Embodied AI PoC Must Pass the Real Hardware Test
 04/03 2026
04/03 2026
 497
497

Over 30 financing deals and approximately 20 billion in funds—this is the financing landscape for embodied AI in Q1 2026, surpassing the entire year of 2025.
The industry is accelerating at an unprecedented pace. Companies are betting big on embodied large models, with the "embodied brain" becoming the hottest keyword.
Yet, technical approaches remain fragmented, making it impossible to compare who truly leads. Press conferences follow one after another, with demo videos growing more impressive. However, no one can clearly explain: where exactly does this model excel, by how much, and under what conditions?
Behind the glossy demos lies the absence of unified evaluation standards. Today's embodied AI lacks no capital, no grand narratives, and no seemingly intelligent brains—what it lacks is an objective ruler to measure capability and anchor true performance.

Behind the Viral Demos, Embodied AI Has Yet to Overcome Real-World Challenges
In recent years, viral demos of embodied AI have been endless: quadrupedal robots traversing mountains, humanoid robots performing delicate operations, and robotic arms empowered by large models seemingly capable of anything.
Yet, behind the excitement lies widespread industry "implementation anxiety"—perfect performance in simulated environments often falters in real-world settings.
In some robotic demonstration cases, it is often observed that in laboratory-preset scenarios, robotic arms can precisely grasp and place objects with a success rate as high as 98%. However, when the test environment is shifted to an ordinary home kitchen (with cluttered objects and uneven lighting), the success rate plummets to below 30%.
This awkward (awkwardness) of "works in the lab, fails in reality" is all too common in current embodied models.

Unlike ImageNet in AI or GLUE in NLP, embodied AI requires an evaluation system rooted in the real world.
For embodied models, excellent real-hardware evaluation is no longer optional—it is the key to healthy industry development, breaking through bottlenecks, and the only path to resolving current industry confusion.
The consequences of fragmented standards mean research resources are wasted in dispersion:
Some teams focus on single-task optimization, while others delve into simulated scenarios. Yet, all struggle to break through the core bottleneck of "generalization capability," trapping the industry in a cycle of "demo prosperity but delayed implementation."
In fact, RoboChallenge's previous Table30 V1 version underwent 40,000+ real-hardware tests. The results revealed that even the top embodied models today achieve an average success rate of only 51% across 30 tasks.
This is not a problem of a single company—it is the industry's reality.

Table30 V2: Not Piling on Tasks, But Tightening the "Ruler" for Real-Hardware Evaluation
RoboChallenge Table30 V2 is designed entirely for model generalization.
V2's core philosophy:
Evaluation must simulate real-world environments. Its value lies not in task quantity but in revealing the model's true limitations. Table30 V2 undergoes a comprehensive upgrade, avoiding blind task accumulation. Instead, it precisely targets current embodied models' weaknesses, emphasizing one model for multiple tasks, striving to calibrate the "ruler" for measuring model capability more accurately and rigorously.

Building on 12 classic tasks, Table30 V2 adds 18 new dual-arm dexterous manipulation tasks, totaling 30 tasks, each addressing current models' shortcomings.
New tasks focus on three directions: soft object manipulation, tool usage, and bimanual synchronization.
Soft object manipulation tests the model's understanding of non-rigid object deformation—a weak spot for many models.
Tool usage evaluates generalization capability, assessing whether the model can flexibly use tools for cross-object operations.
Bimanual synchronization targets dual-arm coordination challenges, testing the model's temporal coordination and spatial awareness.
In terms of evaluation mechanics, V2 mandates a single model for all 30 tasks, prohibiting task-specific tuning—ensuring genuine multi-task generalization capability, not "exam-oriented optimization," eliminating pseudo-breakthroughs driven solely by evaluation.
Meanwhile, V2 introduces a zero-shot evaluation track with out-of-domain scenario testing. Simply put, it challenges the model to handle unseen environments and objects, directly testing its generalization boundaries.
Additionally, a completion time scoring dimension is added, evaluating not just "can it be done" but "how efficiently," aligning with real-world deployment efficiency requirements in industrial production and household services.
At the system level, V2 boosts throughput by over 300%, significantly shortening evaluation cycles, enabling more models to undergo full testing in less time.
For academic teams and SMEs lacking proprietary hardware, this lowers participation barriers. No need for massive hardware investment—simply upload the model for standardized evaluation, fostering an open, transparent, and reproducible industry ecosystem.
Whether for teams testing their models, researchers contributing to task design, or enterprises accessing evaluation data, Table30 V2 provides entry points.

Breaking Through in Embodied AI Requires Industry Collaboration, Not Solo Efforts
Looking back at every significant leap in AI, a unified evaluation benchmark has nearly always been the driving force. ImageNet transformed computer vision from fragmentation to comparability and accumulability; GLUE gave NLP researchers a common language for dialogue. Benchmarks are not the finish line but the moment when the starting line is leveled.
Embodied AI has now reached this critical juncture.
Yet, this challenge is far more difficult than ImageNet ever was. It is not just about annotating images or running a leaderboard—it requires real hardware, real scenarios, and real operations. It demands open data sharing, exposure of weaknesses, and willingness to subject private standards to public scrutiny.
This defies commercial instincts but is essential for the industry.
This is where Table30 V2 comes in. Its purpose is not to rank the industry but to foster consensus—helping research teams understand their true position in generalization capability, providing enterprises with evidence-based selection criteria, and preventing resource wastage across the supply chain due to fragmented standards.

Whether for teams testing their models, researchers contributing to task design, or enterprises accessing evaluation data, Table30 V2 provides entry points.
It will officially launch during the CVPR 2026 GigaBrain Challenge workshop, inviting global teams to participate in an open collaboration: calibrating standards, enriching scenarios, and sharing data.
Only when all players abandon proprietary standards and measure progress with the same ruler can embodied AI achieve its "ChatGPT moment," enabling robots to truly move from labs into industries worldwide.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
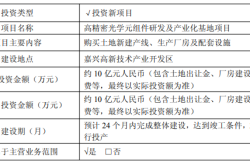
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?