Domestic AI Video Battle: Keling AI, JiMeng AI, and Vidu - Who Will Reign Supreme?
 08/10 2025
08/10 2025
 569
569

Key Points:
1. This article delves into JiMeng AI, Keling AI, and Vidu, the top three domestic players in AI video generation, evaluating their product performance, technical approach, and commercial prospects to predict the ultimate winner.
2. Keling AI excels in expressiveness but tends to overdo it; Vidu is renowned for its realism and delicacy but lacks pace and explosive power; JiMeng AI strikes a balance but may appear slightly unremarkable.
3. The cornerstone of AI video generation is DiT (Diffusion Transformer). Keling AI aligns with Sora's DiT architecture, while Vidu's U-ViT takes a different fusion path. JiMeng AI leverages ByteDance's Seedance 1.0 series model.
4. While technology sets the baseline, market dynamics, ecosystem, and promotional strategy determine the ceiling. Keling AI and JiMeng AI are the frontrunners, as AI video's future hinges on applications and ecosystems.
5. We favor JiMeng AI, backed by Jianying, as its success is anchored in popularizing "empowerment tools" rather than relying on hit content. Tool penetration often outlasts content popularity.
Author: Lin Yi
Editor: Key Points Master
The domestic AI video landscape is evolving rapidly. During the 2025 World Artificial Intelligence Conference (WAIC), Keling AI, a subsidiary of Kuaishou, revealed impressive user statistics: over 45 million global creators, generating over 200 million videos and 400 million images.
Vidu, part of Shengshu Technology, also unveiled its latest "Vidu Q1 Reference Creator" feature at WAIC. Luo Yihang, Shengshu's CEO, explained that users can now generate multiple video elements by uploading reference images of characters, props, and scenes, streamlining the process from storyboard creation to final video.

Luo Yihang, CEO of Shengshu Technology
Domestic AI video advancements continue unabated. Recently, the "San Wu" series titled "New World Loading" debuted, featuring no actors, cameras, or lighting. "Keling AI" was prominently featured on the promotional poster.

This nine-episode series spans anime, 3D animation, and live-action, covering themes like science fiction, fantasy, absurd comedy, and history, all generated by AI. Here's a glimpse of its capabilities:

While this Chinese version of "Love, Death & Robots" hasn't hit mainstream success and has faced criticism for its fragmented narrative, "New World Loading" underscores generative AI's potential in film and television.
Amid "New World Loading's" debut, a global race ensued: OpenAI's Sora, though untested publicly, continues to amaze with each demo; Luma AI's Dream Machine swiftly captivated creators; and giants like Google and Meta unveiled their ace products.
Chinese players are not spectators. Keling AI and Vidu made a strong showing at WAIC, alongside ByteDance's JiMeng AI, which has been persistently innovating. They're not just catching up technologically but also demonstrating resilience and creativity in product execution.
The question now isn't "can AI make videos?" but "who can do it better, faster, and with a broader vision?"
This article spotlights JiMeng AI, Keling AI, and Vidu, analyzing them from three dimensions—product testing, technical route, and commercial prospects—to answer the ultimate question:
In this "Three Kingdoms" battle, who will emerge victorious?
Competitive Stage: A Clash of "Acting Skills" Among Domestic AI Videos
Adhering to the principle of "results matter most," we tested JiMeng AI, Keling AI, and Vidu. The test involved generating a performance video from an AI-generated image, using prompts to evoke acting skills.

The reference image already has cinematic quality, especially the female character's eyes reflecting life's hardships. We used the prompt:
"Fixed shot, an Asian woman turns her head, looks at the camera gloomily, then suddenly bursts into laughter."
For the second video, we used the last frame of the first video as a reference and input:
"Fixed shot, an Asian woman laughs, then her laughter turns into uncontrollable crying, with a natural and unexaggerated expression, showing emotional progression."
We combined the videos, focusing on character, background, and detail consistency. Another key criterion was whether the AI characters' acting matched real actors'.
(Note: For fairness, results used the first-generation outputs of JiMeng Video 3.0, Keling 2.1, and Vidu 2.0, all latest free versions.)
JiMeng AI's Test Results:

JiMeng AI's performance was "rule-abiding." It executed the "laugh" command accurately and attempted to superimpose "cry" through furrowed brows, resulting in a blend of expressions rather than a smooth transition.
Keling AI's Test Results:

Keling AI's style was bold, with exaggerated "laugh" and "cry" emotions, full of dramatic tension. While emotionally rich, it deviated from the prompt's "natural and unexaggerated" requirement. Additionally, its free version's long wait time (over 3 hours on average) is user-unfriendly.
Vidu's Test Results:

Vidu's performance was "reserved," with subtle facial expression changes closer to real reactions. However, it was too slow, with long emotional buildup in each 5-second segment, leaving the core "crying" part underdeveloped.
All three AI contestants overcame consistency issues, focusing on performance integrity and aesthetics. If they were actors:
Keling AI: Strong expressiveness but tends to overdo it. Excellent at evoking emotions, ideal for short, fast-paced, dramatic content. However, it over-dramatizes natural emotions, lacking film-level nuance.
Vidu AI: Realistic and delicate but slow-paced and lacks explosive power. Best at simulating the real world and micro-expressions, generating "cinematic" videos. However, its slow pace can be fatal in short video scenarios.
JiMeng AI: Balanced and controllable but appears slightly unremarkable. Accurately follows instructions but lacks artistic surprises. Excels in functionality (digital humans, motion imitation), positioning itself as a tool. In terms of pure generation quality and artistic appeal, it falls between Keling AI and Vidu, yet to form a distinctive "character".
We also summarized other features of JiMeng AI, Keling AI, and Vidu:

Why do they express content differently? Let's delve into their technology.
Three Divergent Paths Under the DiT Framework
OpenAI's Sora, released during the 2024 Spring Festival, ignited global AI video generation. Its key technology, DiT (Diffusion Transformer), gained popularity.
DiT combines the Diffusion Model with the Transformer architecture for high-quality video generation.
The Diffusion Model's core idea is "add noise, then denoise." It applies Gaussian noise to a clear video until it becomes noise, then learns to reverse this process, "denoising" to restore a structured video.
The "denoising" network often uses U-Net, a convolutional neural network with a "U"-shaped structure capturing both local details and global contours, ideal for image processing.
The Transformer, used in natural language processing (NLP), has a self-attention mechanism efficiently processing long-distance dependencies. It treats input data as "tokens," understanding sequence semantics through token relationship weights.
Combining the two, DiT compresses videos into spatiotemporal "patches," sent to the Transformer like sentence words, enabling better understanding of video content's global correlation, generating longer, coherent videos.
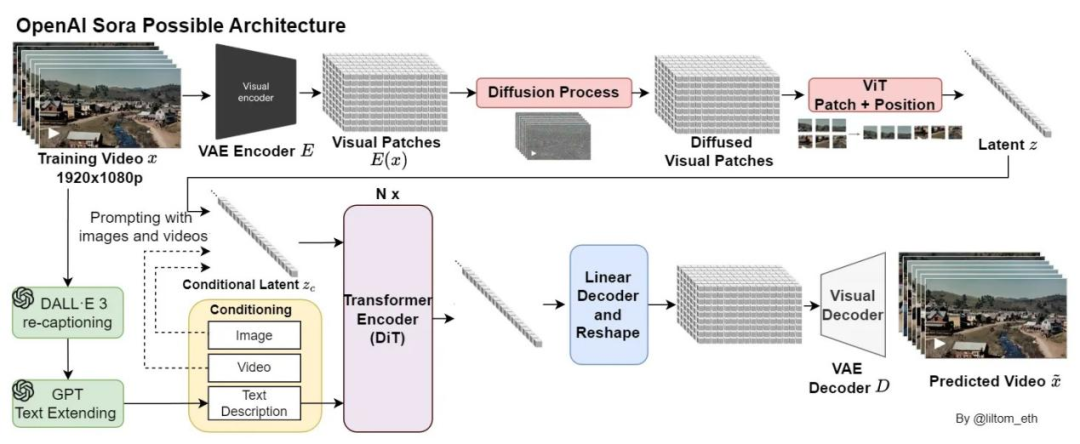
Keling AI chose a DiT architecture consistent with Sora, recognizing Transformer's potential in handling video spatiotemporal dependencies. Beyond replication, Kuaishou innovated with two key technologies: 3D VAE and the 3D spatiotemporal joint attention mechanism.
VAE is a variational autoencoder compressing high-dimensional data (like video frames) into a low-dimensional "latent space," preserving core features. Traditional VAE processes 2D images; Keling AI's 3D VAE is tailored for video data.
It compresses videos into latent vectors with spatiotemporal information, enabling more efficient learning of video dynamics.
The 3D spatiotemporal joint attention mechanism is another key technology. In standard DiT, attention is calculated between spatial patches and time steps. Keling AI's 3D attention operates on a 3D spatiotemporal data block.
It allows the model to "see" other frame parts (spatial attention) while "reviewing" past scenes and "predicting" future trends (temporal attention). This enhances the model's ability to model long-term dynamics, ensuring video consistency and avoiding issues like "flickering" and "deformation".
The Kelin architecture stands out with its exceptional integration of spatial and temporal information processing. It not only emphasizes the significance of "this frame" but also values "this second" and even "these few seconds," resulting in unparalleled performance in motion coherence and long-term consistency. This capability explains why Kelin excels in handling extended narratives like "New World Loading," creating explosive expressions due to its profound understanding of dynamic changes.
However, its drawbacks are equally evident. The global modeling and computation of spatio-temporal information incur substantial costs, potentially contributing to its slower generation speed. Additionally, its emphasis on dynamics might lead to exaggerated actions when processing static or subtle expressions.
On the contrary, Vidu's U-ViT takes a distinctive integration approach.
Rather than merely replacing modules in U-Net with Transformer, U-ViT ingeniously integrates the attention mechanism of Transformer into the U-Net framework. Specifically, U-ViT retains U-Net's classic hierarchical structure of downsampling (encoding) and upsampling (decoding) while incorporating Transformer modules at various feature processing levels.
U-ViT's advantage lies in leveraging U-Net's prowess in capturing low-level visual features (like texture and edges) and Transformer's strength in understanding global semantics and long-range dependencies (such as object motion trajectories and scene logic). This design has demonstrated remarkable performance in model scaling.
Upon launch, Vidu utilized the U-ViT architecture to generate HD videos with 1080P resolution. Its core product philosophy revolves around "one-stop solution" and "simulating reality."
"One-stop solution" entails end-to-end, one-time generation of technology without keyframe interpolation. This ensures that each video frame is generated after the model's comprehensive consideration of global spatio-temporal information, guaranteeing smooth motion, logical coherence, and enabling complex "one-shot" dynamic shot effects like focusing and scene transitions. "Simulating reality" refers to Vidu's dedication to mimicking real physical laws and generating scenes consistent with light and shadow logic, gravity effects, and fluid dynamics.
The essence of this approach is "each doing its own job." U-Net handles low-level image details (like texture and light/shadow), while Transformer manages global logical relationships. This gives Vidu a unique edge in simulating real physical laws (light/shadow, gravity) and depicting fine textures, making its videos exceptionally high in "picture quality" and "realism."
However, its meticulous focus on local details may make it relatively conservative in interpreting and executing large, rapid dynamic changes. This explains Vidu's reserved and slow-paced performance, as it prefers adhering to physical reality.
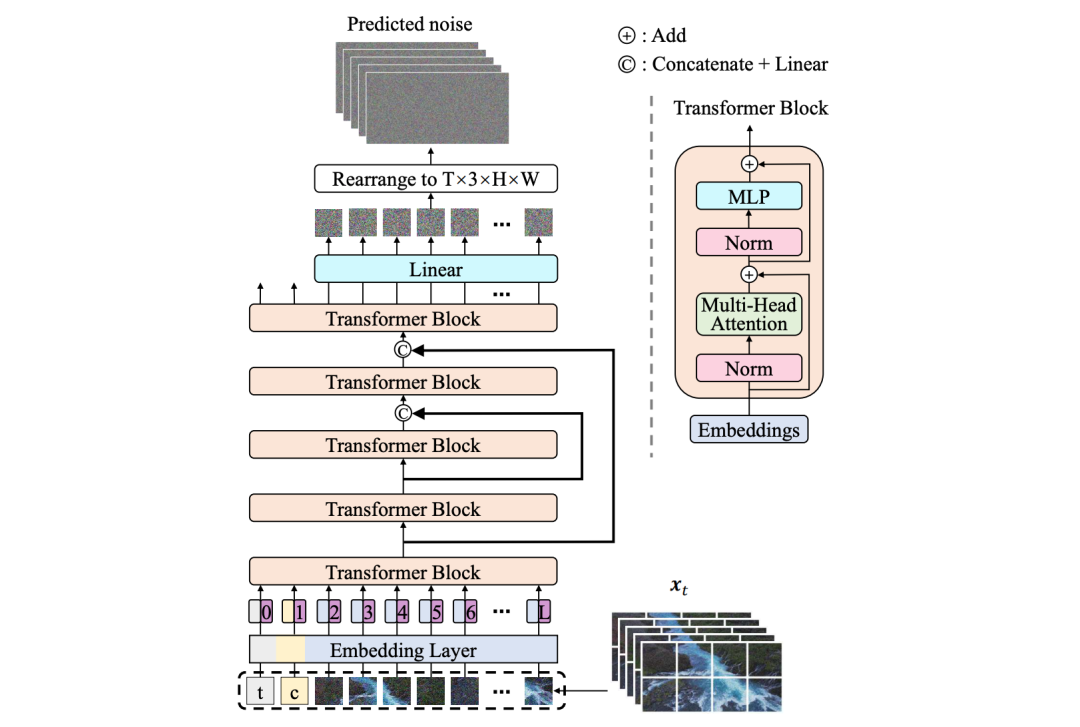
Jimeng AI, on the other hand, still bears the influence of its DiT technology. For video generation, it primarily relies on its self-developed Seedance 1.0 series of models.
According to a previously published technical report on the Seedance 1.0 video generation model, Seedance 1.0 supports text and image inputs, generating 1080p high-quality videos with seamless multi-camera switching, high subject motion stability, and natural picture quality.
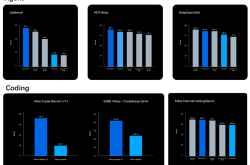
On the third-party evaluation list Artificial Analysis, Seedance 1.0 ranks first in both text-to-video and image-to-video tasks.
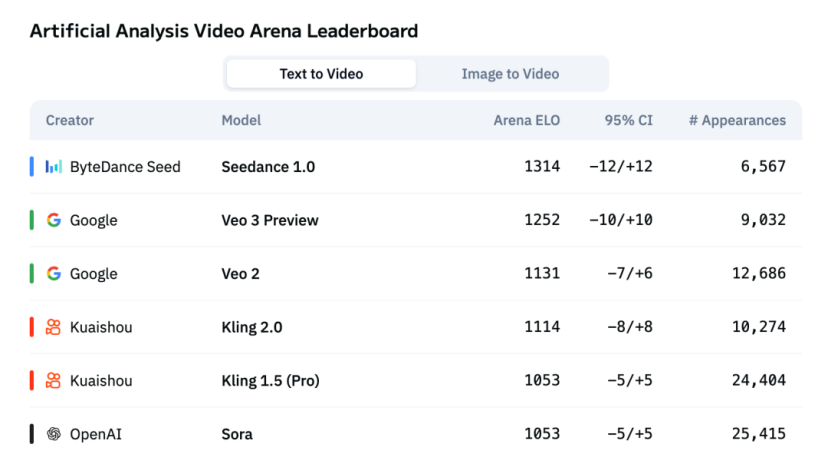
Artificial Analysis Text-to-Video Ranking
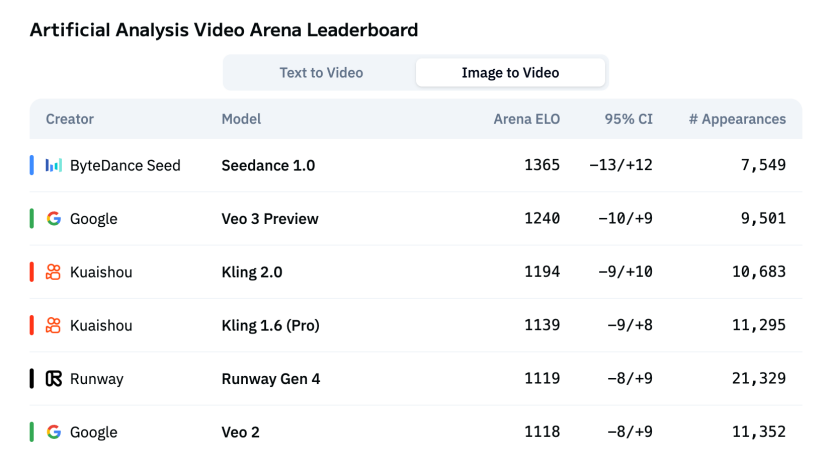
Artificial Analysis Image-to-Video Ranking
The technical report reveals that Seedance 1.0 introduces a precise description model to enhance data diversity and usability, achieving multi-camera switching and multi-modal input through a unified pre-training framework. A composite reward system during the post-training phase enhances picture vividness, stability, and aesthetic appeal, significantly improving inference speed, with the fastest generation of a 5-second 1080p video in about 40 seconds. Jimeng employs a hierarchical model strategy:
- The Jimeng 3.0 version utilizes the Seedance 1.0 mini model.
- The Jimeng 3.0 pro version adopts the more powerful Seedance 1.0 model. This model hierarchy strategy embodies a pragmatic approach, providing models with different performance levels to reduce the computational threshold for ordinary users while ensuring basic generation quality, thereby allowing more computational resources to be invested in enriching product functions (like digital humans and motion control) and enhancing the overall user experience (like faster generation speed).
Of course, this strategy may also involve trade-offs in the ultimate pursuit of core generation quality. Compared to industry-leading models focusing on extreme dynamic expressiveness and detailed realism, Jimeng's choice emphasizes technology popularization and product function comprehensiveness. This explains why its generated videos may lag behind top-level models in emotional transitions or detailed expressiveness in some tests, a result of balancing the technical path and product positioning.
Overall, the technical route directly shapes a product's character. Kelin's "Sora route" makes it an expressive faction, Vidu's "fusion route" a realistic faction, and Jimeng's "pragmatic route" a tool faction.
Beyond technology: Whose ecological niche is superior?
While technology sets a product's lower limit, the market, ecosystem, and promotion strategy determine its upper limit.
Kelin's significant advantage lies in its backing by Kuaishou, a vast short video traffic pool. It doesn't need to acquire users from scratch but can be directly integrated into the creation and consumption cycles of hundreds of millions of people. Kuaishou's extensive video data also provides invaluable "nourishment" for model iteration. "New World Loading" exemplifies "content as marketing."
However, the core challenge is transforming powerful technological capabilities into user-friendly product features and finding a clear commercialization path. If it remains a standalone tool for "showing off skills," it will struggle to take root within the Kuaishou ecosystem.
Vidu's "Tsinghua background" offers strong technical endorsement and talent reserves, enabling it to lead in underlying technological innovation. Vidu's positioning aligns closely with that of an underlying basic large model, offering immense potential in the To B market (empowering industries like film, television, and design).
However, its biggest challenge is productization and marketization. Academic teams often prioritize technical perfection but may lack in user experience, market promotion, and business operations. Vidu must swiftly identify its commercial landing scenario to avoid the "acclaim without sales" dilemma.
ByteDance, with Douyin and Jianying, provides Jimeng with a more comprehensive "creation-distribution" closed loop than Kuaishou. Jimeng's functional design (like digital humans and camera movement selection) reveals its ambition: it aims to be more than a "generator" but the core of the next-generation video creation workflow, deeply integrated into tools like Jianying.
However, internal competition within ByteDance is fierce, and Jimeng must prove its value relative to other AI projects. Additionally, finding the most suitable entry point within the vast product matrix and educating users to accept new creation methods poses a challenge.
Who will emerge as the biggest winner?
After thorough comparison, we can confidently conclude:
Vidu has the highest potential but faces the steepest path. Its technical route positions it to generate cinematic, indistinguishable video content, becoming a "productivity tool" in the professional field. However, whether it can successfully navigate the "valley of death" from technology to products remains uncertain.
The ultimate biggest winner is likely to be either Kelin or Jimeng.
The reason is straightforward: The ultimate battleground for AI video lies in applications and ecosystems.
Kelin has demonstrated its ambition and strength on the content side with "New World Loading." If Kuaishou decisively integrates Kelin's capabilities into its short video ecosystem and lowers the creation threshold, it stands a chance of igniting a wave of AIGC among the general public.
Jimeng, on the other hand, resembles a stealthy assassin aiming to redefine the "creator." When AI video generation capabilities are integrated into Jianying like today's "one-click cut to the same style," it will directly empower millions of content creators, with immense explosive potential.
If we must choose between the two, we lean towards Jimeng AI, owner of Jianying. This is because Kelin's success hinges more on "hit content," while Jimeng's success is built on the popularization of "empowering tools." Tool penetration is usually more enduring and sticky than content explosions.
Of course, this is a logical deduction based on the current situation, and the progress of every domestic AI video player deserves recognition. This race has just begun. The only certainty is that, regardless of who wins, we will witness the unprecedented loading of a "new world."
-
![]()
Even Li Auto Is Facing Challenges. Can Xiaomi Make a Mark in the Extended-Range Hybrid Vehicle Market?
-
![]()
Surplus Capacity Leasing vs. Aggressive Expansion: Is Meta's 'Dual Strategy' a Deliberate Move?
-
![]()
German Business Leaders Contemplate 'Embracing the 996 Culture,' While Chinese Auto Workers Simply Aspire to Clock Out On Time
-
Graduating with a Violin Serenade in a Luobo Kuaipao, Enjoying Yunba Rides, and Watching Football with Milu: Shenzhen's Seamless Integration of Driverless Cars into Daily Life
-
![]()
Shenzhen Unveils 331 Nighttime Autonomous Vehicle Routes in Three Months: Even Logistics Embrace Off-Peak Operations in the Vibrant City
-
![]()
Why Did the Lingguang App Lose Its Competitive Edge? A Strong Hand Played Poorly
-
![]()
Monthly Double Building Purchases for 3.8 Billion: Is Duan Yongping Still in Sync with Pinduoduo?
-
![]()
Tesla FSD’s China Debut: How Orbbec’s ‘AI Eyes’ Are Revolutionizing Intelligent Driving and Robotics