Introducing BlendServe: Revolutionizing Large Model Inference with Resource-Aware Batching Strategies
 04/30 2025
04/30 2025
 614
614
Full text: approximately 2600 words, estimated reading time: 7 minutes
In recent years, the proliferation of large language models (LLMs) has necessitated continuous optimization of inference service systems. However, balancing computational resource utilization efficiency and performance remains a critical challenge, particularly in offline batch inference scenarios.
Today, we delve into BlendServe, a system jointly proposed by teams from the University of California, Berkeley, the University of Washington, and others. Through innovative resource-aware batching strategies, BlendServe significantly enhances hardware utilization and inference throughput. This article offers a concise overview of the system's core highlights, background, methodological innovations, and industry significance.
Core Highlights
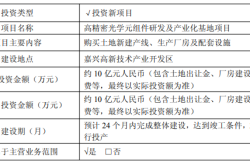
BlendServe's primary objective is to maximize hardware resource utilization while maintaining a high prefix sharing rate through request reordering and overlapping. Experiments demonstrate the system's exceptional performance under various synthetic multimodal workloads:
- Throughput Improvement: BlendServe achieves up to 1.44x throughput acceleration compared to existing industry standards (e.g., vLLM and SGLang).
- Resource Overlap Optimization: A resource-aware prefix tree design effectively combines compute-intensive and memory-intensive requests, achieving optimal resource scheduling.
- Prefix Sharing Maintenance: Even while optimizing resource usage, BlendServe maintains a near-optimal prefix sharing rate (exceeding 97%).
- Versatility: BlendServe exhibits stable performance advantages across text generation, video understanding, and multimodal tasks.
These breakthroughs offer a novel solution for offline inference tasks, particularly in large-scale multimodal data processing, where they hold significant application value.
Research Background
Traditional online inference services prioritize low latency, often adopting a strict "First Come, First Served" (FCFS) strategy. In contrast, offline batch inference scenarios offer more flexible request scheduling and resource optimization due to looser latency requirements. The rise of the Transformer architecture has further diversified models' input and output lengths, introducing new challenges such as long-context reasoning, complex reasoning chains, and multimodal extensions.
These diversities pose challenges: Requests vary significantly in their demands for computational resources and memory bandwidth. Existing techniques, like NanoFlow, attempt to optimize resource usage through operation-level overlapping but ignore the resource complementarity between requests, limiting overall performance. Thus, efficient resource scheduling in offline inference has become paramount.
BlendServe addresses this issue with a novel scheduling method that balances resource overlap and prefix sharing, reducing inference costs while ensuring high throughput.
Core Contributions
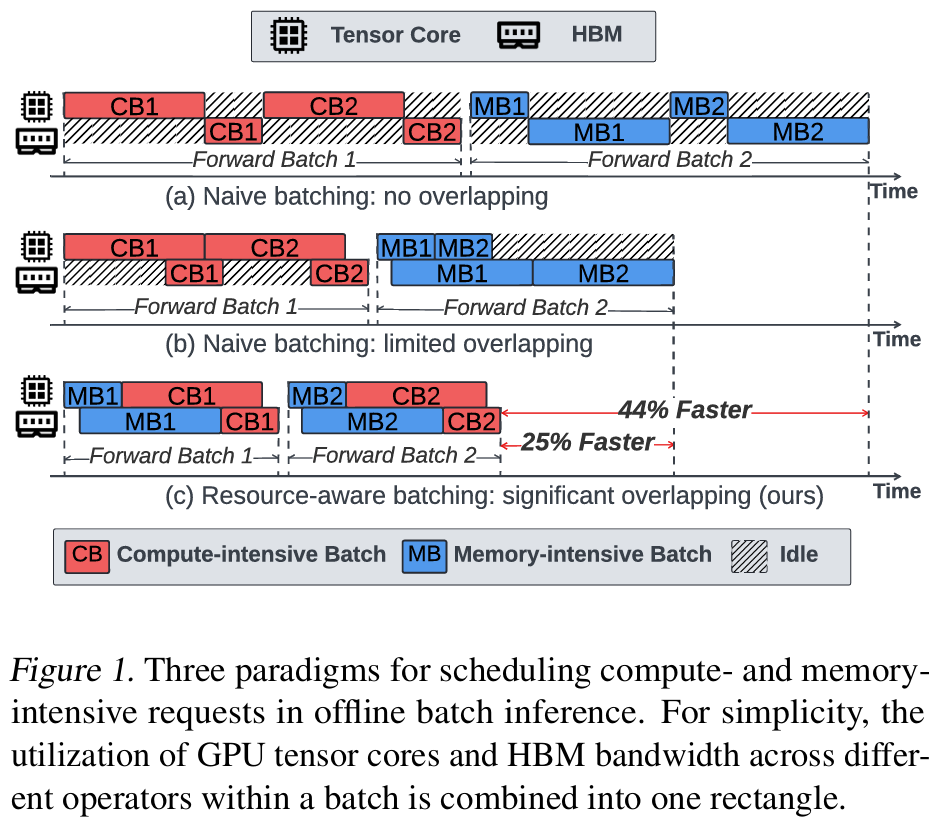
Method Innovation: Resource-Aware Prefix Tree
To achieve global optimization of resource scheduling, BlendServe introduces a resource-aware prefix tree structure. This structure captures prefix sharing relationships and quantifies resource demand characteristics through computational density values. Specifically:
- Computational Density Definition: Computational density (ρ(r)) is the ratio of computation time to memory-bound operation time, distinguishing between compute-intensive and memory-intensive requests.
- Double Scan Algorithm: On the sorted prefix tree, BlendServe employs a heuristic double scan algorithm that dynamically constructs mixed request batches, ensuring balanced compute and memory resource usage while maintaining a high prefix sharing rate.
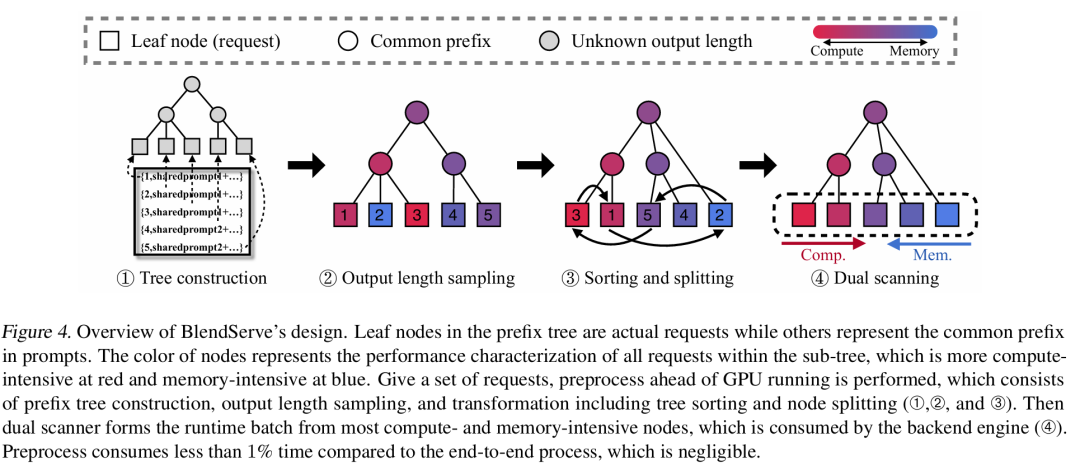
Experimental results show that BlendServe achieves an average throughput improvement of 20.84% compared to traditional Depth-First Search (DFS) methods (benchmark: NanoFlow-DFS).
Theoretical Breakthrough: Balancing Prefix Sharing and Resource Overlap
Traditional methods often struggle with the trade-off between prefix sharing and resource overlap. BlendServe resolves this through theoretical modeling:
- Requests are hierarchically sorted based on computational density, ensuring a uniform distribution of compute-intensive and memory-intensive tasks.
- By dynamically adjusting GPU memory partitions, BlendServe achieves an optimal resource overlap ratio within each batch, maximizing hardware utilization.
In practical tests, BlendServe reaches 86.55% of the theoretically optimal throughput, outperforming existing baselines.
Empirical Results: Wide-Ranging Performance Improvements

The research team validated BlendServe's performance on multiple synthetic workloads, including WildChat, ShareGPT, Azure-Trace, and OpenVid. The results indicate:
- In high prefix sharing scenarios, system performance is stable, with throughput improvements ranging from 19.34% to 22.65%.
- In low prefix sharing scenarios, BlendServe still achieves performance gains of 14% to 34% through efficient resource overlap strategies.
BlendServe's flexibility makes it suitable for distributed environments, easily scaling to multi-GPU or multi-node deployments, aligning with current trends in large-scale inference services.
Industry Significance
BlendServe's research findings offer new insights into offline inference tasks and profoundly impact the AI inference service field:
- Driving Multimodal Reasoning Development: As multimodal models (e.g., EMU, VILA-U) become prevalent, BlendServe's resource-aware mechanism provides an efficient solution, helping reduce computational costs.
- Aligning with Green Computing Trends: By improving hardware utilization, BlendServe significantly reduces inference tasks' energy consumption, aligning with carbon neutrality policies and contributing to green data center construction.
- Leading Technological Change: This research serves as a crucial reference for future inference system design, particularly in resource scheduling optimization in distributed environments. It is expected to drive the emergence of a new generation of inference frameworks.
Conclusion
With its unique resource-aware batching strategy, BlendServe successfully addresses the resource scheduling bottleneck in offline inference, delivering significant performance improvements for multimodal tasks and large-scale inference services. As more application scenarios emerge, this technology is poised to become a cornerstone in the AI inference field, driving substantial industry transformation.
???? Paper Link: https://arxiv.org/abs/2411.16102
The first authors, Yilong Zhao and Shuo Yang, have extensive experience in AI system optimization, contributing to numerous research projects on high-performance computing and machine learning systems. This research was supported by the University of California, Berkeley, the University of Washington, and the xAI Lab.
-- End --
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?