End-to-End Intelligent Driving Training Challenges: Breaking the "Model Illusion" with Missing Ground Truth Data in Sequential Frames
 07/04 2025
07/04 2025
 773
773
I. Introduction
As the capabilities of perception, decision-making, and control modules inch closer to their peak performance, end-to-end learning (End-to-End Learning) has garnered significant attention in the realm of intelligent driving. End-to-end models leverage deep neural networks to directly map raw sensor inputs to driving control signals, minimizing error propagation across intermediate modules. This approach holds promise for simplifying system architecture and enhancing overall coordination efficiency.
However, the practical implementation of end-to-end solutions in real-world scenarios falls short of expectations, plagued by issues such as poor training stability, limited generalization capabilities, and sluggish responses to extreme situations. From a training data perspective, this article focuses on a pivotal factor: high-quality sequential frame data with ground truth, exploring its role as a core resource for overcoming end-to-end training bottlenecks.
II. Basic Process of End-to-End Intelligent Driving Training
The core concept of the end-to-end intelligent driving model is to establish a mapping relationship between sensor inputs and vehicle control. Its training process typically encompasses the following key steps:
1. Data Collection and Preprocessing: Gather multimodal data from vehicles operating in real or simulated environments, including RGB images, LiDAR point clouds, IMU signals, CAN control data, and high-precision maps. These data are then synchronized in time, cleaned, and formatted to a standard.
2. Model Design and Training: Mainstream end-to-end models are primarily based on deep convolutional neural networks, Transformers, BEV (Bird's Eye View) representations, and other architectures. They can be categorized into perception-control fusion networks and trajectory regression networks. The training objective is to minimize the error between predicted control signals (or target trajectories) and actual human driver operations.
3. Evaluation and Validation: Evaluate the model through playback or closed-loop simulation, primarily assessing its robustness, smoothness, safety, and strategy rationality across different traffic scenarios.
Compared to traditional modular systems, end-to-end models theoretically offer superior overall coordination but demand higher data quality, particularly semantically consistent and temporally continuous training samples.
III. Analysis of Training Bottlenecks: Why is it Difficult to Implement End-to-End Models?
3.1 Scarcity of Scenarios and Long Tail Distribution
End-to-end models rely on extensive driving data to learn control strategies, but key decision-making scenarios on real roads (e.g., unprotected left turns, temporary construction, sudden lane insertions) are exceptionally rare, fitting the typical long tail distribution. Models rarely encounter these scenarios during training, leading to ineffective responses during testing or deployment.
Even with tens of thousands of hours of driving data, the absence of intensive collection and annotation of these "high-risk, high-complexity scenarios" results in models learning "mild and conservative" control strategies, hindering effective responses in rapidly changing traffic conditions. Furthermore, traditional collection methods primarily rely on natural driving processes, which may not efficiently cover all corner cases, further exacerbating the model's performance disadvantages in long tail issues.
More importantly, these scenarios often involve complex semantic relationships and multiple intent changes, such as construction sites accompanied by road narrowing, traffic police direction, and road surface reflection interference. Single-frame information struggles to capture the full semantic picture.
3.2 Lack of Temporal Modeling Capability
Many end-to-end methods utilize static inputs (e.g., single-frame images or short time windows), overlooking the fact that driving behavior inherently involves a continuous decision-making process with strong temporal correlations. The absence of temporal feature modeling leads to sluggish model responses in scenarios requiring advance prediction, manifesting as issues like "control drift" and "following instability."
For instance, in high-speed lane-changing scenarios, drivers typically plan their actions in advance by observing surrounding vehicle speeds and signaling behavior, rather than immediately deciding whether to change lanes based on the current frame. If the training data fails to provide state change information across consecutive frames, the model lacks learning of the "strategy evolution path" and is prone to "blind control" that only adapts to static decisions.
Additionally, behaviors such as emergency braking, obstacle avoidance, and continuous interactive yielding are essentially sequences of strategies rather than isolated single-frame responses, relying on cross-time modeling and behavioral memory.
3.3 Ambiguity and Uncertainty of Control Ground Truth
Compared to relatively clear labels in classification or detection tasks, driving control signals exhibit significant multi-solution characteristics. For example, in the same scenario, a driver can choose to slightly decelerate or change lanes, both of which are reasonable actions. Such supervisory signals are inherently ambiguous, easily causing uncertainty in the model's learning direction and oscillations during training.
Furthermore, different drivers exhibit varied behaviors under identical conditions, with individual styles, safety tolerances, and driving experience leading to different control strategies. The control behaviors learned by the model are prone to instability and excessive diversity, impacting the model's convergence effect and generalization performance.
There is also the issue of "inconsistent collection" of control data. For instance, due to GPS drift or CAN delay during collection, the label signals themselves may have offsets or fluctuations, further exacerbating error propagation during training.
3.4 Data Discreteness and Lack of Continuous Supervision
Currently, commonly used datasets such as nuScenes, Argoverse, and Waymo Motion only provide sparse frame annotations or short trajectory segments, lacking high-frequency continuous data segments. This data format makes it challenging for models to learn cross-temporal strategy evolution logic and achieve true "behavioral imitation."
For example, a vehicle's deceleration, attention, and search for an entry point before entering a roundabout, followed by decision-making within the roundabout and acceleration when exiting, all require multiple frames of continuous status presentation to fully express the strategy process. Discrete frames can only present the action results, lacking the context of state evolution, resulting in the model being unable to reason "why a certain action was taken."
Some driving behaviors (e.g., overtaking) also involve visual attention shifts, signal intent changes, interactive confrontation games, etc., which can only be revealed by continuous frames uncovering the underlying semantic trajectories.
3.5 Inconsistent Temporal Labels and Error Accumulation
In modular systems, each layer can perform error correction. However, in end-to-end systems, any time alignment errors or label jumps in the input data will be amplified layer by layer within the model, ultimately leading to significant deviations in the strategy output, especially in complex traffic interaction scenarios.
Furthermore, if the target IDs, trajectories, or intent annotations between consecutive frames are inconsistent, the model may mistakenly consider them as two entirely different events, further weakening its ability to model cross-frame semantics. The lack of a robust multi-frame time annotation mechanism also directly limits the performance of long temporal modeling structures such as Transformers in end-to-end training.
Currently, many data platforms still generate annotations on a frame-by-frame basis, lacking cross-frame entity consistency checks and interpolation reconstruction capabilities, leading to "frame skipping," "drifting," or even "disappearance" of the same target between frames, which are serious obstacles to visual tracking and intent modeling.
In summary, while current end-to-end models hold technical appeal, there are still significant bottlenecks in training stability, data requirements, and behavioral consistency modeling. The root causes of these problems often trace back to the lack of "sequential frame ground truth."
IV. Value and Role of Sequential Frame Data Ground Truth
In the training of end-to-end intelligent driving models, data is not merely "material" but the foundation of "supervisory signals." High-quality data sequences with temporal continuity and true semantic ground truth not only compensate for many structural deficiencies in end-to-end training but also gradually become the "first-order resource" for the system's practical application. This article systematically discusses its core value from the following four dimensions.
4.1 Basis for Driving Strategy Evolution Modeling
Intelligent driving is not a static task like image classification; it requires the model to not only recognize the current state but also predict the future based on the past and plan actions based on changes. Therefore, the "evolution trajectory of strategies" is crucial for understanding driving behavior. And this strategy path naturally needs to be presented through high temporal resolution sequential frame data.
Taking left-turn avoidance as an example, drivers typically go through a series of decision-making stages: "entering the intersection → observing oncoming vehicles → judging the speed difference → decelerating and waiting / directly crossing." If the data only provides a single-frame control signal at the moment of turning, the model will not understand why "waiting" or "turning" was chosen at that time and will find it even more difficult to learn the evolutionary logic behind the behavior.
Sequential frame data, combined with high-quality control and intent ground truth, allows the model to perceive the entire process from observation to action, thereby establishing a causal chain of strategies. This is a training cue that traditional discrete sampling data cannot provide.
Furthermore, with the aid of sequential frames, the model can construct cross-frame representations, such as trajectory differentials, velocity change rates, attention shift trends, etc., significantly enriching the input feature space and providing a more expressive state description for strategy prediction.
4.2 Improving Model Stability and Generalization Ability
One of the biggest challenges for end-to-end models is their sensitivity to data fluctuations, where "single-frame prediction errors" can lead to deviations in the entire control logic. Sequential frame data naturally has a "redundancy constraint" effect during training:
- Temporal Consistency: The states between consecutive frames are smooth, and control signals should transition gradually. During training, the model must satisfy both minimal spatial error and temporal coherence when fitting trajectories, which is equivalent to introducing an "implicit regularization" that can effectively suppress overfitting and overly aggressive predictions.
- Behavioral Constraint Bandwidth: In complex scenarios, consecutive frames record multiple performance stages of the same behavior, constituting "multi-view supervision." This allows the model to correct deviations in single-frame predictions through feedback from adjacent frames, thereby enhancing overall robustness.
- Semantic Extrapolation of Scarce Scenarios: For long-tail decisions such as "sudden U-turns by the lead vehicle" and "changing lanes due to traffic police directions," consecutive frames can reveal the context states before and after the event, helping the model transfer strategies from similar but non-identical scenarios, thereby improving generalization ability.
Based on actual engineering experience, when end-to-end models introduce a sequential frame training mechanism, the variation range of their trajectory deviation rates in urban loops decreases by about 20%-30%, with more stable performance in unstructured scenarios such as multi-vehicle interactions and sudden decelerations.
4.3 Supporting Behavioral Intent and Interaction Modeling
Sequential frames not only record changes in spatial states but also provide a window into behavioral evolution and intent manifestation. In urban traffic with frequent vehicle-road interactions, it is difficult to judge the "future trends" of other traffic entities through a single frame alone. The combination of sequential frame trajectories and semantic labels can construct clear behavioral intent supervisory signals, enhancing the model's perception and prediction capabilities in interactive scenarios.
For example, in the "intersection yielding" scenario:
- The direction and speed changes of pedestrians in sequential frames can infer their intent to "cross the street" or not.
- Whether oncoming vehicles decelerate or change lanes can predict whether they will "yield."
- The historical control trajectory of the ego vehicle can also influence future behavior prediction, such as a continuous change in braking force indicating "yielding is in progress."
These implicit intent information relies on high-quality sequential frame data for accurate extraction and annotation. Physical quantities such as speed, acceleration, and jerk over multiple frames can further assist the model in judging "whether to stop or accelerate," thereby making more logical decisions.
Some advanced end-to-end architectures even use behavioral intent as an intermediate explicit representation (e.g., Waymo's Multi-Agent Prediction network structure), modeling interactions through multi-target trajectory regression, all relying on trajectory and ID consistency labels of sequential frames as supervision.
4.4 Meeting the Training Requirements of Long Temporal Neural Networks
In recent years, long sequence neural network structures, such as Transformers, have been widely adopted in end-to-end driving learning, aiming to address the temporal modeling limitations of traditional CNN architectures. However, these models inherently require substantial "sequence samples" for support.
At a rate of 20 frames per second, a 10-second behavior segment encompasses 200 frames of images, CAN data, and annotations, necessitating consistent target IDs, continuous actions, and temporal alignment. The scarcity of high-quality consecutive frame samples significantly hinders the performance of such structures.
Furthermore, some models employ a sliding window mechanism to aggregate historical states, requiring labeled data to maintain a stable "causal chain input," where the initial 10 frames determine the current action. Issues such as occlusion, frame skipping, or missing annotations in intermediate frames can lead to the failure of the entire training segment.
In practical projects, utilizing datasets with 4D consecutive ground truth (3D spatial + temporal continuity) support can enhance the convergence speed of Transformer models by over 40%, significantly improving training stability. Without such data, some long sequence structures may struggle to train stably.
4.5 Facilitating Closed-Loop Deployment and Simulation Evaluation
High-quality consecutive frame data serves not only for model training but also provides robust support for subsequent model validation and deployment. Prior to closed-loop deployment, large-scale behavior playback and scenario replay validation of end-to-end strategies are typically conducted on simulation platforms. Only real behavioral data with temporal continuity can effectively drive the simulation system:
· Multi-vehicle traffic scenarios can be constructed based on real trajectories to reproduce scarce interactive behaviors.
· The model can be simulated to replace human drivers for the same path replay, comparing deviations between predicted trajectories and real trajectories to assess model behavior consistency.
· Scene variants can be created through interpolation, editing, and other methods to conduct stress tests on model strategy stability.
Moreover, during actual deployment, if the model exhibits "repetitive misjudgments" in certain scenarios, consecutive frame playback can be utilized to pinpoint the strategy collapse point, providing targeted samples for subsequent model retraining and data supplementation.
Therefore, consecutive frame data with high semantics, long temporal sequences, and consistent labels is pivotal not only for front-end training but also as a fundamental resource for the closed-loop development of end-to-end systems.
V. Representative Industry Practices and Case Analysis
In the exploration of end-to-end intelligent driving systems, leading technology companies and new carmakers have gradually recognized the core value of consecutive frame data and high-quality ground truth labels in model training. Both international autonomous driving pioneers like Waymo and Cruise, and leading Chinese intelligent driving forces such as Li Auto, Xpeng, Huawei, and Leado Intelligent, emphasize the collection, annotation, and utilization of continuous behavioral data in their technical routes or platform architectures.
5.1 Application Practices of International Leading Companies such as Waymo and Cruise
Waymo: Utilizing Multi-Frame Trajectory Supervision to Train Long-Term Strategy Models
Waymo places great importance on reconstructing "driver behavior patterns" in its end-to-end modeling. Its Motion data subset explicitly provides continuous time segments, encompassing detailed labels like target IDs, speeds, accelerations, and trajectory points. This enables the model to not only predict control commands for the current position but also regress target behaviors for the subsequent few seconds within a broader time window. Waymo has also proposed a data construction method of "multi-strategy sampling + interactive playback" in internal experiments to bolster the end-to-end model's ability to learn "multiple reasonable solutions" in complex traffic scenarios.
Cruise: Closed-Loop Playback and Replay to Strengthen Strategy Consistency
Cruise emphasizes using continuous data to replicate real driving state changes when training its urban end-to-end decision-making system. In its unique playback + simulation combined training process, the model predicts future action paths based on "given past behavior." This design encourages the model to shift from "immediate control" to "continuous intent generation." Cruise has also established a dedicated trajectory consistency metric to evaluate the alignment between the model's predictions and human driving strategies over time, further affirming the crucial supporting role of continuous data in strategy consistency.
5.2 Representative Domestic Path Practices: Li Auto, XPeng, Huawei, and Leadrive Smart
Li Auto: Constructing Temporal Learning Samples Based on Natural Driving Behavior Segments
Li Auto has deployed multiple lightweight end-to-end models in its L2+ system, with its data strategy centered around "behavior units." By clustering and analyzing natural driving trajectories and identifying behaviors, it extracts behavior sequences such as "lane changing and cutting in" and "entering and exiting ramps" to form complete temporal samples for training. Simultaneously, leveraging its self-developed multimodal data management platform, Li Auto achieves full-link synchronization of video, point cloud, trajectory, and control data, constructing a solid data foundation for end-to-end strategy training.
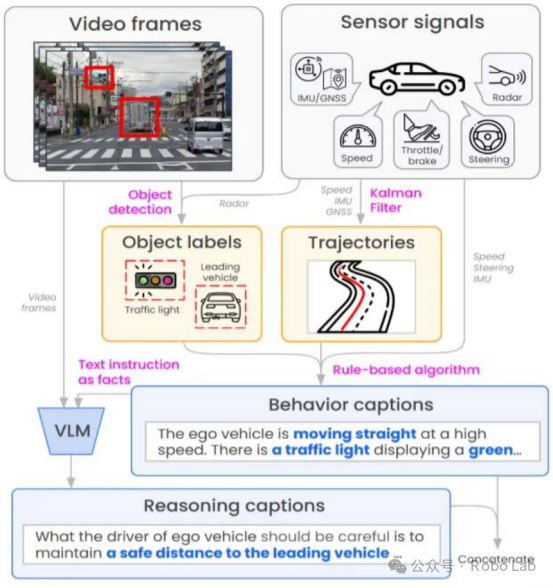
The VLM model automatically annotates video frames and sensor signals during the driving process to generate trajectories and other labels. Additionally, automatic description generation is applied to video frames to produce descriptions of actions and reasoning.
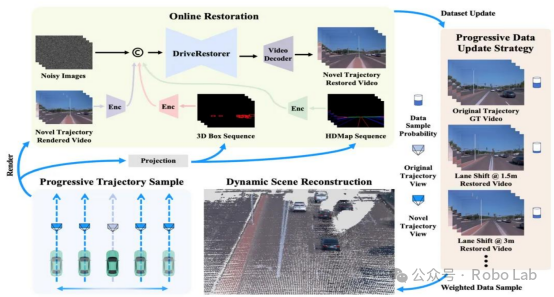
Li Auto Launches ReconDreamer World Model
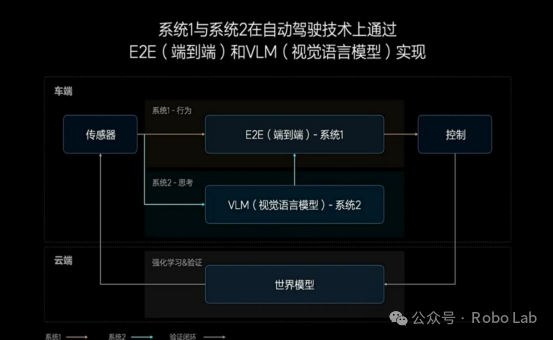
Li Auto's Dual-System Architecture
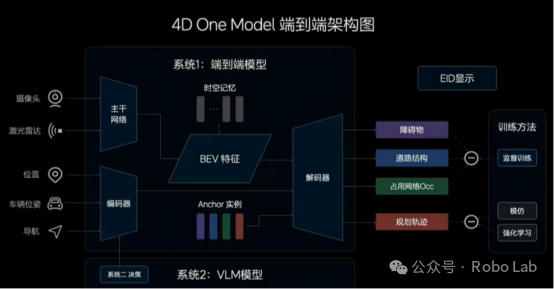

System 1 (End-to-End) & System 2 (VLM) Architecture
XPeng: BEV+Transformer Structure Fusing Continuous Frame Input
XPeng actively integrates BEV representation and temporal Transformer structure in its research on end-to-end perception-planning-control integration. Its training samples consist of 10-20 seconds of continuous frames, encompassing multi-level ground truth annotations such as target tracking IDs, semantic maps, and path deviations, significantly enhancing the model's stability in multi-vehicle interactions and dense urban road scenarios. Internal assessment data from XPeng indicates that after introducing continuous frame trajectory supervision, its trajectory prediction deviation decreased by approximately 27%, and the early intervention rate in "rear-end collision danger" scenarios increased markedly.

XPeng's XNGP Modular End-to-End Architecture

Mainstream End-to-End Architecture vs XPeng's End-to-End Architecture
Huawei Intelligent Automobile: Building a Full-Process Temporal Platform for End-to-End Training
Huawei upgrades its data closed-loop capability from static collection to "behavior segment level" continuous information extraction through its MDC platform. Its data platform supports millisecond-level time alignment of CAN, perception, positioning, maps, and other multimodal signals, and automatically identifies key decision events through a rules engine to output structured continuous label sequences. Meanwhile, Huawei adopts a "time window rolling prediction" mechanism on the training end, enabling the end-to-end model to adaptively perceive past state changes and dynamically adjust strategies, significantly improving following comfort and safety in urban commuting.
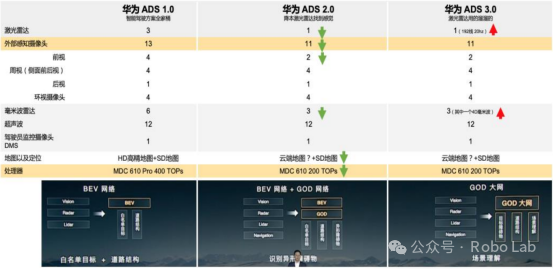
Evolution of Huawei's Intelligent Driving ADS Version
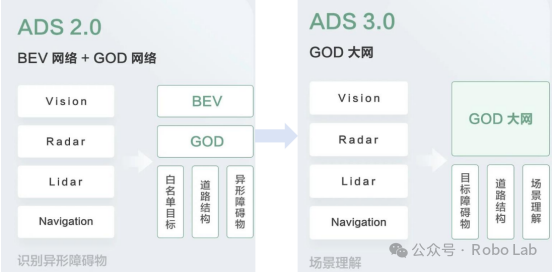
Algorithm Upgrade from ADS 2.0 to ADS 3.0

ADS 3.0 Adopts a Two-Stage End-to-End Architecture
Leadrive Smart: Providing Industrial-Grade 4D Continuous Frame Data Annotation Solutions
As a leading autonomous driving data service platform, Leadrive Smart has pioneered the construction of an industrial process system capable of producing "4D ground truth data" on a large scale in China. Its service capabilities are highlighted in the following aspects:
· Cross-modal Multi-frame Fusion Annotation Capability: Supports time synchronization, spatial alignment, and consistency verification of RGB, LiDAR, Radar, IMU, and other multi-source data, ensuring that each frame annotation is semantically closed in context.
· Temporal Consistency and Target ID Tracking Mechanism: Introduces multi-frame interpolation, trajectory reconstruction, and target tracking algorithms to achieve ID continuity and behavior consistency for key targets throughout the time period, meeting the training requirements of Transformer-like models.
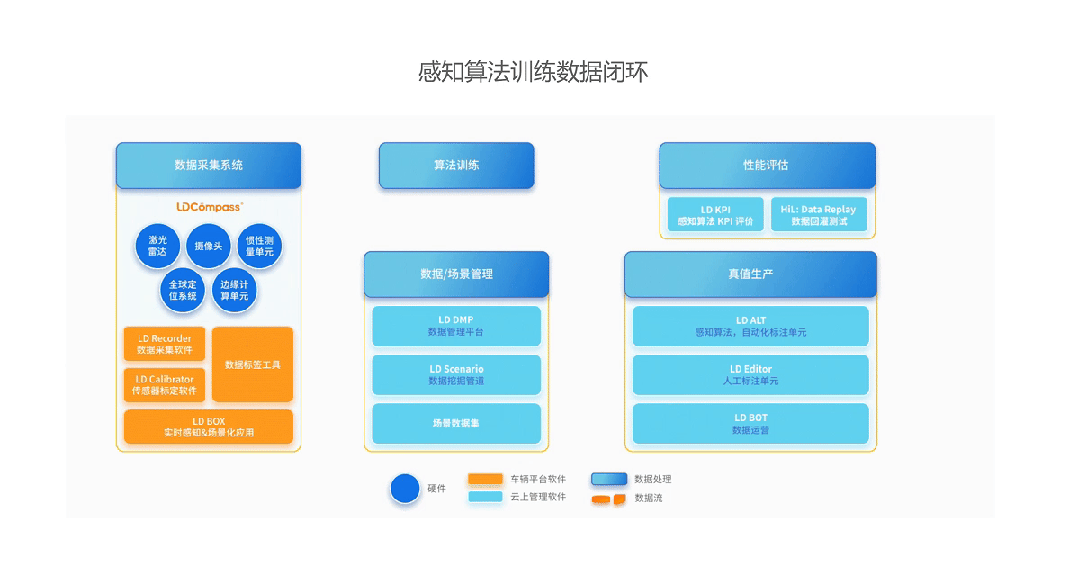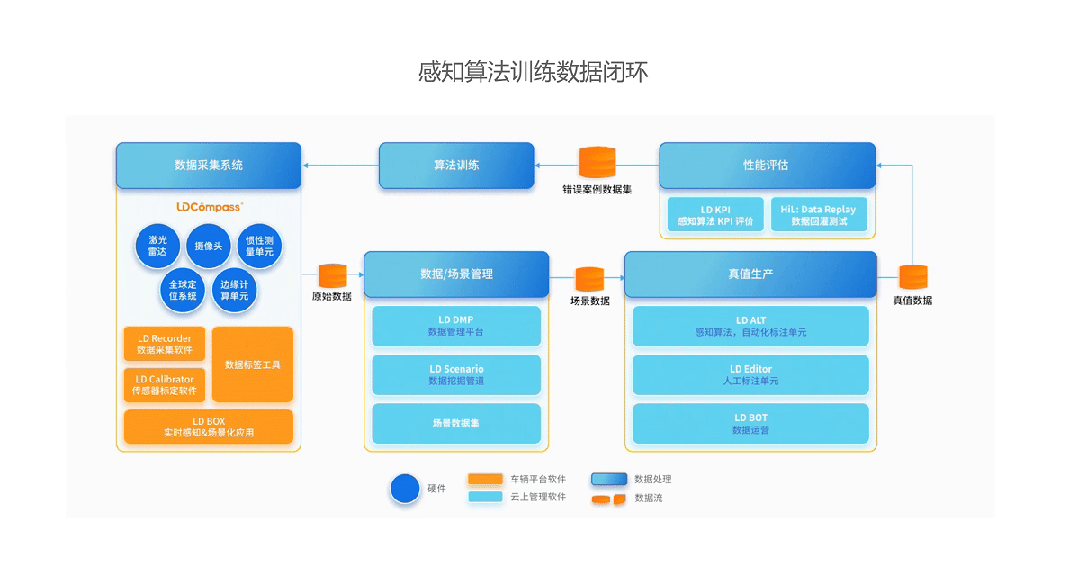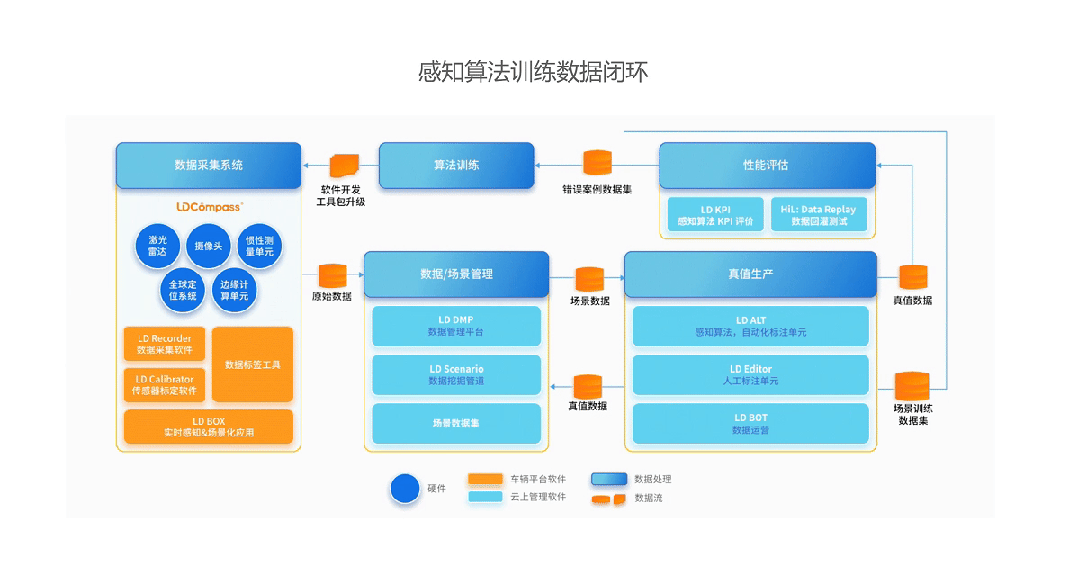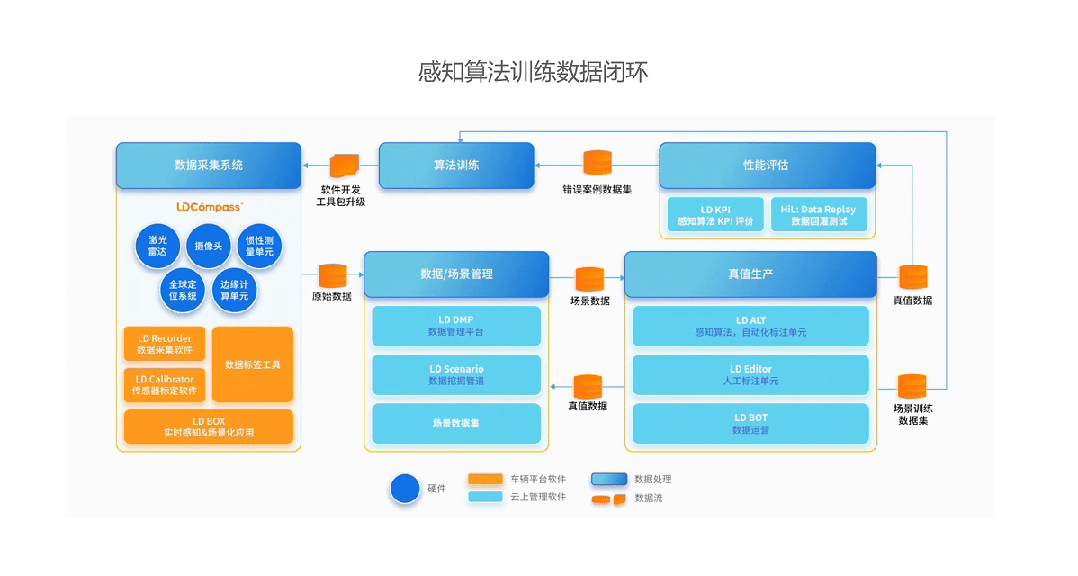
Leadrive Smart's Perception Algorithm Training Data Closed Loop
VI. Conclusion: From "Data Availability" to "Semantic Continuity"
The path to implementing end-to-end intelligent driving models ultimately involves continuously refining "behavior understanding" rather than merely stacking model structures. As mentioned, when models learn driving strategies holistically from perception, planning, and control, their data requirements shift from prioritizing "quantity" and "breadth" to emphasizing deeper levels of "continuity," "consistency," and "semantic completeness."
In this context, the value of continuous frame data lies not merely in simple time series stacking but also in the contextual logic it carries for scenario evolution. Only when data can genuinely represent the entire process of driving behavior from observation, judgment to execution can models potentially develop the ability to comprehend human strategic intentions.
Industry practices are also accelerating in this direction: from Waymo's trajectory replay to XPeng and Li Auto's high-fidelity sampling of natural behavior segments, to Leadrive Smart's 4D semantic annotation capabilities, upstream and downstream industries are gradually forming a training data ecosystem centered on "semantic behavior." This not only makes end-to-end models more robust and reliable but also provides fundamental support for constructing autonomous driving systems with "responsible boundaries" in the future.
Thus, it is more accurate to state that the challenge of "end-to-end" lies in redefining the data architecture rather than focusing solely on the model end. When we truly achieve the transition from "frame labels" to "behavior ground truth," the commercialization and large-scale implementation of end-to-end intelligent driving can progress from concept to reality.

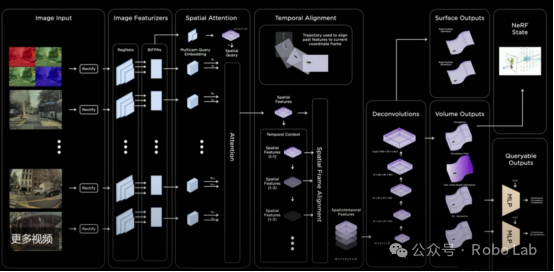
Tesla Released a Perception Algorithm Architecture Based on BEV+Transformer in 2021
Tesla Introduced Occupancy Networks in 2022
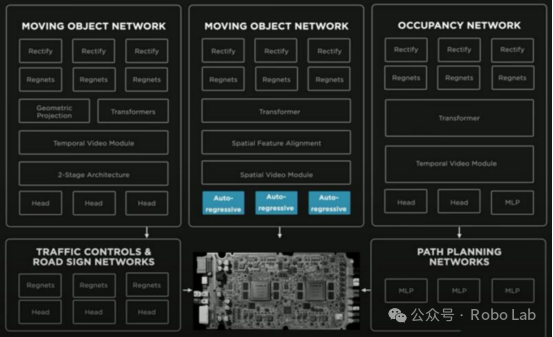
FSD Neural Network Summary
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




