RL Token: Solving the 'Last Centimeter' Precision Challenge for VLA, Enabling Accurate Online Reinforcement Learning-Based Robot Manipulation
 04/03 2026
04/03 2026
 581
581
It is not difficult for a robot to pick up a screwdriver. The challenge lies in accurately aligning its tip with a tiny screw within seconds.
This is not a sci-fi scene from a future world but a very real and tricky problem in today's robotic manipulation.
Currently, VLA models have demonstrated impressive general-purpose capabilities in diverse tasks such as folding clothes, brewing coffee, and making grilled cheese sandwiches. However, when deployed in factories, laboratories, or even homes, it quickly becomes apparent that general capabilities do not necessarily equate to practical usability.
The reason is simple: truly practical physical manipulation also requires precision, dexterity, and speed. When performing high-precision operations at the 'last millimeter' level, VLA models often become hesitant, sluggish, or even repeatedly fail. Why is this the case? Because high-precision operations are inherently highly sensitive to minor errors, which are difficult to cover with expert demonstration data alone. While such data can teach robots 'how to do it,' it struggles to teach them 'how to do it quickly and accurately.'
A natural solution emerges: let robots learn by doing. This is precisely where reinforcement learning excels.
But another problem arises.
In real-world robot learning, each attempt takes time, and every failure comes with equipment wear and tear. Ideally, we want robots to optimize a critical skill within hours or even minutes. However, directly fine-tuning an entire VLA model through reinforcement learning is computationally expensive and sample-inefficient, making it impractical.
Alternatively, training a small model using traditional reinforcement learning methods may be fast but sacrifices the VLA's powerful generalization capabilities.
This creates a dilemma: we need both the VLA's generalization ability and the speed and sample efficiency of online reinforcement learning.
Recently, the Physical Intelligence (PI) team proposed the RL Token (RLT) method in their latest research paper, 'RL Token: Bootstrapping Online RL with Vision-Language-Action Models.' By constructing a compact interface between VLA and lightweight reinforcement learning, this method enables robots to achieve online optimization for precision manipulation with just a few hours of real-world interaction data. It effectively addresses the industry pain point of balancing generalization and precision in general-purpose models, providing a new technical pathway for dexterous robot manipulation.
I. RL Token Implementation
The core design philosophy of RL Token (RLT) is to freeze the main VLA model and use a lightweight network for online reinforcement learning fine-tuning through a compact representation interface, achieving a balance between generalization and precision optimization. The entire solution requires no custom development and can directly interface with pre-trained VLA models, quickly adapting to various precision manipulation tasks.
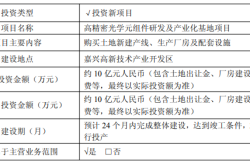
RL Token Working Mechanism (PI Paper, See References)
1. RL Token Generation Mechanism
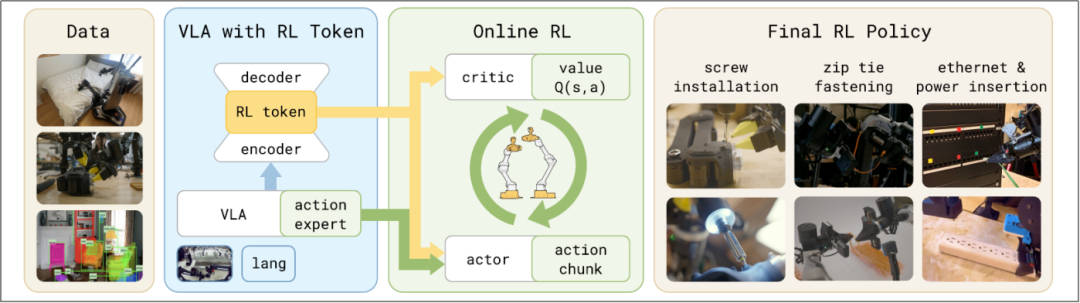
RL Token serves as a compact information interface between VLA and a lightweight reinforcement learning network, implemented by adding an encoding-decoding Transformer to adapt the VLA model:
The encoder compresses the VLA's high-dimensional internal representations into low-dimensional vectors (RL Tokens), condensing core task information (including visual perception, semantic understanding, and motion priors).
The decoder reconstructs the VLA's original embeddings to ensure RL Tokens retain complete task-critical information, forming an information bottleneck to prevent the loss of meaningful features.
After training, VLA parameters are frozen, and RL Tokens serve as state inputs for a lightweight Actor-Critic network, enabling efficient reinforcement learning by leveraging the VLA's rich perceptual knowledge.
2. Lightweight Reinforcement Learning Design
Based on RL Tokens, the solution employs a sample-efficient off-policy Actor-Critic online reinforcement learning algorithm, training only lightweight policy (Actor) and value (Critic) heads. These can run locally on the robot, completing hundreds of parameter updates per second for real-time policy optimization.
To ensure training stability and efficiency, the solution optimizes three key designs:
1) Action Space Alignment
The reinforcement learning policy directly predicts action chunks, maintaining full consistency with the underlying VLA's action structure rather than executing frame-by-frame at the single-step control level. By optimizing continuous action sequences, the online policy effectively adjusts critical temporally extended motion patterns in tasks, meeting the temporal consistency requirements of precision manipulation.
2) Regularization Constraints to Anchor Behavior
The policy network (Actor) takes VLA-predicted actions as input, learning to correct rather than replace reference actions. A regularization constraint toward reference actions is introduced during policy updates, keeping the Actor network close to the VLA's reference actions:
When VLA behavior is reasonable, actions align with VLA, ensuring training stability.
When actions deviate from VLA, the constraint strengthens, guiding the network toward reasonable actions.
Only when the Critic determines that deviation yields higher rewards is limited exploration permitted, avoiding ineffective trial-and-error.
Meanwhile, to prevent the policy from simply copying VLA actions during early training, a reference-action dropout mechanism is introduced, forcing the policy network to maintain an independent action generation path while fully utilizing prior knowledge and retaining its optimization capabilities.
3) Optional Human Intervention Integration
The solution can selectively incorporate human intervention signals directly into the reinforcement learning update process. When robots stall or make execution errors, human correction signals can be fed back into the training process, further enhancing policy robustness and task adaptability.
These designs make online reinforcement learning a universal solution that can be directly appended to pre-trained VLAs without engineering modifications for specific tasks, enabling stable and efficient real-time policy optimization.
3. End-to-End Deployment Process
The entire process transforms online reinforcement learning into local fine-tuning of VLA behavior rather than unconstrained exploration, perfectly balancing efficiency, stability, and performance.
Practical application of RL Token involves two simple and efficient steps:
VLA Adaptation Phase: Fine-tune the VLA on a small amount of task-specific demonstration data. This serves two purposes: improving the VLA's initial execution capability for the target task and enabling it to output a specialized feature (RL Token) for subsequent reinforcement learning training.
Online RL Optimization Phase: Freeze VLA parameters and train lightweight Actor and Critic networks online. These networks take RL Token representations and VLA reference actions as conditional inputs, applying regularization constraints to the learned policy to keep it close to the VLA model.
This approach does not let the robot blindly grope in the dark (unconstrained search) but instead performs local fine-tuning based on a pre-trained model with some operational capability. It trains only two lightweight networks, enabling fast operation while fully leveraging the pre-trained model's existing understanding and operational experience, achieving efficient learning 'on the shoulders of giants.'
RL Token Extraction (PI Paper, See References)
II. Experimental Validation
To comprehensively validate the effectiveness of RLT (RL Token architecture) in high-precision manipulation tasks, researchers conducted systematic experiments on four sub-millimeter tasks requiring both precision and speed: screw installation (using an electric screwdriver to drive an M3 screw into a threaded hole), cable tie tightening, Ethernet connector insertion, and charger insertion. Experimental results demonstrate dual breakthroughs in task success rate and execution speed, along with exceptional sample efficiency and generalization capabilities.
1. Experimental Setup
Each task includes grasping, repositioning, and alignment phases, with a total duration of 30-120 seconds (control frequency: 50Hz, corresponding to approximately 1500-6000 control steps). For each task, researchers defined critical phases—insertion, tightening, or rotation—where precision requirements are highest and the baseline VLA model most frequently stalls or fails. Critical phases typically last 5-20 seconds (250-1000 control steps).
Reinforcement learning policy inputs include: RL Tokens (generated from two wrist camera images and one base camera image) and additional proprioceptive states. Auxiliary state information varies by task: joint positions for screw installation; end-effector pose for cable tie tightening, Ethernet connector insertion, and charger insertion.
The experiment uses π0.6 as the baseline VLA model, with the robot operating at a 50Hz control frequency. The single-timestep action space dimension is 14, corresponding to a 140-dimensional chunked action space for the reinforcement learning Actor network.
2. Experimental Results
1) Performance Improvement of Online Reinforcement Learning Over Baseline VLA Policy
The method was evaluated under two settings: a controlled setting isolating critical phases and a full-task setting requiring stronger robustness from the reinforcement learning policy. Online reinforcement learning improved both success rate and execution speed under both settings.
In the controlled setting, RLT achieved stable improvements across all critical phases of the four tasks. Even in relatively simple tasks where the baseline policy already demonstrated good reliability (charger insertion, Ethernet connector insertion), RLT-learned policies increased execution speed in critical phases by approximately 3x. For more challenging tasks like cable tie tightening and screw installation, success rate improvements were even more significant.
In full-task evaluations, overall success rates declined slightly due to error accumulation in early task phases (grasping, lifting objects), but RLT still increased success rates by 40% for screw installation and 60% for cable tie tightening.
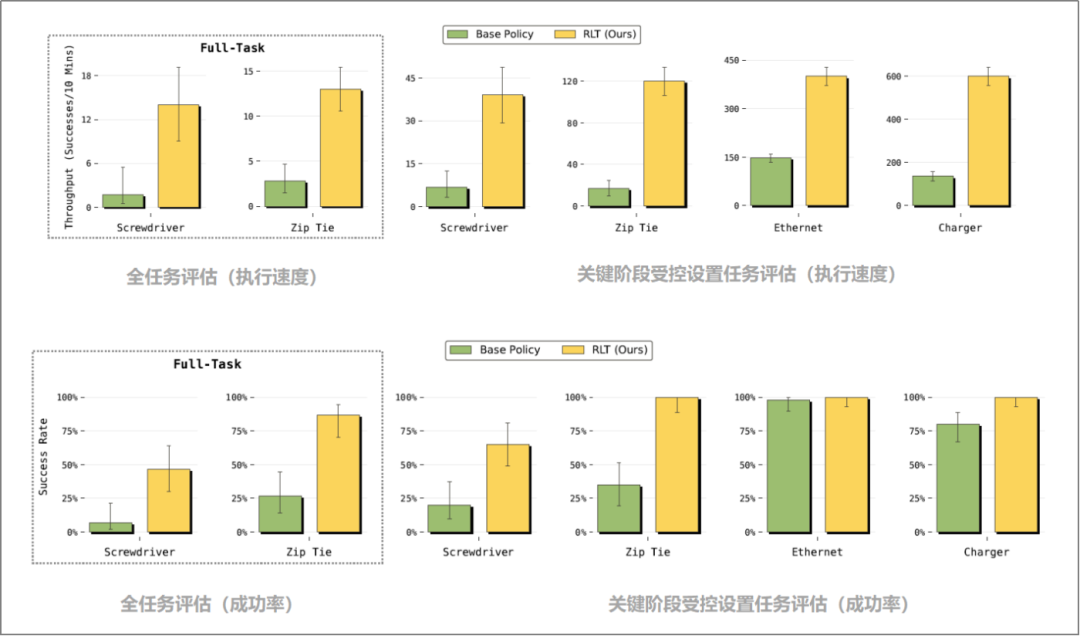
Full-Task and Critical Phase Controlled Setting Task Evaluations (PI Paper, See References)
Notes: 1) ScrewDriver: Screw Installation 2) Zip Tie: Cable Tie Tightening 3) Ethernet: Ethernet Connector Insertion 4) Charger: Charger Insertion
2) Significant Throughput Improvement of RLT Compared to Baseline Methods
In the Ethernet connector insertion task, RLT was compared with four baseline methods:
HIL-SERL and PLD: Both are single-step online reinforcement learning methods that fail to learn effectively in this task spanning hundreds of steps with sparse rewards. Without action chunking, the task duration becomes extremely long, making it difficult for value function updates to effectively propagate sparse reward signals.
DAgger and DSRL: These achieve success rates comparable to RLT but offer far weaker speed improvements. DAgger, an imitation learning method, is limited by the speed of human demonstrations and interventions; DSRL, a reinforcement learning method that strictly constrains the policy near the baseline VLA, ensures training stability but has limited performance improvement potential.
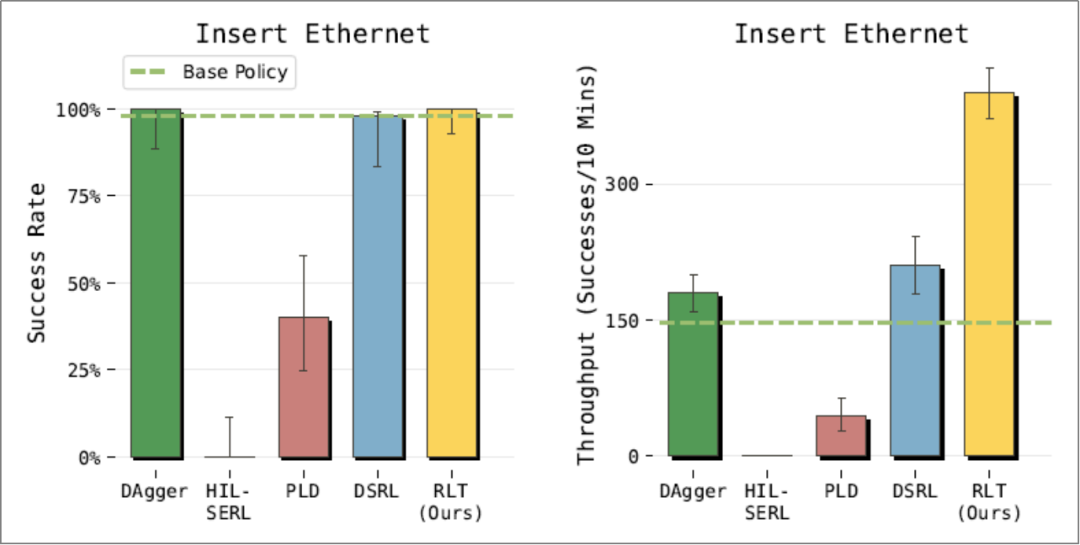
Comparison of RLT with Other Reinforcement Learning Algorithms (PI Paper, See References)
Notes: RLT is compared with multiple baseline methods from recent reinforcement learning literature. Methods using single-step actions rather than action chunks (HIL-SERL, PLD) perform poorly. While DSRL achieves high success rates, it significantly lags behind RLT in task throughput.
3) Indispensability of the Four Components: RL Token, Action Chunks, BC Regularization, and Reference Action Passthrough
Ablation tests verified the core value of the four key designs in RLT (RL Token, action chunks, BC regularization, and reference action passthrough). Removing any component led to noticeable performance declines:
Replacing RL Token with a ResNet-10 encoder reduced throughput by 50%, proving that the proposed Token encodes task-specific structural information unavailable from general-purpose encoders trained on standard computer vision tasks.
Replacing action chunks (C=10) with single-step actions significantly prolonged the effective task duration, as the value function needed to perform credit assignment over longer sequences, while also making RL Token-based methods infeasible. In actual experiments, the single-step variant failed to consistently reach baseline policy performance.
Removing BC regularization (β=0) caused the largest single performance drop, as it forced the Actor network to explore the full action space relying solely on Q-function gradients.
Removing reference action passthrough slowed learning speed, causing early exploration deviations and occasional degenerate behaviors. While this ablation group eventually reached RLT's performance on this simple task, it experienced more failures during training.
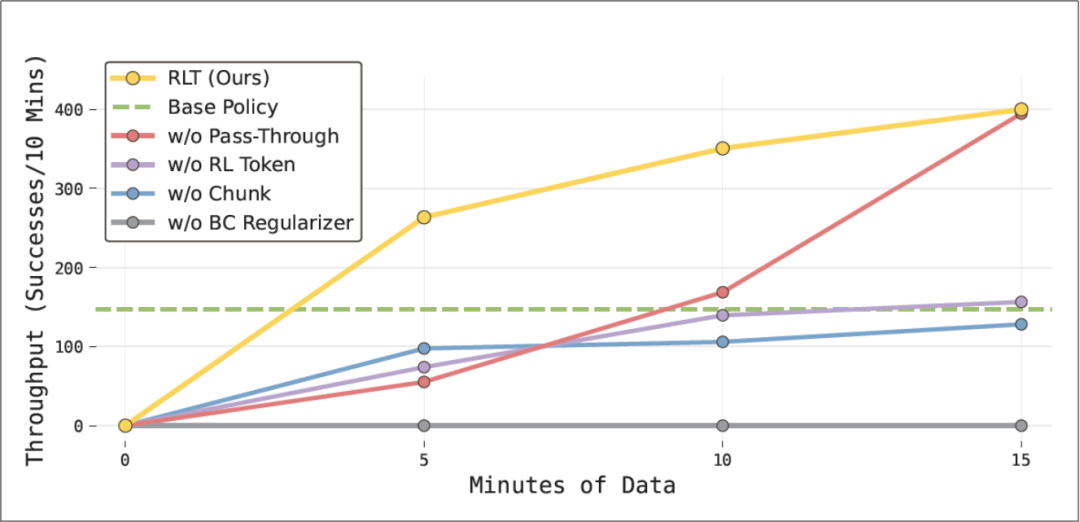
Throughput at Different Stages During Ethernet Connector Insertion Task Training (PI Paper, See References)
Note: 1) w/o BC Regularizer: Without BC regularization term. 2) w/o Chunk: Without action chunking. 3) w/o RL Token: Without RL Token. 4) w/o Pass-Through: Without reference action pass-through.
The ablation study demonstrates that each component of our method is crucial for achieving superior performance, with the complete system exhibiting the fastest learning speed and the best final performance. Notably, RLT surpasses alternative strategies after consuming just 5 minutes of data in task-critical sections (the entire experiment lasted approximately 40 minutes). Removing reference actions from the Actor network's input ("no pass-through mechanism" configuration) still achieves optimal final performance but at the cost of slower learning and a significantly higher number of failures throughout the training process.
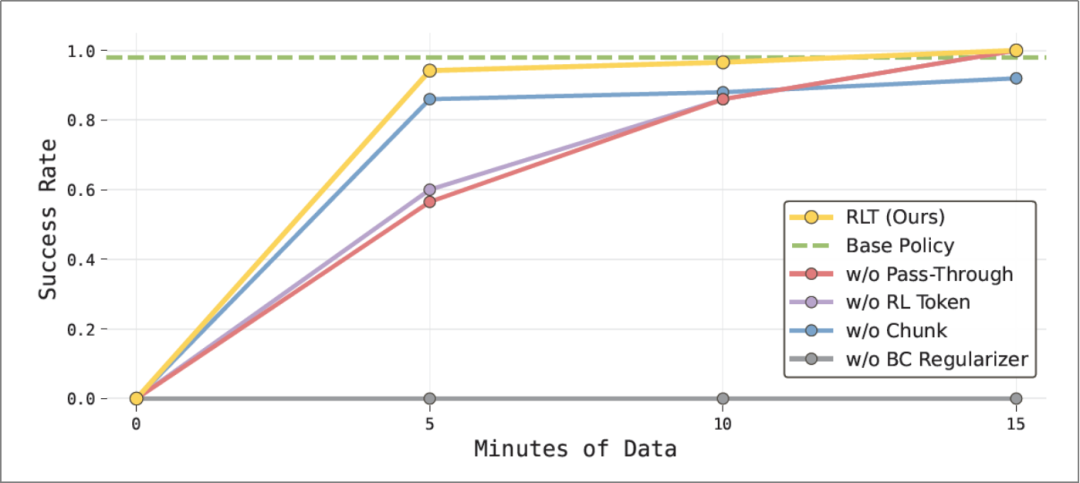
Success Rate Evaluation During Ethernet Plugging Task Training (PI Paper, see References)
In the Ethernet connector plugging task, RLT rapidly achieves a success rate comparable to the VLA strategy while improving task throughput. Omitting the reference action pass-through mechanism or not using RL Token both result in slower model learning.
4) RLT Generates Efficient Behaviors Surpassing Human Demonstrations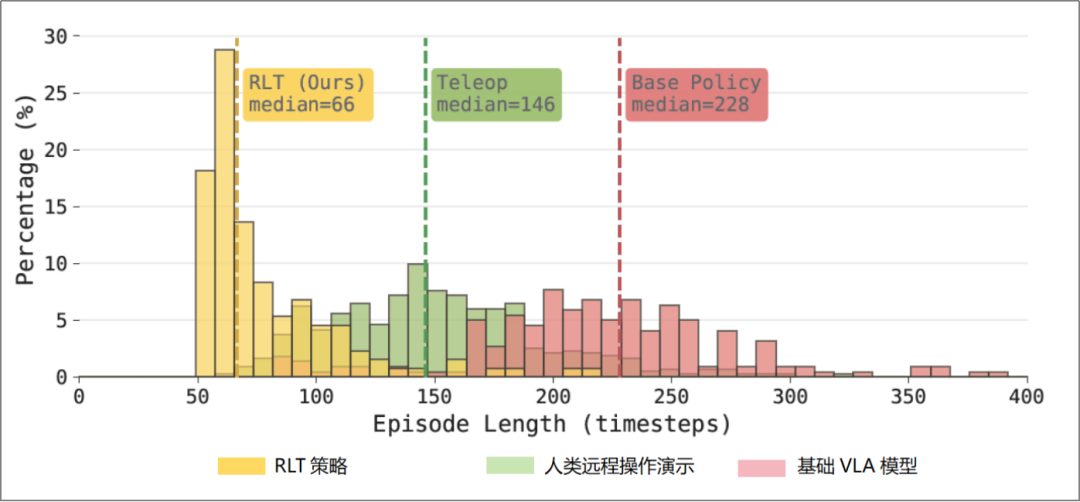
The experimental results show that online reinforcement learning fundamentally changes the robot's task execution approach.
For critical phases of the Ethernet plugging task, researchers visualized the speed distributions of human teleoperation demonstrations, the baseline VLA model, and the RLT strategy (as shown above):
The baseline VLA model often exhibits "probing" behavior when approaching the target: moving close, slightly retracting, readjusting, and then attempting again—sometimes requiring multiple cycles of such attempts to succeed.
The RLT strategy directly approaches the interface and completes the connector plugging with smooth motions. Even if the first attempt fails, RLT applies pressure and slightly oscillates the connector, leveraging mechanical compliance for faster insertion. This behavior, absent from the demonstration data, arises entirely from online exploration, demonstrating the method's ability to surpass simple imitation of human strategies.
III. Future Prospects
The iterative capability enhancement of embodied intelligence models typically follows a gradual technological pathway: first, constructing general perception and foundational motor skills through large-scale pre-training to provide a robust model base for subsequent optimization; then, in real-world deployments, fine-tuning the model locally using task-specific interaction data to improve the precision and stability of critical actions; finally, combining human feedback with reinforcement learning to further enhance high-level reasoning and decision-making capabilities in complex tasks.
RL Token represents one of the core implementation methods in the second stage of this pathway—serving as a bridge between large VLA models and online reinforcement learning, it transforms online RL into local fine-tuning of high-potential VLA behaviors rather than unconstrained exploration, enabling rapid and efficient learning. In the current approach, selective human intervention can also be introduced: when robot execution is obstructed or operational deviations occur, human correction signals assist policy updates, further ensuring training stability.
In the future, integrating technologies such as reward models and progress prediction could enable a fully autonomous reinforcement learning optimization process—aligning with the third stage of the pathway (Reinforcement Learning with Human Feedback, RLHF)—allowing robots to continuously self-evolve without human intervention. When models can close the loop of "pre-training—scene fine-tuning—human feedback optimization" through sustained real-world interactions, their performance in practical tasks will achieve continuous iteration and stable improvement.
RL Token represents not only a significant technological innovation but also a key technical enabler for transitioning robots from "passive instruction execution" to online autonomous optimization and continuous adaptive evolution. By equipping general-purpose robot large models with efficient online self-optimization capabilities, this approach significantly enhances robots' precision, efficiency, and generalization adaptability in fine manipulation scenarios, providing a viable path for automation upgrades in Smart Manufacturing (intelligent manufacturing), precision assembly, and other fields.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?