From 'Imitation' to 'Thinking': The Transformative Impact of the VLA Driver Large Model
 07/31 2025
07/31 2025
 596
596
Produced by Zhinengzhixin
Li Auto is set to significantly implement the Vision-Language-Action (VLA) Driving Large Model in August 2025, marking a leap in assisted driving technology.
Distinct from the first-generation structured algorithms and second-generation end-to-end systems, the VLA model adopts a novel multi-modal architecture that integrates vision, language, and action. This enables the vehicle to simultaneously comprehend spatial geography, linguistic intent, and behavioral rationality, thereby enhancing the overall travel experience.
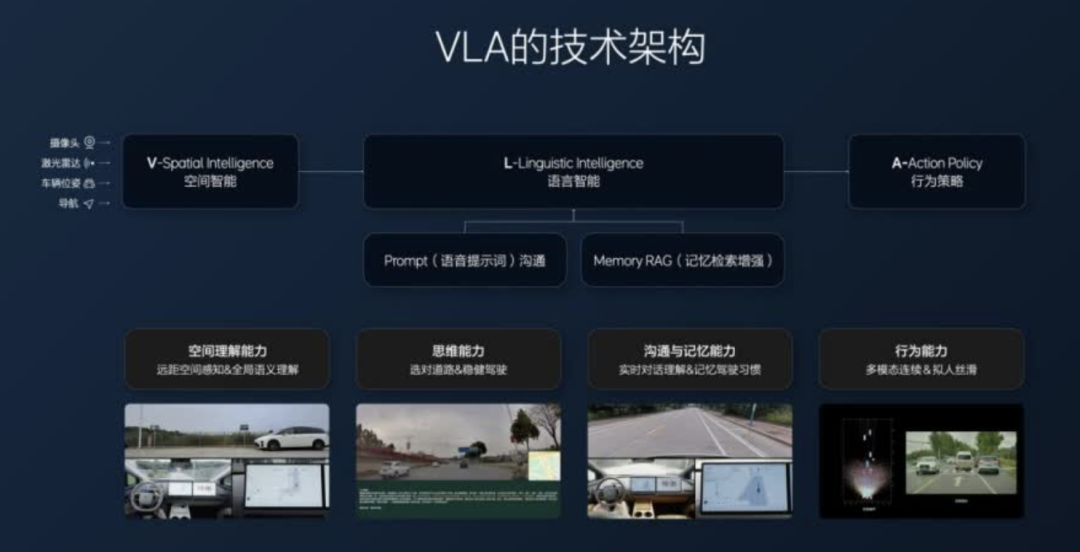
Part 1: The VLA Model Structure
At its core, the VLA architecture introduces a Language thinking module atop the traditional end-to-end Vision-Action (VA) model. This results in a brain-like model capable of 'understanding' scenes, 'reasoning' paths, and 'remembering' behaviors.
The initial design aimed to surpass the limitations of imitation learning within the end-to-end architecture. As data volume grows, the Miles per Intervention (MPI) improvement gradually tapers off. However, the VLA model bolsters generalization and adaptability to uncharted scenarios through the addition of a thinking chain.
The VLA Driver Large Model renders assisted driving smarter, safer, and more akin to human driving. It can 'think' and 'understand' your needs on the road, offering a more intuitive and reliable experience.
◎ It anticipates risks and judges situations like a seasoned driver. Unlike past systems that often brake abruptly at T-junctions, the VLA model assesses blind spots and potential hazards, slowing down in advance for a safer, more reassuring drive.
◎ Acceleration and deceleration are smoother, and turning and overtaking are effortless. The model perceptively manages the surrounding environment, controlling acceleration, braking, and steering like a proficient driver. This ensures a stable and comfortable ride without the discomfort of abrupt maneuvers.
◎ Continuous communication facilitates task completion. Simply instruct: 'Go to refuel first, then pick up the kids.' The VLA Driver Large Model comprehends the relationship between multiple commands, autonomously plans routes, and sequentially executes multiple tasks, mimicking a truly understanding and logical human driver.

VLA employs a tailored 0.4×8 Mixture of Experts (MoE) structure for in-vehicle platforms, balancing multi-scene adaptability and inference speed within limited computational resources. The model not only decides paths but also accepts continuous linguistic instructions to complete serial tasks, fostering a continuous 'driver-vehicle conversation' experience.
Through extensive transfer learning of general knowledge, spatial structures, and human driving styles, VLA progressively develops a 'humanized' driving strategy.
For model training, Li Auto has established a 13 EFLOPS cloud computing platform, with 3 EFLOPS dedicated to inference and 10 EFLOPS for training. This foundation supports a multi-modal large model comprising 32 billion parameters.
The model is compressed into a 3.2 billion-parameter MoE architecture via reinforcement learning and model distillation, successfully deployed on the Thor chip in vehicles. Leveraging INT8 and FP8 mixed-precision inference, the chip boasts an effective computing power of 1000 TOPS, enabling full visual-language interactive response at a frame rate of 10Hz.
To enhance inference efficiency, Li Auto incorporates multiple model compression strategies, such as Diffusion flow matching for inference step compression and dynamic activation mechanisms for MoE routers. For instance, while traditional Diffusion models require 10 steps to generate a path, the Flow Matching method reduces this to 2 steps, significantly decreasing response latency at a 10Hz frame rate.
From architectural design, data structure, to engineering implementation, VLA constructs a driving entity with thinking and execution capabilities, pioneering engineering implementation as autonomous driving models evolve towards the GPT era.
Part 2: From Chip Optimization to World Simulation
Implementing VLA necessitates pushing existing computing platforms to their limits through engineering optimization.
With a theoretical computing power of 700 TOPS, the Thor chip achieves a reasoning efficiency of 1000 TOPS through INT8 and FP8 mixed-precision optimization, PTX underlying rewrite, CUDA modifications, and other techniques. This supports the VLA model's operation at a high frame rate of 10Hz.
Even on the less powerful Orin-X chip, INT4 mixed precision and streamlined MoE deployment are employed to achieve a reasoning experience comparable to the Thor platform, maintaining synchronized capabilities.
Data and training capabilities form another cornerstone. The data closed loop has amassed over 1.2 billion valid driving data segments, using 'experienced driver style' as the annotation criterion to clean the training data, ensuring high safety, comfort, and regulatory compliance.
The current model is based on 10 million Clips for foundational training, achieving stable convergence from FP32 to FP8/INT4 models through QAT quantization training and proprietary toolchains. Coupled with the RLHF reinforcement learning mechanism, it ensures each model version continually approaches the goal of '10 times the safety of human driving.'
The true leap in the VLA model hinges not on training data alone but on the implementation of the world model and simulation environment.
Amidst the high costs and slow feedback cycles of the physical world, Li Auto's proprietary world model constructs a comprehensive embodied intelligent training space. By creating a 3D physical environment with Agent intelligence, it simulates details such as traffic light visibility, vehicle behavior feedback, and collision response. This enables the replacement of real-vehicle training with simulations in over 90% of scenarios.
The system supports over 300,000 kilometers of test mileage daily, amassing over 40 million kilometers of simulation data. Each simulation sample undergoes evaluation, scoring, feedback, and reinforcement through training by the large model, forming a comprehensive closed loop.
In the OTA 7.5 'Super Alignment' update, the VLA model surpasses previous-generation end-to-end models in scores through coverage and evaluation of over 400,000 simulation scenarios.
Li Auto's world model simulation capabilities represent the paramount technical barrier for the VLA model. They accelerate the model optimization process and establish an industry-leading evaluation system and behavior reward mechanism. This provides genuine feedback for reinforcement learning and ensures the orderly evolution of safety, comfort, and compliance during the model's continuous embodied intelligence enhancement.
Summary
VLA could represent a path for assisted driving, evolving from the separation of perception, decision-making, and execution towards the integration of human-like reasoning, interaction, and autonomous behavior. The true value of VLA lies not merely in being a 'driver model' that drives more smoothly, requires fewer takeovers, and communicates more naturally, but in its transformative potential to redefine the future of autonomous driving.
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




