Trend丨MRDIMM is Rising to Alleviate Bandwidth Bottlenecks
 05/22 2026
05/22 2026
 465
465
Foreword:
On April 17, 2026, global enterprise spending on inference infrastructure reached $68 billion, surpassing training spending of $45 billion for the first time. However, a deeper crisis is emerging: the "memory wall" is becoming the final straw that breaks AI performance. In 2009, the available memory bandwidth per core was around 8GB/s, but by 2026, it had dropped to just about 4GB/s. Against this backdrop, a new memory technology called "MRDIMM" (Multiplexed Rank Dual Inline Memory Module) is emerging as the most underrated variable in the AGI race.
The Real Dilemma Facing AI Computing
Over the past decade, CPU core counts have grown exponentially, and PCIe bandwidth has exploded, but the growth rate of system memory bandwidth has lagged significantly. This means that while total memory bandwidth is increasing, the available memory bandwidth per core is decreasing due to the faster increase in CPU core counts. The decline in available bandwidth per core directly leads to each core being "underfed," with computing performance locked by data supply speed.
The explosion of AI inference has pushed this contradiction to the extreme. In large model inference, each token generation requires moving the entire model's weights from memory to the computing unit. The core bottleneck in this process is not computation but memory bandwidth—effective bandwidth determines how fast answers are generated. As inference gradually replaces training as the new engine of the AI industry, GPUs, which excel at logical operations but lack sufficient memory bandwidth, are exposing their structural weaknesses.
What is MRDIMM?
Faced with this dilemma, the industry is exploring a "low-cost, high-return" breakthrough path: MRDIMM.
Traditional RDIMMs operate their DRAM chips and host interface at the same frequency. MRDIMM introduces multiplexing technology between the host memory channel and DRAM chips, allowing DRAM chips to run at their native rate while doubling the memory channel frequency. In simple terms: in RDIMMs, two memory RANKs can only alternate "work," while MRDIMM enables them to access data in parallel at the same time, increasing data transfer per operation from 64 bytes to 128 bytes—akin to building a dual-lane highway.
At the practical product level, take Intel's Xeon 6 performance core processor as an example. Standard DDR5 RDIMMs can only achieve a data transfer rate of 6400MT/s, while MRDIMMs surge to 8800MT/s without requiring motherboard design changes, representing a nearly 40% increase in peak bandwidth. Real-world testing by the Barcelona Supercomputing Center directly proves: upgrading from RDIMM to MRDIMM increases system memory bandwidth by 41.3%, bandwidth-intensive task performance by 27% to 41%, reduces memory access latency by hundreds of nanoseconds, and cuts server energy consumption for memory-intensive workloads by up to 30%.
The ultimate strength of MRDIMM lies in its architectural innovation, which breaks through the physical ceiling of DRAM frequency, achieving an engineering miracle of "significant bandwidth increase without upgrading DRAM chips." The second-generation MRDIMM, planned for 2026/2027, aims for a target rate of 12800 MT/s, a 45% increase over current specifications; the third-generation specification of 17600 MT/s has also initiated early development, with a roadmap extending into the 2030s.
The Irreplaceability of MRDIMM in Inference Scenarios
From a product perspective, the core value proposition of MRDIMM is not simply increasing memory capacity but focusing on high bandwidth and low latency—perfectly complementing the essential needs of AI inference.
Specifically, a report by GF Securities points out that in the KV Cache (Key-Value Cache) scenarios of large model inference, MRDIMM offers a hierarchical collaborative advantage of "high bandwidth at the near end and large capacity at the far end," enabling higher concurrency, longer context, and lower end-to-end latency. Real-world comparisons show that MRDIMM can increase bandwidth under AI workloads by 2.3x compared to DDR5 RDIMM peaks, support up to 128GB per stick, and significantly optimize memory orchestration and resource utilization between CPUs and GPUs with longer context and higher concurrent session capabilities.
More critically, Intel's "plug-and-play" design ensures full compatibility between MRDIMM and existing server platforms' RDIMM slots, eliminating the need for motherboard replacements or software rewrites, greatly lowering deployment barriers for enterprise clients. Additionally, each generation of MRDIMM speed improvements is based on continuous enhancements to the DDR5 architecture, extending DDR5's lifecycle while allowing server vendors and memory manufacturers to steadily upgrade heterogeneous server performance from 2026 to 2028 without prematurely shifting to the immature and costly next-generation DDR6 memory standard.
Industry Competition: The Race for Technological Architecture and Ecosystem Standards
Beyond technology and markets, the fiercest competition lies in standardization. In May 2026, JEDEC Solid State Technology Association announced multiple standard advancements, including the release of the JESD82-552 standard (DDR5MDB02 Multiplexed Rank Data Buffer), the forthcoming JESD82-542 MRCD02 standard strengthening signal integrity and timing control, and the near-completion of the MRDIMM Gen2 module standard by the JC-45 committee. JEDEC explicitly stated that this marks the official transition from "sample validation" to "large-scale adoption" for the high-bandwidth demands of AI and cloud computing.
In the international market, Samsung, SK Hynix, and Micron have entered the fray. Micron led with samples in high-performance main memory, Samsung is actively advance ing productization, and SK Hynix became the first to pass Intel Xeon 6 platform certification based on its fifth-generation 10nm-class 32Gb die. Domestic supply chains are also catching up, with companies like Montage Technology and JCET providing supporting MRCD, MDB interface chips, and SPD products, with the market scale surging from the billion-yuan to trillion-yuan level in 2026.
However, the market penetration space for MRDIMM remains vast. While JEDEC standards have partially landed, the overall technology is still in early validation stages, with high production costs and limited platform support. TrendForce data indicates that true scale penetration will occur from 2026 to 2029. To lead in this standardization race, domestic and international ecosystem partners are collaboratively promoting generalization from "Xeon 6 exclusive launch" to industry-wide adoption.
Thus, MRDIMM's greatest commercial value lies in its "downward compatibility and ease of use, upward scalability in capacity and bandwidth," and its global proliferation alongside JEDEC standardization, becoming the ecosystem foundation for server memory in the next 5-10 years.
Conclusion
As trillion-parameter large models move out of labs, memory bandwidth has become the final constraint on performance release. The rise of MRDIMM reveals that in an era of solidify (fixed) compute chip designs and approaching power consumption bottlenecks, disruptive innovation in system memory architecture can equally drive exponential improvements in performance and energy efficiency. It is not only a reliable support for CPUs to achieve stronger AI computing power but also a key lever to unlock the potential of heterogeneous data centers at the lowest hardware upgrade cost.
Online Sources:
The Paper: "MRDIMM Accelerates Penetration in the Chinese Market"
Baidu Developer Center: "The Hardware Scaling Dilemma of Hyper-Scale Training: Paradigm Reconstruction from Data Parallelism to Hybrid Parallelism"
Jiufang Zhitou: "GF Securities: MRDIMM and CXL Boost AI Server Memory, Recommend Core Beneficiary Stocks in the Supply Chain"
-
![]()
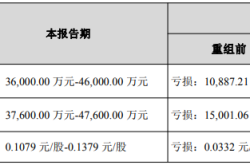
OFILM Reports Colossal 460 Million Yuan Loss: Founder Quietly Shifts Focus to Optical Modules!
-
![]()
Yutong Optics and Zeiss Forge Partnership to Develop Quality Measurement System and Launch "Optical Communication Joint Measurement Class"
-
![]()
AutoNavi Revises Splash Screen Ads with Precision Amid Controversy
-
![]()
Unlicensed Vehicle Disputes: AutoNavi Ensnared in the Aggregation Model
-
![]()
Agent: The 'Hard Requirement' for Entering Core Enterprise Systems for the First Time
-
![]()
Global Auto Market Outlook: Sales Decline in China, US, and Europe, Chinese Exports Approach 10 Million
-
![]()
AI Pioneer Breaks Free from the 'Doldrums'
-
![]()
Valuation Exceeds $26 Billion! Three Chinese "Gold Medalists" Shake Up the AI Industry