Manus: Co-Founder Shares Insights After Controversies, Layoffs, and Relocation to Singapore
 07/25 2025
07/25 2025
 735
735

Edited by Key Point Master
From global acclaim to successful funding, to controversies surrounding deleted posts, layoffs, and relocating to Singapore, Manus has exemplified the rollercoaster journey of a startup in an emerging sector within just four months.
Some critics argue that Manus set a poor precedent by leveraging Chinese engineers to create products, quickly raising funds, and then laying off employees and relocating.
Amidst the uproar, early this morning, the company's co-founder Ji Yichao made a rare and lengthy blog post, aiming to redirect public attention towards the product and technology itself, and for the first time publicly addressing the key lessons learned from this tumultuous rise and fall.
Four Months: From Fame to Controversy
Let's briefly recap. In March this year, Manus gained popularity as the "world's first universal Agent," with some comparing it to China's "second DeepSeek moment."
In May, Manus swiftly completed a $75 million Series B funding round led by Benchmark, a top Silicon Valley venture capital firm, pushing its valuation to $500 million. The world had high hopes for this startup.
However, at the end of June, Manus was suddenly hit with multiple controversies: employees claimed they were laid off without warning, the founding team deleted numerous posts on social platforms, and the company's main entity moved to Singapore, sparking outrage.
For a while, deleting posts, layoffs, and fleeing became the primary labels associated with this promising Agent startup.
Co-Founder Posts Lengthy Article in the Early Morning
Faced with external scrutiny, Ji Yichao chose to respond with a detailed, technically-oriented article, systematically summarizing the team's core understanding of Agent products and technology for the first time:
1. **Contextual Engineering over End-to-End Self-Developed Large Models**: After attempting to train NLP models from scratch and being outpaced by large models like GPT-3, Manus chose not to develop the underlying model but to focus on maximizing the capabilities of open-source or commercial large models through "contextual engineering".
2. **KV Cache Hit Rate as a Core Indicator**: Unlike single-round chats, multi-round intelligent agents may have an input-to-output ratio as high as 100:1, significantly affecting latency and inference costs. The goal of context design is to maximize the KV cache hit rate, requiring stable prompts, appending rather than modifying context, and ensuring that prefixes can be reused.
3. **Masking Instead of Deletion in Tool Management**: Dynamically adding or removing tools can invalidate the cache. Manus manages tool availability using a context-aware state machine by masking token probabilities rather than directly removing them from the context, maintaining flexibility while preserving the cache.
4. **File System as Infinite Context**: Large models have limited context windows, and excessively long contexts can slow down inference speed and increase costs. Manus treats the file system as the agent's external memory, allowing information to be accessed at any time, ensuring historical states can be checked, read/written, and restored.
5. **Explicit "Recitation" Mechanism**: In long tasks, Manus automatically generates a todo.md, breaking down tasks into executable lists and continuously updating them, repeatedly writing the goals at the end of the context, equivalent to "repeatedly reminding the model" to avoid deviation.
6. **Retaining Failure Information**: Intelligent agents will make mistakes. Leaving failure information in the context allows the model to "see" the failure path, forming negative examples, thereby reducing similar errors.
7. **Summary**: Contextual engineering is an emerging experimental science. Manus aims to shape the behavior and capabilities of agents through context, not competing on model intelligence, but on making the model more useful.
Beyond the Review, Controversy Continues
This blog post demonstrates that Manus is not merely a "PPT project." It did conduct considerable underlying exploration for Agent scenarios and encountered many pitfalls.
However, the lengthy article does not address the questions most concerning to the public: Why did the company move to Singapore? How were the laid-off domestic employees handled? Ji Yichao did not answer these questions, nor were they mentioned in the blog post.
Ji Yichao concluded: "The future of intelligent agents will be gradually built one scenario at a time. Carefully design each scenario."
The current reality is whether Manus still has the opportunity to bring these "scenarios" from technical documents back to real users. Nothing is certain yet.
Blog Post Link:

Below is the original text of the blog post by Manus co-founder Ji Yichao (translated by GPT):
Contextual Engineering for AI Agents: Lessons Learned from Building Manus
July 18, 2025, Ji Yichao
At the inception of the Manus project, my team and I faced a pivotal decision: should we train an end-to-end agent model using open-source base models or build agents based on the contextual learning capabilities of state-of-the-art models?
Looking back at my first decade in natural language processing, we didn't have such choices. In the early days of BERT (yes, it's been seven years), models had to be fine-tuned and evaluated before being transferred to new tasks. Despite being smaller than today's LLMs, this process often took weeks per iteration. For rapidly evolving applications, especially in the early stages of product-market fit, such a slow feedback cycle was detrimental. This was a painful lesson from my previous startup, where I trained models from scratch for open information extraction and semantic search. Then GPT-3 and Flan-T5 emerged, rendering my self-developed models obsolete overnight. Ironically, these models ushered in a new era of contextual learning—and opened a new path for us.
This hard-won lesson made the choice clear: Manus would focus on contextual engineering. This allowed us to release improvements within hours instead of weeks, while keeping our product orthogonal to the underlying model: if model progress is the rising tide, we want Manus to be the boat, not a pillar fixed to the seabed.
However, contextual engineering is far from simple. It is an experimental science—we have rebuilt the agent framework four times, each time discovering a better way to shape context. We affectionately refer to this manual architecture search, prompt tuning, and empirical guessing process as "stochastic gradient descent." It's not elegant, but it works.
This article shares the local optimal solutions we have reached through our own "SGD." If you are building your own AI agents, I hope these principles can help you converge faster.
Designing Around KV Cache
If I could choose only one metric, I believe the KV cache hit rate is the most crucial indicator for AI agents in production. It directly affects latency and cost. To understand why, let's first examine how a typical agent works:
After receiving user input, the agent completes tasks through a series of tool calls. In each iteration, the model selects an action from a predefined action space based on the current context. The action is then executed in the environment (e.g., Manus's virtual machine sandbox) to produce observations. The action and observations are appended to the context, forming the input for the next iteration. This loop continues until the task is completed.
As you might imagine, the context grows with each step, while the output—typically structured function calls—is relatively short. This makes the ratio of pre-filling to decoding much higher in agents compared to chatbots. For example, in Manus, the average input-to-output token ratio is about 100:1.
Fortunately, contexts with the same prefix can leverage KV caching, significantly reducing the first token generation time (TTFT) and inference cost—whether you are using a self-hosted model or calling an inference API. The savings here are substantial: For instance, with Claude Sonnet, cached input tokens cost $0.30/k tokens, while uncached tokens cost $3/k tokens—a tenfold difference.
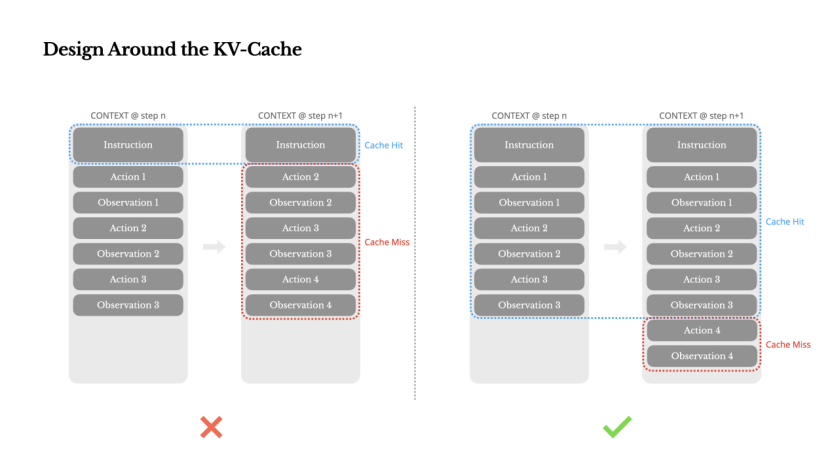
From a contextual engineering perspective, improving the KV cache hit rate involves several key practices:
Keep the prompt prefix stable. Due to the autoregressive nature of LLMs, even a single token difference can invalidate that token and subsequent cache. A common mistake is including a timestamp at the beginning of the system prompt—especially one precise to the second. While this allows the model to tell you the current time, it also significantly reduces the cache hit rate.
Make your context append-only. Avoid modifying previous actions or observations. Ensure your serialization is deterministic. Many programming languages and libraries do not guarantee stable key order when serializing JSON objects, which can silently break caching.
Explicitly mark cache breakpoints when needed. Some model providers or inference frameworks do not support automatic incremental prefix caching but require manually inserting cache breakpoints into the context. When setting these breakpoints, consider scenarios where the cache might expire, ensuring at least that the breakpoint contains the end of the system prompt.
Additionally, if you self-host models using frameworks like vLLM, ensure that prefix/prompt caching is enabled and use techniques like session IDs to consistently route requests across distributed worker nodes.
Mask, Don't Remove
As your agent's capabilities grow, its action space naturally becomes more complex—in simple terms, the number of tools skyrockets. The recent popularity of MCP has only fueled this. If users are allowed to customize tools, trust me: someone will inevitably connect hundreds of mysterious tools to your carefully planned action space. As a result, the model is more likely to choose the wrong action or take an inefficient path. In short, your heavily loaded agent becomes less intelligent.
A natural response is to design a dynamic action space—perhaps using a RAG-like approach to load tools on demand. We tried this in Manus. But experiments showed a clear rule: avoid dynamically adding or removing tools during iterations unless absolutely necessary. There are two main reasons:
In most LLMs, tool definitions are typically located at the front of the context after serialization, usually before or after the system prompt. Therefore, any changes invalidate the KV cache for all subsequent actions and observations.
When previous actions and observations still reference tools no longer defined in the current context, the model becomes confused. Without constrained decoding, this often leads to mode violations or hallucinated actions.
To solve this problem and improve action selection effectiveness, Manus uses a context-aware state machine to manage tool availability. Instead of removing tools, it masks the log probabilities of tokens during decoding to prevent (or force) the selection of certain actions based on the current context.
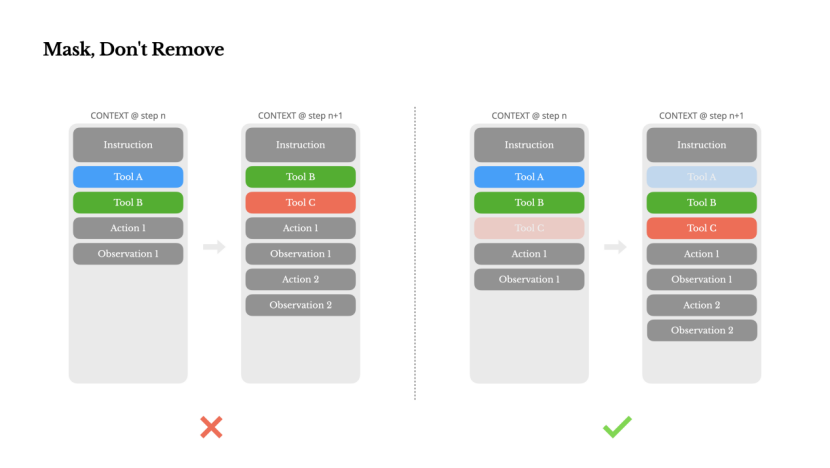
In practice, most model providers and inference frameworks support some form of response pre-filling, allowing you to restrict the action space without modifying tool definitions. Function calls typically have three modes (we use NousResearch's Hermes format as an example):
Automatic – The model can choose whether to call the function. Implemented by only pre-filling the response prefix: <|im_start|>assistant
Required – The model must call a function, but the selection is unrestricted. Implemented by pre-filling up to the tool call token: <|im_start|>assistant
Specified – The model must call a function from a specific subset. Implemented by pre-filling up to the beginning of the function name: <|im_start|>assistant{"name": “browser_
Using this method, we restrict action selection by directly masking token log probabilities. For example, when a user provides new input, Manus must immediately respond rather than execute an action. We also intentionally designed action names with consistent prefixes—for example, all browser-related tools start with browser_, and command-line tools start with shell_. This allows us to easily ensure that the agent only selects from a certain group of tools in a specific state without using stateful log probability processors.
These designs help ensure the stability of the Manus agent loop—even under a model-driven architecture.
Using the File System as Context
Modern state-of-the-art LLMs now offer context windows of 128K tokens or more. However, in real-world intelligent agent scenarios, this is often insufficient and sometimes even a burden. There are three common pain points:
Observations can be very large, especially when agents interact with unstructured data like web pages or PDFs. It's easy to exceed context limits.
Even if the window is technically supported, model performance often degrades beyond a certain context length.
Long inputs are costly, even with prefix caching. You still need to pay for transmitting and pre-filling each token.
To address this challenge, numerous agent systems employ context truncation or compression tactics. However, excessive compression invariably results in the loss of vital information. The crux of the matter lies in the fact that agents inherently rely on all prior states to predict the next action—and it's impossible to accurately foresee which observation might become crucial ten steps ahead. Logically, any form of irreversible compression introduces risks.
This is precisely why we regard the file system as the ultimate context in Manus: it is infinitely large, inherently persistent, and directly manipulable by the agent itself. The model learns to write and read files on demand, leveraging the file system not merely as storage but as a structured external memory.
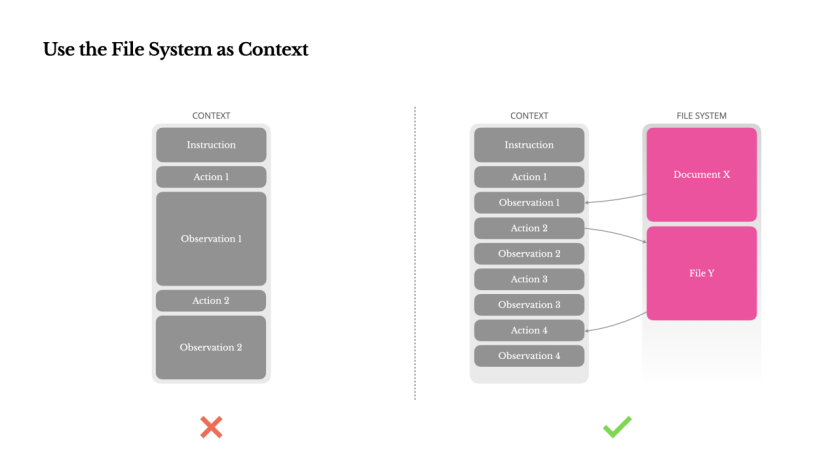
Our compression strategy is meticulously designed to ensure recoverability. For instance, as long as the URL is retained, the web page content can be removed from the context; similarly, if the document path remains in the sandbox, the document content can be omitted. This approach allows Manus to shorten the context length without permanently sacrificing information.
While developing this feature, I couldn't help but ponder the conditions under which state space models (SSMs) can effectively operate in an agentic environment. Unlike Transformers, SSMs lack a comprehensive attention mechanism and struggle with long-distance backward dependencies. However, if they can master file-based memory—externalizing long-term states rather than maintaining them within the context—their speed and efficiency might usher in a new generation of agents. Agentic SSMs have the potential to become the true successors to neural Turing machines.
Manipulating Attention Through Recital
If you've used Manus, you might have observed an intriguing phenomenon: when tackling complex tasks, it tends to create a todo.md file and gradually update it as the task progresses, checking off completed items.
This is not merely a cute behavior; it's a deliberate mechanism for manipulating attention.
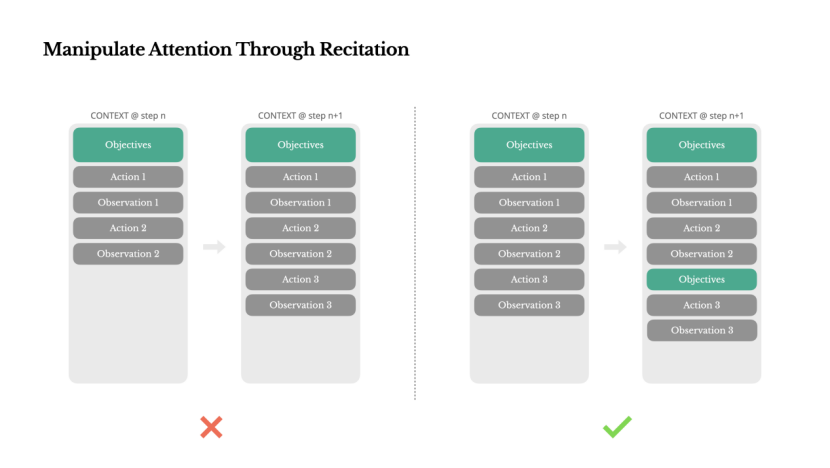
A typical task in Manus requires an average of around 50 tool invocations, forming a lengthy loop. Since Manus relies on LLMs for decision-making, it's prone to wandering off-topic or forgetting prior goals in long contexts or complex tasks.
By continuously rewriting the to-do list, Manus repeatedly writes its goals at the end of the context. This strategy pushes the global plan into the model's recent attention range, preventing the issue of "getting lost halfway" and reducing goal inconsistency. Essentially, it employs natural language to guide itself towards focusing on task goals, without necessitating specialized architectural changes.
Preserving Error Information
Agents make mistakes. It's not a bug; it's a fact of life. Language models can hallucinate, environments can return errors, external tools can throw exceptions, and unexpected edge cases frequently arise. In multi-step tasks, failure is not an exception; it's an integral part of the process.
However, there's a common tendency to conceal these errors: cleaning up traces, retrying operations, or resetting model states, hoping for the "magic" of temperature parameters. While this may seem safer and more controllable, there's a cost: erasing failure erases evidence. Without this evidence, the model cannot adapt.
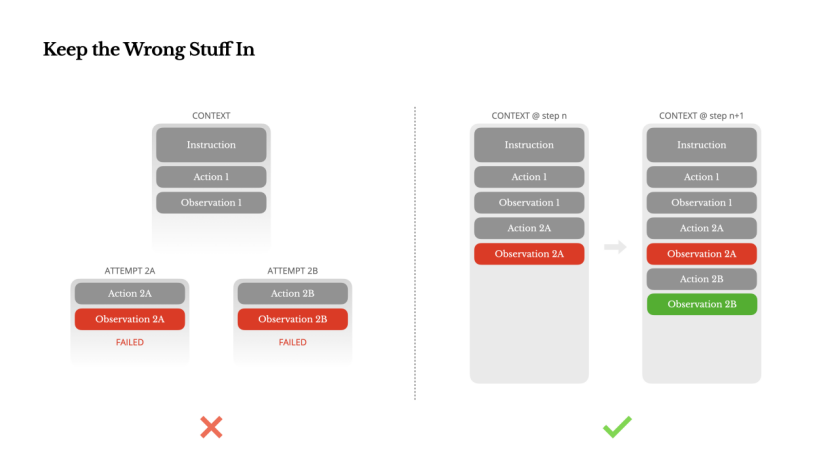
Based on our experience, one of the most effective ways to enhance agent behavior is surprisingly simple: preserve the error path within the context. When the model encounters failed operations and the resulting observations or stack traces, it implicitly updates its internal beliefs. This biases its priors away from similar actions, reducing the likelihood of repeating the same mistake.
In fact, we believe that error recovery is one of the clearest indicators of truly agentic behavior. Yet, this metric is often overlooked in academic research and public benchmarks, which tend to focus on task success rates under ideal conditions.
Avoiding the Pitfalls of Limited Examples
Few-shot prompting is a common technique to improve LLM outputs. However, in agentic systems, it can subtly backfire.
Language models excel at imitation; they replicate behavioral patterns from the context. If your context is replete with similar past action-observation pairs, the model is likely to follow that pattern, even if it's no longer optimal.
This can be perilous in tasks involving repeated decision-making or operations. For instance, when using Manus to review a batch of 20 resumes, the agent often falls into a rhythm, repeating similar actions merely because similar content appears in the context. This leads to deviations, overgeneralizations, and even hallucinations at times.
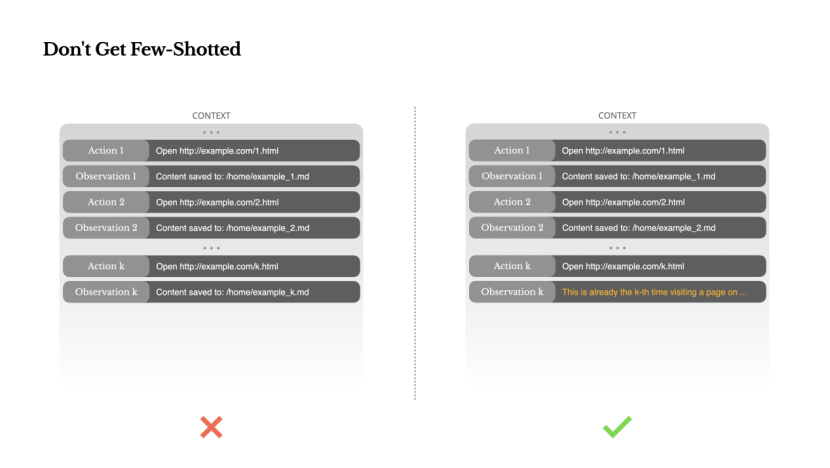
The solution lies in increasing diversity. Manus introduces small, structured variations in actions and observations—different serialization templates, alternative expressions, slight noise in order or format. This controlled randomness helps break patterns and adjust the model's attention.
In other words, don't let a limited number of examples confine you to a fixed pattern. The more uniform the context, the more fragile the agent becomes.
Conclusion
Context engineering is still an emerging field, but it's already pivotal for agentic systems. Models may become more powerful, faster, and cheaper, but no amount of raw ability can replace the need for memory, environment, and feedback. How you shape the context ultimately determines the agent's behavior: speed of operation, ability to recover, and scope for expansion.
At Manus, we've learned these lessons through numerous rewrites, dead ends, and real-world testing among millions of users. What we're sharing here isn't a universal truth, but patterns that have proven effective for us. If they help you avoid even one painful iteration, then this article has served its purpose.
The future of intelligent agents will be built step by step, scenario by scenario. Craft each scenario with care.
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




