Towards Human-Level Driving Intelligence: The Vision-Language-Action Model (VLA)
 05/15 2025
05/15 2025
 891
891
Produced by ZhiNeng Technology
In 2025, the ADAS industry finds itself in the twilight hours, plagued by safety concerns and stringent regulations.
Navigating complex real-world road conditions, diverse human behaviors, and the inherent limitations of traditional AI in generalization and understanding, Li Auto shed light on the "Vision-Language-Action Model (VLA)" in the second season of "AI Talk".
VLA is not merely an incremental model upgrade but a transformative leap from insect-like rule-based algorithms to end-to-end systems mirroring mammalian intelligence, culminating in a "Driver-Level Model" embodying true human driving cognition and execution.
We delve into VLA's three-stage evolution, dissecting its architecture, training processes, and pivotal breakthroughs. We explore how it shatters the impasse in intelligent driving development, positioning itself as a pivotal milestone towards L4+ autonomous driving.

01
From Ants to Humans:
The Three Stages of VLA Technological Evolution

Stage 1: Rule-Driven and "Insect Intelligence"
In the nascent stages of intelligent driving, systems relied on machine learning perception modules, coupled with high-precision maps and rule-based algorithms. Each submodule (perception, planning, control) required meticulous coupling and heavily depended on manually defined rules.
These systems resembled ants programmed to follow a set path, capable of "crawling" only within specific scenarios, devoid of genuine environmental understanding and generalization.
◎ Small-scale perception model parameters: Mere millions of parameters, severely restricting processing capabilities.
◎ Heavy dependence on maps: Functional collapse upon high-precision map failure.
◎ Lack of contextual understanding: Ineffective handling of unexpected scenarios (e.g., construction detours, human traffic direction).
Much like trained circus insects, they performed tasks within predefined orbits, lacking active decision-making and cognitive abilities.
Stage 2: End-to-End and "Mammalian Intelligence"
In 2023, Li Auto embarked on end-to-end (E2E) ADAS research, initiating real-vehicle deployment in 2024. The E2E model integrates perception and control processes, leveraging large-scale data-driven "imitation learning".
Models at this stage imitate human driving behavior, demonstrating preliminary generalization capabilities.
◎ Learning from human driving behavior: Models "drive by looking at pictures," perceiving scenes, and outputting driving instructions.
◎ Lack of causal reasoning ability: While imitating, models fail to comprehend the causal relationships behind actions.
◎ Preliminary introduction of VLM (Vision-Language Model): Assists models in understanding traffic signal semantics and limited textual information. However, due to low resolution in most open-source VLMs, their generalization remains insufficient.
The E2E system resembles a chimpanzee riding a bicycle: capable of task completion but lacking genuine understanding of traffic rules and logic. This "experience-driven" model still grapples with shallow understanding, weak reasoning, and limited generalization.
Stage 3: VLA (Driver-Level Model) and "Human Intelligence"
In the era of VLA, intelligent driving systems transcend being mere rule controllers or imitators, evolving into driving entities with "human-like thinking".
The VLA system embodies a true fusion of three capabilities:
◎ Vision: 3D vision + high-definition 2D images;
◎ Language: Traffic language understanding + internal CoT (Chain of Thought) reasoning chain;
◎ Action: Planning, decision-making, and execution of driving behavior.
Unlike traditional VLMs or E2E models, VLA not only "sees the world" but also "understands" and "acts," approaching human driver intelligence for the first time.
02
Technical Architecture Analysis:
How to Build a "Driver-Level Model"?
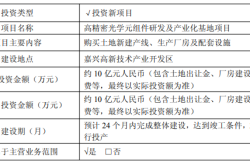
The pre-training stage aims to create a tightly integrated VL (Vision + Language) multimodal large model, serving as the foundation for VLA training.
The current model version scales to 32B (32 billion parameters), deployed on a cloud training platform.
This model integrates rich visual corpora, including 3D spatial perception and high-definition 2D images, with an image resolution 10 times higher than existing open-source VLMs, encompassing elements like long-distance recognition, traffic signs, and dynamic scenes.
Simultaneously, the language corpus encompasses driving instructions, road condition semantics, and behavioral rules, such as navigation information, human instructions, and driving idioms.
By embedding visual context and language semantics jointly, such as integrating navigation maps with driving behavior understanding and three-dimensional images with instruction logic, the goal is to construct a "multimodal world model" capable of understanding the physical world.
Post-pre-training, the 32B model is distilled into a 3.2B edge-side model to fit Orin-X or Thor-U hardware platforms. It adopts the MoE (Mixture of Experts) architecture, balancing efficiency and accuracy, ensuring real-time operation at over 40Hz frame rates, meeting automotive-grade deployment standards.
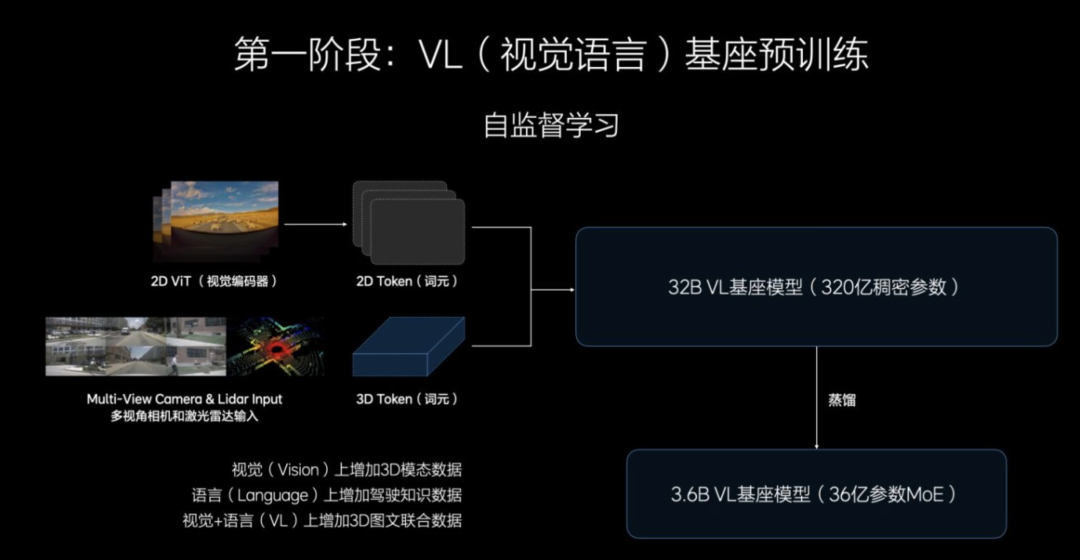
The post-training stage shifts focus to imitation learning, transitioning from understanding to action.
While pre-training equips the model with "seeing and hearing" abilities, this stage teaches it to "act".
Through large-scale human-vehicle co-driving data learning, the model imitates human driving behavior, learning trajectories, acceleration, braking, and other operations. Furthermore, generative behavior learning transcends regression prediction, capable of generating and optimizing trajectories.
The Task Integration Model (TAM) structure deeply integrates visual-language understanding with action generation, enhancing task execution efficiency.
Ultimately, a comprehensive VLA structure encompassing a full driving cycle is formed: from environmental perception, intention understanding, to driving behavior execution, constituting a closed-loop control system.
The model expands to 4B parameters, retaining the CoT (Chain of Thought) mechanism but limited to 2-3 steps to balance reasoning ability and system latency.

The reinforcement training stage emphasizes the transition from driving schools to real roads, focusing on human preferences and safety boundary control.
Unlike traditional RL methods, VLA's reinforcement training system introduces RLHF (Reinforcement Learning from Human Feedback). By involving humans in data annotation, a "human takeover - AI iteration" loop is established, incorporating soft targets like user preferences and road safety behavior habits.
The Diffusion prediction module anticipates environmental and trajectory changes within the next 4-8 seconds before executing actions, providing causal reasoning capabilities to support temporal domain decision-making.
This process mirrors a driver's transition from intern to professional, enabling VLA to not only drive but also handle real-world uncertainties safely and robustly.
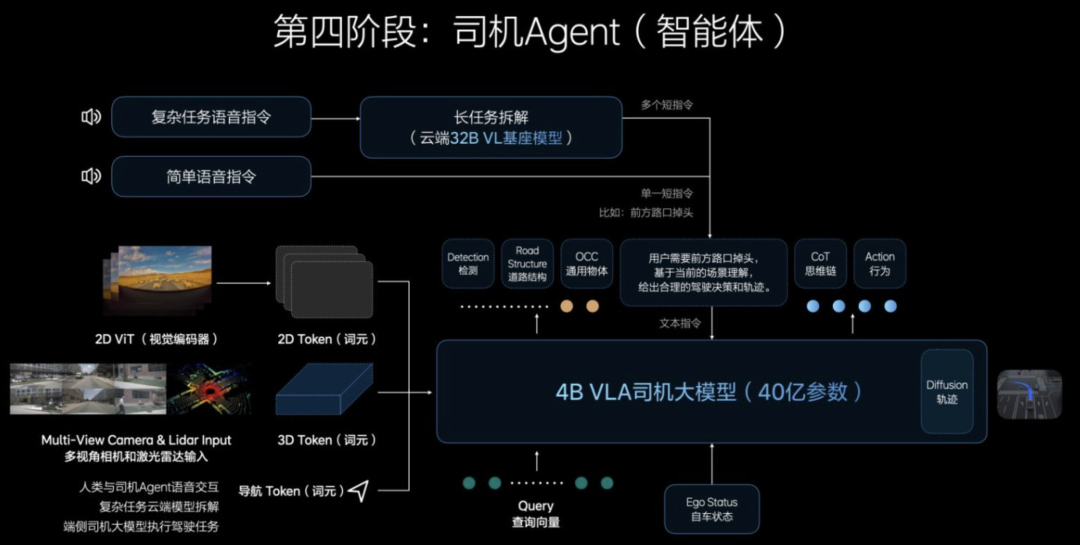
Within the VLA (Vision-Language-Action Model) system, the most groundbreaking and user-centric innovation lies in the construction of the "Driver Agent".
The "Driver Agent" is a "digital driver" with human-like driving intelligence. It not only sees clearly and understands but, crucially, comprehends road conditions, language instructions, and driving intentions, making rational action decisions. This represents the culmination of VLA's three-stage evolution.
Traditional perception + rule algorithms, akin to insects, react passively and follow simple instructions. While end-to-end models are smarter, resembling well-trained animals that imitate human behavior, they lack genuine world understanding.
Conversely, the Driver Agent in VLA integrates 3D vision understanding, language reasoning (CoT), and real-time action strategy learning. It translates natural language instructions like "Drive on the right at the next exit" into precise trajectory control, even making dynamic adjustments in unexpected scenarios. This means it not only sees traffic lights but also "understands" their semantics and strategic impacts.
The Driver Agent's construction hinges on three key training steps:
◎ Firstly, joint vision-language modeling based on the cloud-based 32B model to understand the 3D real world and high-resolution 2D images, establishing a "language-vision" nested structure within the traffic context;
◎ Secondly, action modeling through imitation learning on the edge-side 3.2B distilled model, learning to respond to visual semantics from human driving data;
◎ Finally, introducing human feedback through reinforcement learning (especially RLHF), enabling the system to learn not just "how to do" but also "how to avoid mistakes," thereby optimizing safety margins and driving habits, completing the transition from simulation to real-world application.
The Driver Agent in VLA is not a mere rule-stack but a generalized intelligent agent with short-chain reasoning capabilities (CoT) and multimodal collaborative decision-making abilities.
While maintaining real-time execution, it performs causal deductions like "if I accelerate now, the car in front might decelerate in 5 seconds" and selects approaches aligned with human driving styles based on trained behavioral preferences.
This "Driver Agent" symbolizes VLA's transition towards mass production: it's not a collection of models but a digital replica of driving behavior.
The maturity of this Agent will directly determine whether ADAS evolves from "feature stacking" to "driving substitution," truly becoming a trustworthy "co-pilot" for every user.
Summary
The significance of VLA extends beyond technology;
It's the key to unlocking the industry's future.
VLA's emergence is not merely a technical evolution but a crucial breakthrough for the ADAS industry amidst challenges. Today's ADAS faces myriad controversies: incomplete technology loops, weak generalization abilities, and frequent safety issues.
However, precisely because of these challenges, VLA emerged. It not only possesses "human-like cognition" but also implements an engineering path, achieving a highly anthropomorphic driving experience within controllable computational power. By integrating vision, language, and action, it takes the first step towards truly "commercializable and scalable" autonomous driving, from understanding the world to transforming it.
VLA is not an endpoint but a beginning. Just as the darkness before dawn will eventually pass, VLA heralds the transition of ADAS from an engineering prototype to an integral part of future society's infrastructure.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?