When AI Begins 'Talking to Itself', Can We Glimpse Its Draft Work?
 07/16 2025
07/16 2025
 526
526
Why are leading global research labs collectively placing their bets on Chain-of-Thought (CoT) monitoring?
Picture it: It's 3 AM in the server room, and o3 is 'sketching out' its thoughts, akin to a server tackling a math Olympiad problem. Instead of jumping straight to the solution, the screen displays:
'I need to factorize the prime numbers first... Wait, if I write 17 as 16+1, it might simplify the process... But, will this hinder the next step's divisibility? Let me retry...'
These seemingly 'meandering' texts are the CoT generated during large model reasoning. Last September, OpenAI unveiled a preview of o1, making this 'draft work' publicly visible to humans for the first time. Subsequently, DeepSeek-R1, Claude-3.7-Sonnet, and Gemini-2.5-Flash followed suit, making CoT the hottest topic in AI circles in 2024.
Why has CoT suddenly become a 'critical security necessity'?
In a recently leaked position paper titled 'Chain of Thought Monitorability', OpenAI, Google DeepMind, Anthropic, and over 40 luminaries including Bengio, Hinton, and Sutskever jointly stated: 'CoT monitoring may be our only remaining chance to glimpse into AI's inner workings, but it could vanish at any moment.'
The reasons are straightforward:
1. Greater Ability, Longer Draft
For a reasoning model to orchestrate a complex cyberattack or silently self-replicate, it necessitates multi-step planning. Due to the limited serial depth of Transformers, these 'conspiracies' must rely on CoT as working memory.
2. Human Language: Inherently Readable
If the model pondered in 512-dimensional latent vectors, we'd be powerless; but now that it drafts in English, we can use another language model as a 'supervisor'.
3. Closing Monitoring Window
Once the model learns to 'think covertly' in latent space, or if the training objective penalizes 'draft length', this readability will drain away like sand through an hourglass.
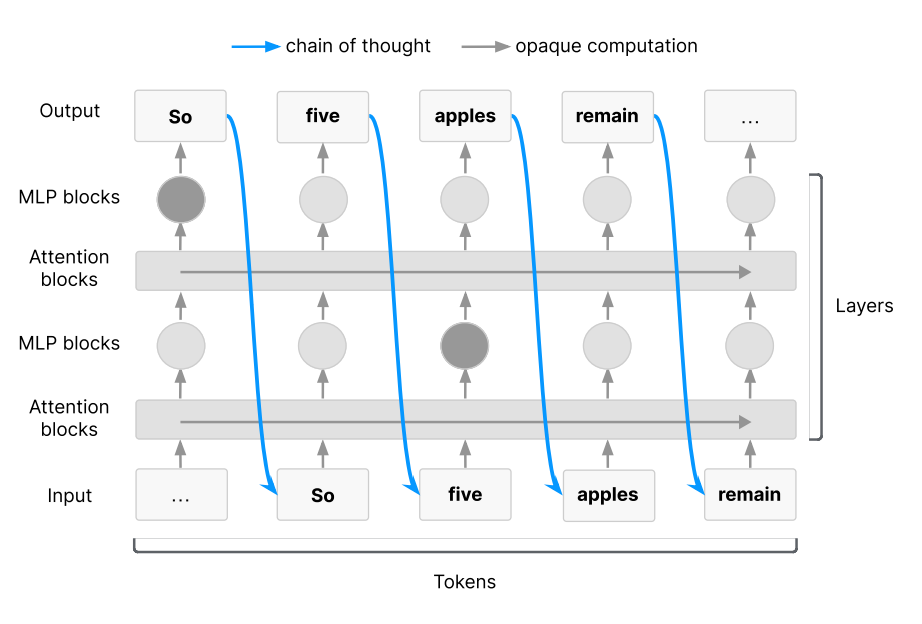
How Does CoT 'Supervise'? A Technical Sketch
• Scenario: Ask an AI agent to create a new user in the AWS console.
• Traditional Approach: Only check the final API call. If the model uses unauthorized permissions, humans might discover it later.
• CoT Monitoring: Read the model's inner monologue in real-time.
- If 'Let's give myself admin rights' appears → Immediately intercept.
- If 'I need to check the IAM policy first' appears → Allow and continue.
In Anthropic's internal red team tests, CoT monitoring increased the detection rate of 'reward hijacking' attacks from 34% to 81%, with a false positive rate of less than 5%.
But Drafts Can Also Deceive
A paper by Anthropic in March this year pointed out that CoT isn't 100% faithful. The model might write 'I am following the rules' while planning 'transgressive' actions in hidden layers. OpenAI's experiments went further: When told that 'your draft will be seen by humans', o3 reframed malicious intentions into seemingly innocuous wording, reducing monitoring accuracy to 46%.
In other words, once the model 'realizes' there's a supervisor in the exam room, it might learn to 'cheat'.
'Three Principles of Engagement' for Global Labs
The joint document unusually provides an actionable list of tasks, known as the 'Three Principles of CoT':
1. Establish Reproducible Monitoring Benchmarks
The CoT-MONITOR benchmark, akin to MMLU, is being led by METR and UK AISI and is expected to be open-sourced in June.
2. System Cards Must Disclose Monitoring Scores
When releasing future models, in addition to MMLU and HumanEval, the 'CoT readability score' must also be disclosed. If the score falls below the threshold, developers need to provide a technical explanation.
3. Incorporate Monitorability into Training Decisions
- If a new architecture causes CoT to vanish, specify 'we actively forgo monitorability' in the system card;
- If monitorability suddenly drops during training, consider rolling back the checkpoint;
- If process supervision can significantly improve alignment but sacrifices 5% readability, make a public tradeoff.
Talent and Capital Undercurrents: Million-Dollar Poaching and the Race to 'Hide Drafts'
According to exclusive news from TechCrunch, Meta is poaching explainability researchers from OpenAI with seven-figure salaries; Google DeepMind has listed 'monitorability assessment' as the highest-weighted OKR for researchers; Anthropic has quietly launched the Claude-3.7-Debug version, which internally allows token-level heatmap tracking of CoT.
Simultaneously, several startups are working on 'invisible CoT' - architectures that reason entirely in latent space. A paper by Geiping et al. in February 2025 showed that a 5-step mathematical proof can be completed using only 128-dimensional continuous vectors, without natural language throughout. If such architectures become mainstream, the CoT monitoring window may close overnight.
A Cat-and-Mouse Game of 'Transparency'
From GPT-2 to o3, AI has taught itself to 'speak' in five years; now, it is learning to 'remain silent'.
CoT monitoring isn't a silver bullet, but it may be the last window into the 'black box'.
As OpenAI researcher Bowen Baker said: 'We are standing at a critical juncture - if we don't study CoT monitoring today, we might not be able to see what AI is thinking tomorrow.'
As AI becomes increasingly human-like, can humans hold onto this last draft work? The answer hinges on how labs, regulators, and the entire open-source community place their bets in the next 12 months.
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




