90% Devoured by Large Models: The Dilemma of AI Agents
 07/25 2025
07/25 2025
 631
631

"90% of Agents will be devoured by large models."
On July 15, Zhu Xiaohu, managing partner at GSR Ventures, made another startling claim, this time focusing on the hottest topic in the AI world over the past year: Agents.

Midway through the "Year of Agents," recent news and assessments have been largely pessimistic. Last week, Manus relocated its headquarters to Singapore, laid off 80 employees in China, and abandoned plans to launch a domestic version, sparking public debate about the company's challenges.
Backed by Benchmark, a USD fund, and featuring overseas models like Gemini and Claude in its underlying architecture, Manus' departure, amid rumors of computational resource shortages, highlights forced relocation and adjustment due to circumstances, rather than a retreat due to operational failure.
However, the clouds hovering over general Agents, led by Manus, have yet to dissipate: on one hand, Manus and Genspark are experiencing declines in revenue and monetization; on the other, user activity is falling.
This situation reveals the core issue in the current general Agent sector: after the technological excitement and capital frenzy, products have yet to find killer applications that can sustain the loyalty and payments of a vast C-end user base, being used only occasionally for half-baked PPTs or research reports.
The general Agent market is being eroded by the spillover of model capabilities and losing market share to vertical Agents.
Overseas Turnaround: What's Wrong with Manus?
General Agents have fallen into an awkward situation.
In just a few months, the initial allure of general Agents has faded: in the enterprise context, they can't match the precision of vertical Agents; in individual hands, they haven't found scenarios that more accurately hit user needs.
The enhancement of model capabilities first dealt a blow to Agents.
With the rapid development of large model capabilities, models are becoming increasingly "Agent-like." As model performance spills over, users can directly invoke models to complete tasks.
Taking AI coding, which is currently progressing more rapidly, as an example, models like Anthropic's Claude and Google's Gemini series are improving their coding abilities with each update. Their self-developed coding tools (e.g., Claude Code) not only enable autonomous programming and optimize various product experiences but also support users to freely invoke their models through a Max membership model. Even Opus 4, which charges $75 per million output tokens, supports unlimited use for $200 per month.
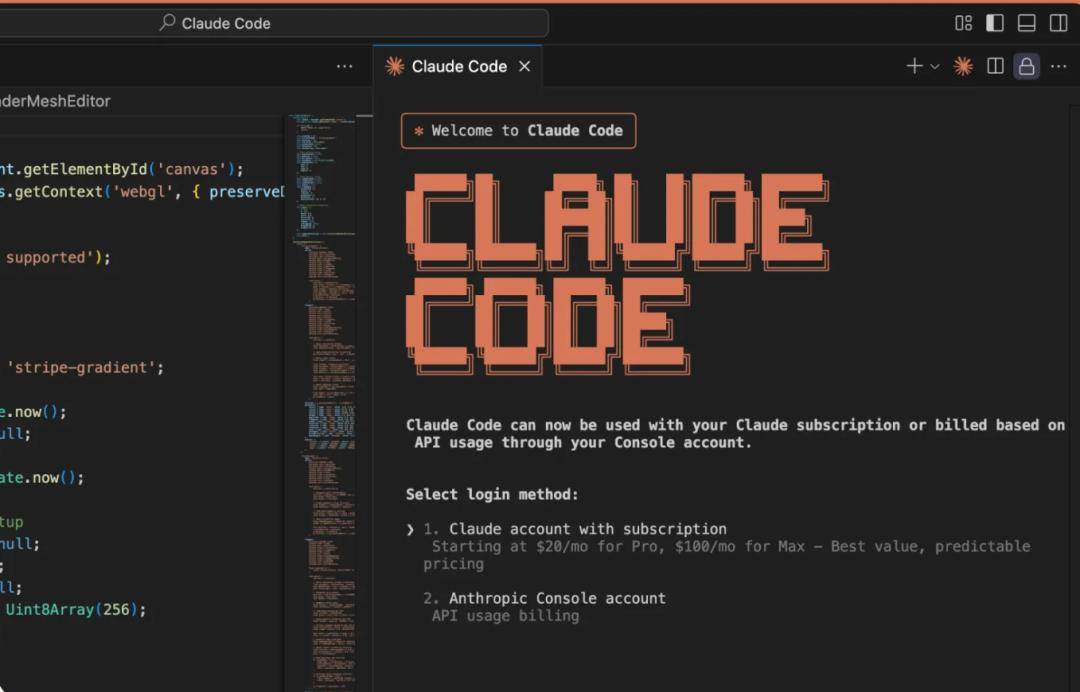
Compared to Manus' most expensive Pro membership, which costs $199 per month, although the prices are similar, Manus' top-tier membership still operates on a points-based consumption system. The Pro membership provides daily bonus points + 19,900 points per month + 19,900 limited-time points, serving users through a points-based system for task consumption. Estimating at 100 points per task, the daily usage limit is around 10 times.
The cost issue constraining Manus is transferred to users as an unremovable high subscription price.
When models themselves can provide an experience close to that of Agents, users will naturally prefer to directly use cheaper and more convenient model APIs or conversation interfaces rather than paying extra for a general Agent product with overlapping functionality. This results in a portion of the market share being directly "eaten" by increasingly powerful base models.
For end-users, compared to vertical Agents, general Agents perform poorly in enterprise applications, failing to reach the level of "digital employees" in terms of efficiency and results.
Zhu Xiaohu said that "90% of the Agent market will be devoured," but his own GSR Ventures has also participated in financing AI Agent projects. He is just more optimistic about products that can truly demonstrate efficiency and practical implementation compared to general Agents.
GSR Ventures-invested Head AI (formerly Aha Lab) is a company that uses AI Agents for automated marketing, now upgraded to an AI marketing product. In the words of its founder, you only need to tell Head your budget and website, and it can automatically handle influencer marketing, affiliate marketing, and cold emails—one person managing an entire marketing department.
For enterprise users, accuracy and cost are core demands. However, general Agents currently can't compete with vertical Agents optimized for specific scenarios.
If the same task is assigned to a general Agent and an internal vertical Agent within a company, the former can only provide results by combining search engines with requirements, while the latter connects to a well-established knowledge base within the company, outputting results tailored to internal information and requirements. It's like the latter has a more abundant database "tied" to it, and the outcome is self-evident.
When introducing new technologies, enterprises have extremely high requirements for cost and risk control. General Agents are typically based on large and complex "black box" models with non-transparent decision-making processes and a certain degree of randomness in output results (i.e., the "hallucination" problem). Enterprises with higher accuracy requirements obviously cannot accept the unstable output quality of general Agents.
An Agent developer told LightCone Intelligence that enterprises usually need to deeply integrate Agents with internal knowledge bases and business process systems, ensuring accurate task execution through workflows for some simple tasks.
Caught between large models and vertical Agents, general Agents have had a significant chunk of their market share carved up by both.
No Scenarios, Waiting for Evolution: Agents Are Just Getting Started
With the "inapplicability" issue, user enthusiasm for general Agents has also waned.
This has led to C-end general Agents, represented by Manus, facing a dilemma of slowing or even reversing growth.
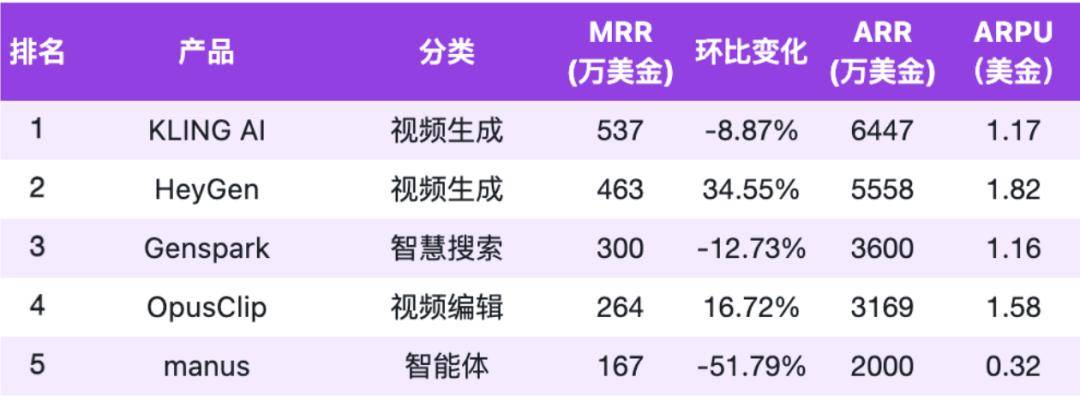
Although from a commercialization perspective, general Agents have indeed demonstrated a sufficiently lucrative side. Represented by Manus, Genspark, and other general Agents, the monetization results in recent months have proven the potential of this sector: Extraordinary production research data shows that, in May, Manus achieved an ARR (annualized revenue) of $9.36 million, while Genspark reached an ARR of $36 million just 45 days after its launch.
However, after a short-term surge in traffic, general Agent products have seen more or less declines in visits and revenue.
In June, Manus had 17.81 million visits, a 25% drop from the peak of 23.76 million visits upon its March launch; Genspark's visits also fluctuated, with 8.42 million visits in June, a decrease of 8%, and Kunlun Wanwei's Tiangong Super Agent saw a decline of 3.7%.
Also in June, Manus and Genspark, two products with outstanding commercial performance, experienced varying degrees of revenue declines. According to Extraordinary Production and Research Data, Manus' MRR (monthly recurring revenue) for that month was $2.54 million, a drop of over 50% from the previous month; Genspark's MRR was $2.95 million, a decrease of 13.58% month-on-month.
The above data indicates that after the initial heat, the user experience of general Agent products has failed to attract users to continue paying. Simultaneously, the frequency of user engagement has also weakened.
The root cause is that Manus and others haven't found sufficient Killer scenarios that can sustain user payments.
Currently, most general Agents on the market are focusing on a few fixed directions: making PPTs, multimodal capabilities, and writing reports (Deep Research), mostly centering on scenarios strongly related to office work. However, for users, these positions are still insufficient to sustain their payments.
Before finding a definitive application direction, a group of companies in the general Agent sector have already tested their products with the intention of seizing the market first.
With unstable monetization and traffic, large companies have limited energy invested in self-developed Agents, generally adopting a "two-pronged" approach. Besides developing their own Agent products, they are currently promoting their Agent development platforms. For example, Alibaba, ByteDance, and Baidu promote their platforms while offering incentives and organizing Agent development competitions, focusing on building developer ecosystems.
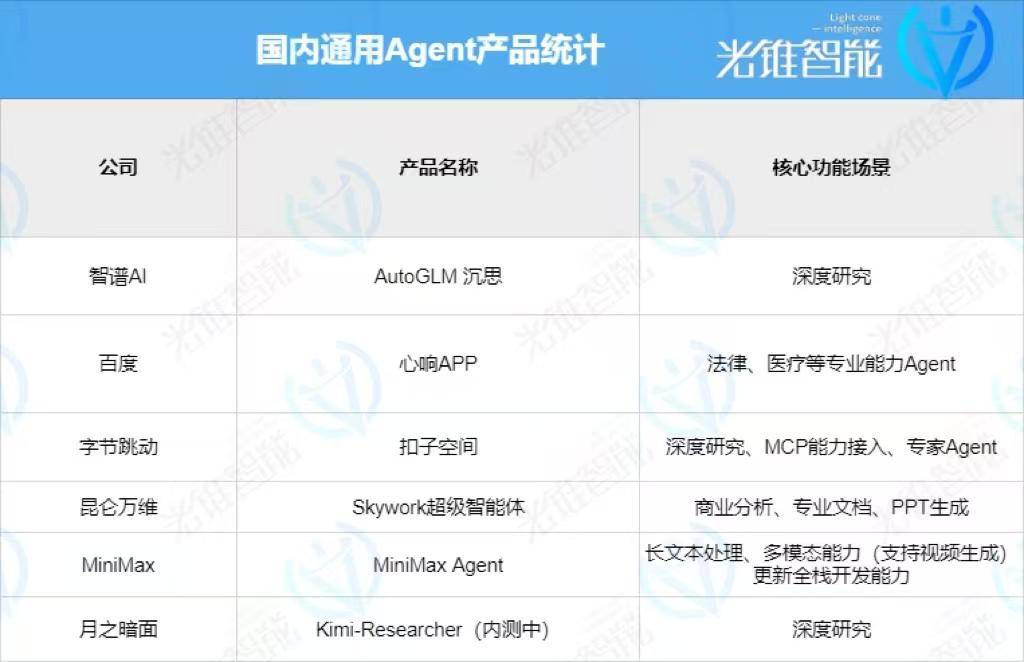
The market seems to have tacitly agreed that general Agents are a business that small companies can't afford to play.
In the domestic market, apart from sporadic startups like Manus and GensPark, most general Agent development companies are those with self-developed large models:
Among them, large companies not only have models but also have their own clouds for support. General Agents are not only products but also a mirror for them to showcase their capabilities as B-end platforms through C-end products, thereby attracting more developers.
Large model startups, adhering to the idea of "Model as Agent," are more focused on researching models for Agent needs such as RL (Reinforcement Learning) and long texts at the model level, leading to general Agent products.
Domestic general Agent players' pricing models are even more competitive than those going overseas. Large companies represented by Baidu and ByteDance have the capability to conduct public tests and provide services for free. Others like MiniMax and Tiangong Intelligent Agent are open through limited use or purchase of points. Compared to large companies' free and unlimited methods, the domestic general Agent sector is destined to become increasingly competitive, with commercial monetization being an unprofitable path.
From a scenario perspective, the deep research function of DeepResearch is the direction chosen by more products. For document-based Agents, invoking tools is relatively less complex, and the cost of text generation is lower, making it a more cost-effective direction.
Based on the development of deep research functions, various Agents have begun to focus on multimodal capabilities and application scenarios. On the one hand, they insert multimodal capabilities such as images and videos into generated documents; on the other hand, they implant scenarios currently suitable for Agents into general Agents, such as making PPTs, which has almost become a standard for office Agents.

However, whether used for reports with added images and texts or for creating PPTs with Agents, these approaches can't solve the general problem of Agents' average output quality. For example, in a deep research report, Agents are most prone to errors in factual information retrieval, such as failing to clarify the concept of Agents and thus recommending large model products.
A further issue is the low value of the output information. A report may only have 3-4 sources, with most content sourced from the internet, often resulting in ambiguous "nonsense." For instance, when asked to introduce the survival challenges of large model companies, it lists all possible problems in starting a company, neither being targeted nor providing valuable incremental information.
As a result, companies are exploring more scenarios that Agents can match, trying to attract more users. Inevitably, Agents may later become "aggregated entry points" for a company's products, with the company integrating its product capabilities into Agents in various ways. For example, MiniMax incorporates the capabilities of Hailuo video, and Baidu Xinxiang integrates its original intelligent agent conversations into scenarios.
Apart from the lack of fitting scenarios, the current limited capabilities and inconsistent effects of Agents also make it difficult for users to pay for them.
General Agents typically execute tasks by breaking them down and following steps. The more complex the task, the more steps the Agent needs to execute. Any error in any step will lead to poor overall output quality. Therefore, for complex tasks, the current stability of Agent execution is insufficient.
For example, to output an analysis of a company, it is necessary to extract financial report information, introduce the company's webpage, and analyze comments from various sources. If any of these steps produce incorrect results, the overall report's analysis quality will be significantly compromised.
Currently, some Agent developers are trying to break through these bottlenecks through technological innovation.
For instance, MiniMax applied its newly released linear attention mechanism from earlier this year to the new model M1, with its intelligent agent product using the M1 model as the base model. This significantly expands the amount of text the agent can handle, supporting 1 million context inputs, making it more effective for scenarios like legal documents that require extensive text analysis.

Dark Side of the Moon emphasizes "Model as Agent," with its base model being a new generation of Agent model trained using end-to-end autonomous reinforcement learning technology. Among them, RL (Reinforcement Learning) becomes a highlight of this deep research Agent.
Many industry insiders have affirmed the importance of RL for Agents in their exchanges with LightCone Intelligence. Compared to traditional supervised learning or pre-trained models that excel in specific tasks but often have limited generalization ability due to the distribution of training data, when Agents need to handle diverse task scenarios and dynamically changing environments, pre-set rules or Agents relying solely on one-time reasoning are difficult to adapt.
For instance, when tackling tasks that demand multiple processes, traditional models may encounter speculation issues at any stage, thereby impacting the final outcome. However, reinforcement learning (RL) enhances generalization capability through extensive trial and error, along with reward mechanisms, performing notably better in complex, multi-step tasks.
It can be argued that RL significantly raises the ceiling for an agent's capabilities.
Kimi-Researcher Feng Yichen revealed that on the Humanity's Last Exam (HLE) leaderboard, which measures AI performance on challenging interdisciplinary problems, the agent model's score surged from an initial 8.6% to 26.9%. This compares favorably with the OpenAI Deep Research team's achievement of improving from around 20 points to 26.6 points in related work, further underscoring the immense value of reinforcement learning in agent training.
With the technological frontier still wide open, newcomers are pushing the boundaries of agent capabilities. Today (July 18), OpenAI unveiled its general agent product, ChatGPT Agent, which achieved remarkable results, scoring a new state-of-the-art (SOTA) of 41.6% on the HLE test.
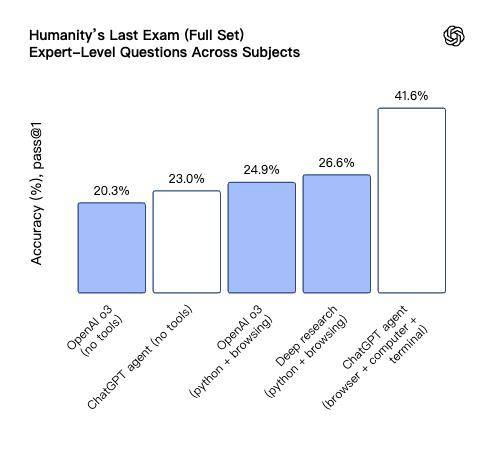
Through reinforcement learning, agents are poised to evolve from simple "tool invokers" into intelligent entities that genuinely possess "autonomous learning" and "environmental adaptation" capabilities. At that juncture, general agents may finally uncover killer applications that convince users to willingly pay for their services.
Agents still have a lengthy journey ahead. Only through technological breakthroughs and in-depth exploration of various scenarios can they truly become invaluable AI assistants.
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




