomous driving technology, numerous technologies from other fields have been adapted and integrated into this burgeoning industry, among which VLA stands out. Especially with the rise of end-to-end large models, the utilization of VLA in autonomous driving has become increasingly prevalent. So, what exactly is VLA, and what role does it play in the autonomous driving sector?
VLA stands for "Vision-Language-Action," a vision-language-action model that fundamentally integrates visual perception, language understanding, and action decision-making into a unified large model. This approach allows for a seamless process from environmental observation to control command output, unlike the modular division of perception, planning, and control in traditional autonomous driving systems. The VLA model leverages large-scale data-driven methods to establish a closed-loop mapping of "image input to command output," potentially enhancing the system's generalization capability and scene adaptability significantly.
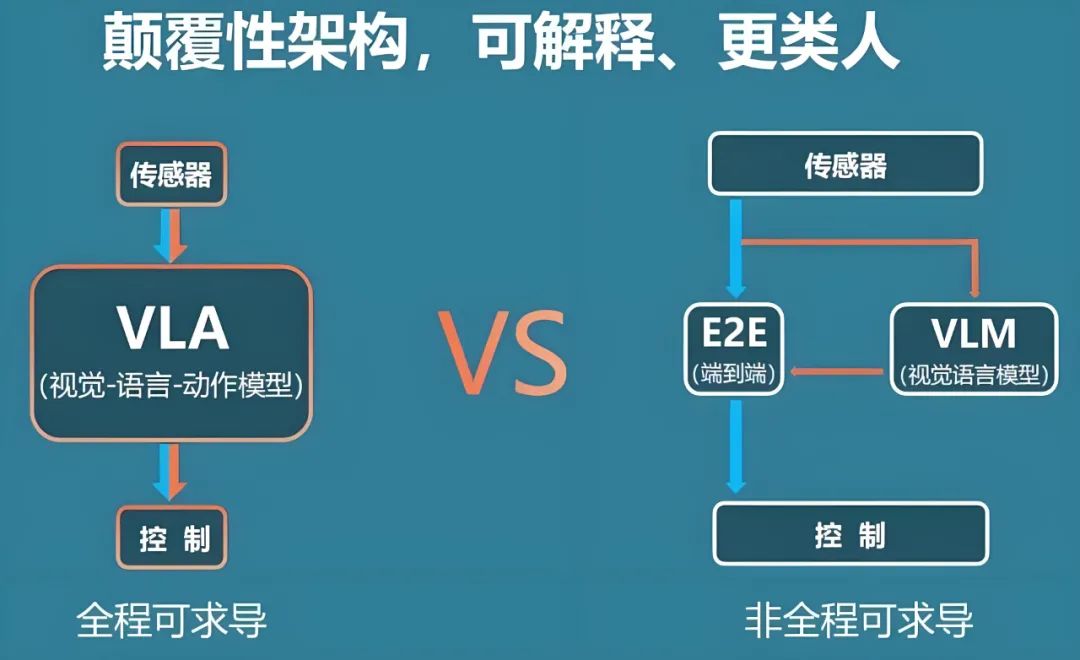
VLA was first introduced by Google DeepMind in the field of robotics in 2023, aiming to address the coordination challenges among "vision, language, and action" in agent control. DeepMind's initial VLA model directly maps camera images and text commands to physical actions through the integration of visual encoders, language encoders, and action decoders. This technology has not only revolutionized robot manipulation but also introduced a novel end-to-end approach to intelligent driving scenarios.
In autonomous driving, perception technology typically relies on various sensors like radar, lidar, and cameras. The perception data undergoes processing through modules such as object detection, semantic segmentation, trajectory prediction, and behavior planning, culminating in the controller issuing commands like steering and throttle adjustments. While this process is logical and clear, it suffers from shortcomings like error accumulation between modules, complex rule design, and the challenge of covering all extreme scenarios. Against this backdrop, the VLA model emerged, discarding intermediate manually designed algorithms and directly utilizing a unified neural network to learn the optimal control strategy from multimodal inputs. This approach simplifies the system architecture and enhances data utilization efficiency.
The VLA model typically comprises four key modules: the visual encoder, the language encoder, the cross-modal fusion layer, and the action decoder or policy module. The visual encoder extracts features from images and point cloud data collected by sensors like cameras or lidars. The language encoder comprehends navigation commands, traffic rules, or high-level strategies through large-scale pre-trained language models. The cross-modal fusion layer aligns and integrates visual and language features to create a unified environmental understanding. Finally, the action decoder or policy module generates specific control commands, such as steering angles and acceleration/deceleration instructions, based on the fused multimodal representations.
In the visual encoder component, the VLA model often employs convolutional neural networks or large vision models (Vision Transformer) to extract deep features from raw pixel data. To enhance the understanding of three-dimensional scenes, some studies introduce three-dimensional spatial encoders to map multi-view images or point clouds into a unified three-dimensional feature space. These technologies enable VLA to outperform traditional methods in handling complex road environments, pedestrian recognition, and object tracking.

The language encoder is the most notable difference between VLA and traditional end-to-end driving models. By accessing large-scale pre-trained language models, VLA can comprehend natural language navigation commands (e.g., "turn right at the second traffic light ahead") or high-level safety strategies (e.g., "always slow down to below 5 km/h when pedestrians are detected") and integrate these understandings into the decision-making process. This cross-modal understanding capability not only bolsters the system's flexibility but also opens new avenues for human-vehicle interaction.
The cross-modal fusion layer serves as the "glue" in VLA, necessitating the design of efficient alignment algorithms to facilitate the interaction between visual and language features within the same semantic space. Some solutions utilize the self-attention mechanism to achieve deep feature fusion, while others combine graph neural networks or Transformer structures for multimodal alignment. These methods aim to construct a unified representation to support more accurate action generation subsequently.
The action decoder or policy module is typically trained using reinforcement learning or supervised learning frameworks. VLA employs fused multimodal features to directly predict continuous control signals, including steering angles, acceleration, and braking pressure. This process eliminates the complex rule engine and multi-stage optimization of traditional schemes, enabling the entire system to achieve superior global performance through end-to-end training. However, it also poses challenges like reduced interpretability and increased difficulty in safety verification.
The VLA model's primary strength lies in its robust scene generalization and contextual reasoning capabilities. Since the model learns rich multimodal associations from large-scale real or simulated data, it can make quicker and more reasonable decisions in complex intersections, low-light environments, or when unexpected obstacles arise. Moreover, by incorporating language understanding, VLA can flexibly adjust driving strategies based on commands, fostering a more natural human-machine collaborative driving experience.
Several domestic and international companies have begun applying the VLA concept to intelligent driving research and development. DeepMind's RT-2 model demonstrates the potential of end-to-end vision-language-action fusion in robot control, while Metaron's publicly proposed VLA model has been dubbed the "End-to-End 2.0 Version" by its CEO Zhou Guang, who asserts that "after this system is deployed, intelligent driving in urban areas can truly achieve a usable state." ZhiPingFang's GOVLA model in robotics also showcases advanced capabilities in whole-body coordination and long-range reasoning, providing a new benchmark for future intelligent driving.
While VLA presents new possibilities for the autonomous driving industry, practical applications still confront numerous challenges. Firstly, the model's lack of interpretability makes it challenging to systematically troubleshoot decision-making errors in edge scenarios, complicating safety verification. Secondly, end-to-end training demands high-quality and extensive data, necessitating the development of a high-fidelity simulation environment encompassing various traffic scenarios. Additionally, high computational resource consumption and the difficulty of real-time optimization are technical hurdles that must be overcome for VLA's commercialization.
To address these issues, various technical pathways are being explored. For instance, introducing interpretability modules or posterior visualization tools to transparentize the decision-making process, utilizing Diffusion models to optimize trajectory generation to ensure smooth and stable control commands. Simultaneously, combining VLA with traditional rule engines or model predictive control (MPC) to enhance safety redundancy and system robustness through a hybrid architecture has also gained popularity.
Looking ahead, with continuous advancements in large model technology, edge computing, and in-vehicle hardware, VLA is poised to play a pivotal role in the field of autonomous driving. It can not only offer more intelligent driving solutions for complex urban roads but also extend to various application scenarios such as fleet coordination, remote control, and human-machine interaction. ZhiJiaZuiQianYan believes that the integration of "vision, language, and action" will become the mainstream direction of autonomous driving technology, ushering in a new "End-to-End 2.0" era of intelligent travel.
As an end-to-end multimodal fusion solution, VLA bolsters the autonomous driving system's generalization capability and interactive flexibility by integrating vision, language, and action into a single model. While challenges like interpretability, safety verification, and computational power optimization remain, its revolutionary technical framework undoubtedly charts the course for the future development of intelligent driving. As the industry accumulates practical experience, optimizes algorithms, and refines safety systems, VLA is expected to emerge as the "next-generation technology cornerstone" in autonomous driving.
-- END --
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




