Google's Embodied Intelligence VLA Large Models - Gemini Robotics: Bringing AI into the Physical World
 06/25 2025
06/25 2025
 604
604
Introduction
Truly practical robots need to understand the surrounding physical world and interact with it in a reliable and safe manner. That is to say, AI agents based on physical entities must possess robust human-level embodied reasoning abilities, which encompass a world knowledge system of basic concepts required for operation and functioning in a physically embodied world.
As humans, we often take embodied reasoning abilities for granted - such as perceiving the 3D structure of the environment, analyzing complex inter-object relationships, and intuitively understanding physical laws - but these abilities are the cornerstone of embodied AI agents.
Furthermore, embodied AI agents must break through the limitations of passively understanding spatial and physical concepts in the real world, directly impacting the external environment through action, thereby bridging the gap between passive perception and active physical interaction.
With innovations in robotic hardware, there is a historic opportunity to build embodied AI agents capable of performing highly dexterous tasks. On March 12, 2025, Google DeepMind released two large models built on the multimodal general large model Gemini 2.0: Gemini Robotics (VLA) and Gemini Robotics-ER (VLM).
Gemini Robotics and Gemini Robotics-ER
1. Gemini Robotics-ER
Gemini Robotics - ER (VLM model), where ER stands for "embodied reasoning", extends Gemini's multimodal reasoning capabilities to the physical world, possessing enhanced spatial and temporal understanding abilities, including 2D spatial concept understanding capabilities such as object detection, pointing, trajectory prediction, and grasp prediction, as well as 3D spatial reasoning abilities such as multi-view 3D scene understanding and 3D bounding box detection.

Multi-view 3D scene understanding: Understanding 3D scenes by correlating 2D points from different views
1) Supports zero-shot and few-shot robot control
In the paper, researchers used two types of models, Gemini 2.0 Flash and Gemini Robotics-ER, to conduct experiments using two different robot control methods.
Zero-shot robot control - Controlling robots through code generation.
Few-shot control - Through in-context learning (ICL), adapting to new behaviors based on a small number of examples.
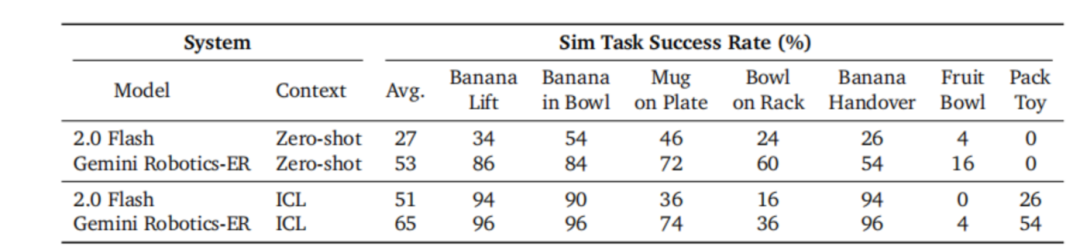
Comparison of results for two types of models performing a set of manipulation tasks in a simulated environment
Note: These tasks cover different difficulties and object types, from simple grasping tasks (like lifting a banana) to long-sequence, multi-step, multi-task operations (like putting a toy in a box and closing it).
Experimental results show that Gemini Robotics-ER performs well in task completion rates under both control methods. Gemini Robotics-ER can utilize in-context learning to improve the execution of more complex dexterous dual-arm tasks (like folding clothes) with only a few examples and can directly output the end-effector trajectory to complete tasks.
In terms of zero-shot robot control, the task completion rate of Gemini Robotics-ER is nearly double that of Gemini 2.0.
In terms of few-shot robot control, Gemini 2.0 Flash achieves an average success rate of 51% in a simulated environment. However, Gemini Robotics-ER achieves an average success rate of 65% in a simulated environment.
Additionally, experiments also show a strong correlation between the model's embodied reasoning ability and the performance of downstream robot control. Gemini Robotics-ER can be directly used for robot control, including as a perception module (like object detection), a planning module (like trajectory generation), and coordinating robot movements by generating and executing code.
However, as a VLM model, Gemini Robotics-ER also has limitations, especially in more complex dexterous manipulation tasks. This is mainly because additional intermediate steps are required to associate the model's embodied reasoning abilities with robot execution actions.
2. Gemini Robotics
Gemini Robotics is an end-to-end VLA (Vision-Language-Action) model that combines powerful embodied reasoning priors with dexterous low-level control of real-world robots, capable of solving dexterous tasks in different environments and supporting different robot forms.
Gemini Robotics is a derivative version of Gemini Robotics-ER, adopting a dual-component architecture:
Gemini Robotics Backbone Network: Hosted in the cloud, responsible for vision-language reasoning.
Gemini Robotics Decoder: Running on the robot controller, responsible for action execution.
The Gemini Robotics backbone network consists of a distilled version of Gemini Robotics-ER, with query-response latency optimized to less than 160ms (a reduction of several seconds compared to the original model). To compensate for the latency of the backbone network, the Gemini Robotics decoder performs low-level control locally.

Overview of Gemini Robotics model architecture
Gemini Robotics Model Experimental Verification Results
1. Testing based on the original Gemini Robotics base model
Google researchers compared Gemini Robotics with two state-of-the-art baseline models, π0 re-implement and Multi-task Diffusion Policy, in experiments. All models were evaluated out of the box, without any task-specific fine-tuning or additional prompts.
Experimental results show:
Gemini Robotics excels in dexterous manipulation, language instruction understanding, and generalization abilities.
1) Dexterous Manipulation
In this set of experiments, researchers randomly selected 20 tasks from the dataset for testing, covering laundry rooms, kitchens, desks, and other daily activity scenarios.
Experimental results show that Gemini Robotics performs well in half of the tasks, with a success rate exceeding 80%. It particularly excels in manipulating deformable objects (like "folding pink fabric", "winding headphone wires"), where baseline models perform poorly.
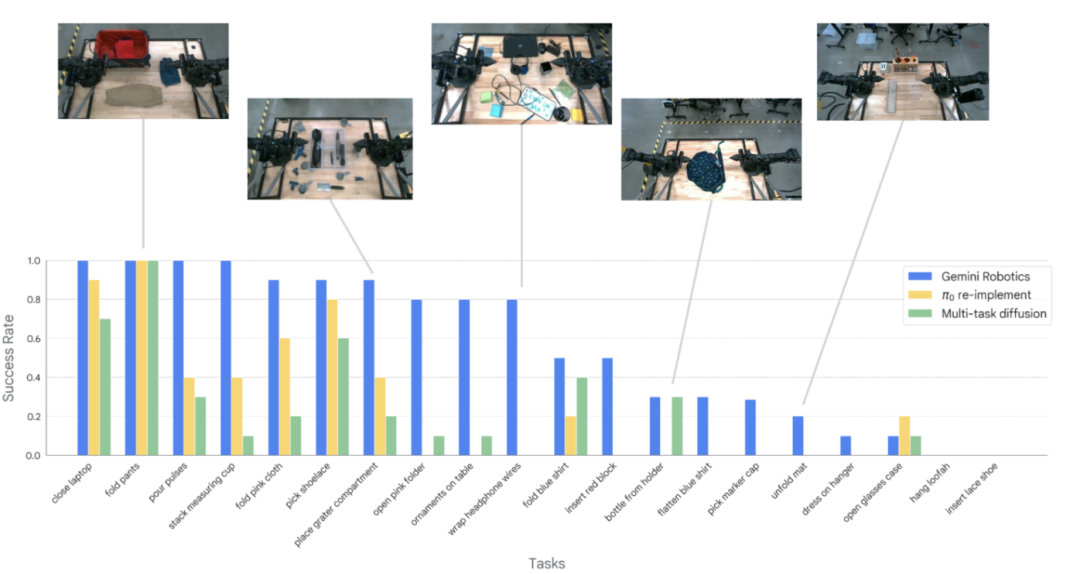
Comparison of success rates for the three models during execution of 20 different tasks
The issue is that for some complex and challenging dexterous tasks (like "inserting shoelaces"), the non-fine-tuned Gemini Robotics model still has a low success rate in task execution.
2) Language Instruction Understanding
In this set of experiments, researchers selected 25 language instructions and tested them in 5 different evaluation scenarios, including training scenarios and entirely new scenarios with unseen objects and containers.
Experimental results show that in challenging scenarios (tasks with new objects and fine-grained instructions, like "put toothpaste in the bottom compartment of the bathroom shelf"), Gemini Robotics outperforms all baseline models.
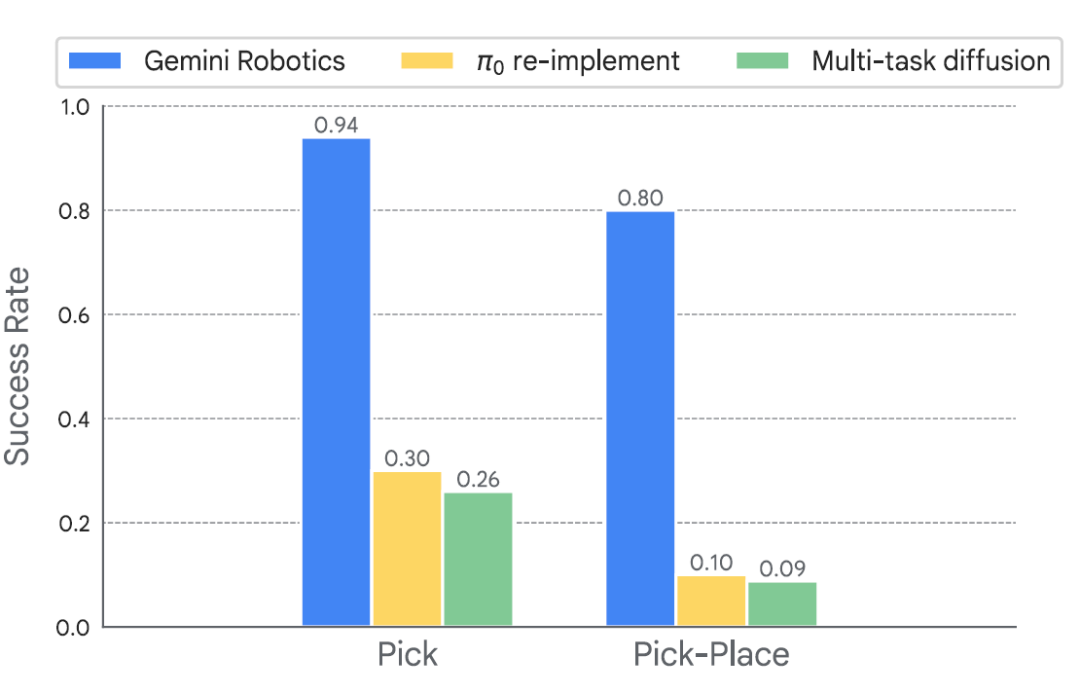
Success rates for "pick up" and "pick up and place" tasks with detailed instructions for new objects
3) Generalization Ability
Researchers evaluated the generalization ability of the Gemini Robotics model across three dimensions: instruction generalization, visual generalization, and action generalization.
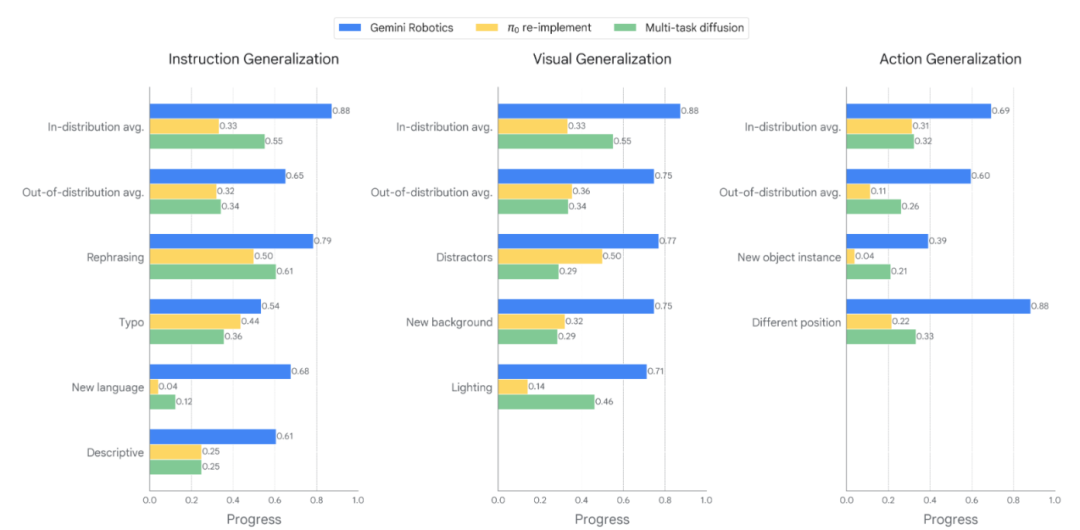
Comparison of generalization ability test results for the three models
Gemini Robotics is significantly better than the baseline models in all three types of generalization and can more effectively adapt to various changes. Even in cases where baseline models experience catastrophic failures (such as encountering instructions in new languages), Gemini Robotics still achieves non-zero success rates.
Researchers speculate that the strong generalization ability of Gemini Robotics relies on the following three reasons:
A more powerful and higher-capacity VLM (Vision-Language Model) backbone network;
The state-of-the-art visual encoder in Gemini 2.0;
Diverse training data collectively enhances the model's generalization ability.
2. Testing based on fine-tuned Gemini Robotics specialized models
Researchers further tested the model's limit capabilities and explored possible future optimization directions by fine-tuning the Gemini Robotics model on a small-scale high-quality dataset. Specific research directions are as follows:
Whether it can perform complex long-sequence dexterous tasks;
Whether reasoning abilities, semantic generalization, and spatial understanding are enhanced;
Whether it can quickly adapt to new tasks;
Whether it can be adapted to robots with different physical forms.
1) Long-sequence Dexterous Manipulation Tasks
Researchers selected six challenging long-sequence tasks to test the Gemini Robotics model fine-tuned on a small-scale high-quality dataset. These six tasks are: "folding a paper fox", "packing a lunch box", "spelling game", "playing a card game", "picking up peas", and "scooping nuts".

Gemini Robotics successfully completes various long-sequence dexterous tasks on the ALOHA robot platform

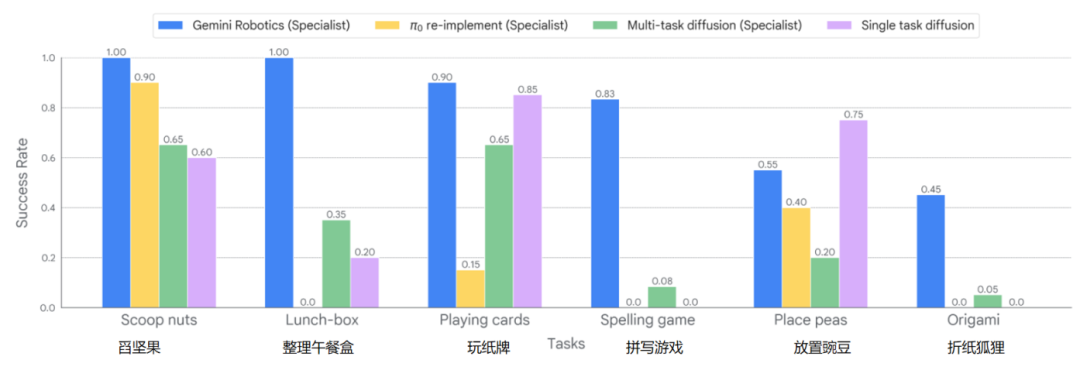
Comparison of success rates for four types of models performing six tasks
Experimental results show:
After fine-tuning with the same data, the fine-tuned Gemini Robotics specialized model is significantly better than the two fine-tuned baseline models (Multi-task diffusion (specialist) and π0 re-implement (specialist)) in terms of the success rate of executing the six tasks.
Especially in the four tasks of "scooping nuts", "packing a lunch box", "playing a card game", and "spelling game", the fine-tuned Gemini Robotics specialized model achieves a success rate of over 80% in task execution.
2) Enhanced Single-step Reasoning, Semantic Generalization, and Spatial Understanding Abilities
Researchers compared the enhanced reasoning version of Gemini Robotics with the unfine-tuned original base Gemini Robotics model, testing scenarios were real robot tasks outside the training distribution.
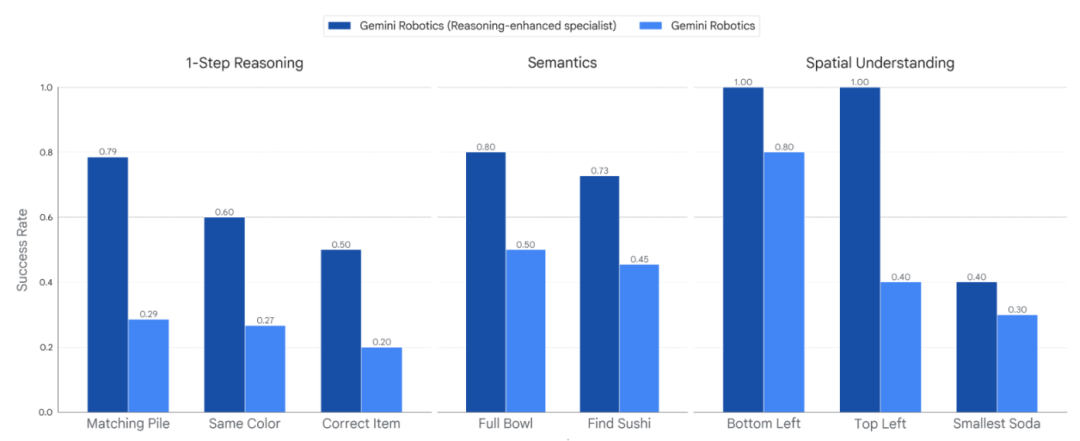
Comparison of success rates between the base Gemini Robotics model and the enhanced reasoning version in real-world evaluation tasks
Experimental results show that:
In out-of-distribution tasks in the real world, the reasoning-enhanced Gemini Robotics achieved significant improvements in the success rates of single-step reasoning, semantic knowledge, and spatial understanding tasks.
In addition, experiments also demonstrated that the reasoning-enhanced Gemini Robotics model can output interpretable intermediate steps similar to human thinking (highly consistent with the embodied reasoning trajectories of Gemini Robotics-ER), greatly improving the model's interpretability. As shown in the visualization of key point trajectories below, it is a concrete mapping of the model's internal chain of thought.

Visualization of prediction trajectories of the thinking chain of the reasoning-enhanced Gemini Robotics model
Note: The red and blue trajectories represent the model's predictions of the future 1-second motion paths of the left arm (red) and right arm (blue) using embodied reasoning knowledge, respectively.
3) Rapid adaptation to new tasks
The robot's basic model is expected to achieve rapid task learning by leveraging pre-acquired common sense of robot actions and physical interactions.
To verify this conclusion, researchers selected 8 sub-tasks from previous long-sequence tasks and fine-tuned the basic model to observe how the average success rate of each task changes with the number of demonstrations.
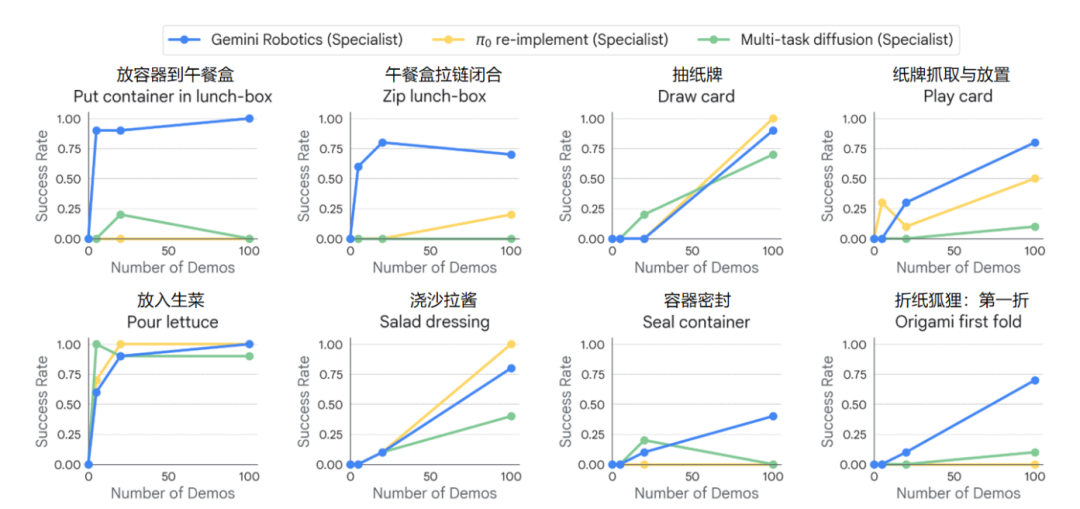
Curve of average success rate of each task varying with the number of demonstrations
Experimental results show that:
Among the 8 tasks, 7 tasks required at most 100 demonstrations (equivalent to 15 minutes to 1 hour, depending on task complexity), and the success rate of the fine-tuned Gemini Robotics specialized model exceeded 70%.
In 2 of these tasks ("place container in lunch box" and "place lettuce"), the task success rate of the fine-tuned Gemini Robotics specialized model reached 100%.
In the 3 complex tasks of "folding paper fox: first fold", "placing container in lunch box", and "closing lunch box zipper", the fine-tuned Gemini Robotics specialized model showed significantly better success rates in task execution than the baseline model.
In the 3 relatively simple tasks of "placing lettuce", "pouring salad dressing", and "drawing cards", the fine-tuned π0 re-implement specialized model performed excellently, achieving a task success rate of 100% after 100 demonstrations. The performance of π0-reimplement was slightly better than that of Gemini Robotics.
Conclusion: A powerful Vision-Language Model (VLM) backbone network can transform rich and diverse robot action data into a deep understanding of physical interactions, which is the key to enabling rapid learning of new tasks.
4) Adaptation to new robot morphologies
In this experiment, researchers explored how the Gemini Robotics model, trained based on action data from the ALOHA 2 platform, can efficiently adapt to new physical forms with a small amount of target platform data.
The new physical form robot subjects included a dual-arm Franka robot equipped with parallel grippers and a full-size humanoid robot Apollo developed by Apptronik, equipped with a five-fingered dexterous hand.

The Gemini Robotics model can be fine-tuned to control different robots
Note: The above image shows the Apollo humanoid robot sealing a lunch bag. The image below shows a dual-arm industrial robot assembling an industrial rubber belt to a pulley system.
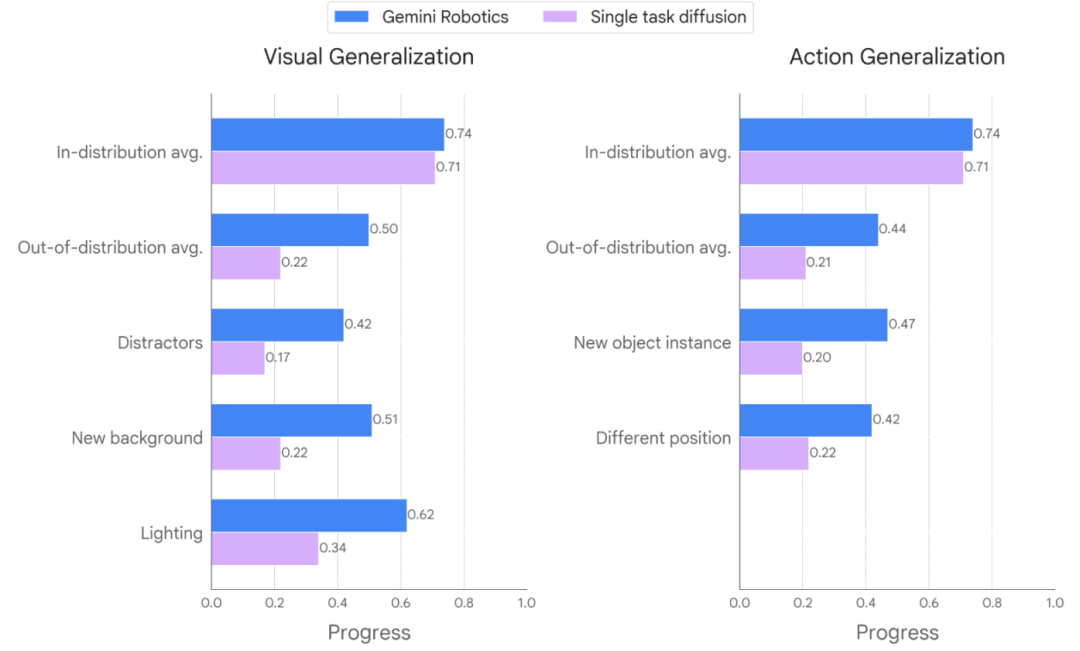
Subdivision of generalization metrics after Gemini Robotics adapts to the new physical form of the dual-arm Franka robot
Experimental results show that:
When the Gemini Robotics model adapts to a new physical form of a robot (dual-arm Franka robot), in visual and motion generalization tests:
For in-distribution tasks, the success rate of performing tasks is on par with or slightly better than advanced single-task diffusion strategies;
For out-of-distribution tasks, the success rate of performing tasks is significantly better than advanced single-task diffusion strategies;
To a certain extent, this indicates that after fine-tuning for the new physical form of the robot, the Gemini Robotics model can successfully transfer its generalization ability to robots of different forms.
Conclusion
The Gemini Robotics model demonstrates outstanding capabilities in diversified tasks such as precise manipulation of articulated objects and fine manipulation of flexible fabrics. Researchers attribute the model's outstanding capabilities to:
A powerful Vision-Language Model with enhanced embodied reasoning abilities;
A specific training scheme for robot tasks using large-scale robot action data and diverse non-robot data;
A unique architecture designed for low-latency robot control.
The key advantages of the Gemini Robotics model lie in its successful inheritance of the embodied reasoning characteristics of Gemini Robotics-ER, its ability to efficiently follow open-vocabulary instructions, and its strong zero-shot generalization ability. Through fine-tuning for specific adaptation, the model achieves high operational accuracy in new tasks/new physical forms and maintains generalization ability in challenging scenarios.
In addition, although the preliminary experimental results of Gemini Robotics show promising generalization abilities, Google researchers stated that future work will continue to focus on the following key areas:
1) Improving the ability of the Gemini Robotics model to handle more complex scenarios. Such scenarios require the model to possess the combined abilities of multi-step reasoning and precise dexterous manipulation, especially when dealing with completely new scenarios that have never been encountered before.
2) Building a simulation-driven data engine to enhance the capabilities of VLA models. Utilize simulations to generate visually diverse and contact-intensive data, developing a training paradigm for vision-language-action models oriented towards real-world transfer.
3) Expanding multi-embodied experiments to reduce the amount of data required for the model to adapt to new physical forms of robots, ultimately achieving zero-shot transfer of abilities across robot physical forms.
References:
Paper Title: Gemini Robotics: Bringing AI into the Physical World
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




