Will Large Transformer Models Revolutionize or Complement Deep Learning in Autonomous Driving?
 08/14 2025
08/14 2025
 673
673
In recent years, the remarkable performance of large language models such as ChatGPT, Claude, and ERNIE Bot in text generation and dialogue interactions has sparked discussions about whether the Transformer architecture is poised to replace traditional deep learning. Particularly in autonomous driving, some manufacturers have begun exploring the integration of multimodal large models (MLLMs) into perception, planning, and decision-making systems, igniting debates about the obsolescence of traditional deep learning. However, from the perspectives of technical principles, computational costs, safety requirements, and implementation pathways, Transformers and deep learning are not mutually exclusive but rather complementary, each playing distinct yet crucial roles in the system.

In the architecture of autonomous driving systems, perception, prediction, decision-making, and control form the core processes. Perception relies on sensors to gather external information about vehicles, pedestrians, lanes, traffic lights, etc. This information is then fed into modules for path prediction, behavior reasoning, and obstacle avoidance planning, ultimately resulting in operational instructions via the control module. Traditional deep learning techniques, notably Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Long Short-Term Memory Networks (LSTMs), have long dominated these tasks. They excel at learning complex patterns from large-scale labeled data, particularly in image recognition and semantic segmentation, which are vital for autonomous driving perception, where vehicles must accurately recognize traffic elements and make prompt decisions.
So, how have Transformers and their evolved versions—large language models (LLMs)—entered the realm of autonomous driving? Initially shining in Natural Language Processing (NLP), these models leverage the 'attention mechanism' to capture global relationships between sequence elements, enabling powerful contextual understanding. When extended to non-linguistic modalities like images, videos, and radar point clouds, multimodal large models evolved. These models are now used to analyze traffic scenarios, predict behavioral intentions, and even formulate high-level driving strategies. For instance, when a system detects a pedestrian approaching a zebra crossing, an LLM can integrate prior context to infer that the pedestrian might cross soon, prompting the system to slow down or detour.
Despite their impressive capabilities, LLMs face significant hurdles in fully replacing traditional deep learning. Firstly, the perception module demands real-time response and is highly sensitive to latency, while current LLMs are often large and have high inference latency, making it challenging to meet in-vehicle computing efficiency requirements. Secondly, LLMs can suffer from 'hallucinations', generating false or invalid content when lacking clear instructions or training boundaries. While this might be a semantic error in text generation, it could lead to severe safety risks in autonomous driving. Thirdly, the Transformer architecture is inherently a 'black box' model with a reasoning process that is difficult to explain, which conflicts with the high interpretability demands of autonomous driving systems for safety audits, responsibility allocation, and regulatory compliance.
Currently, some technical solutions are embracing a 'fused architecture', leveraging Transformers and deep learning in their most suitable modules rather than as mutually exclusive options. For instance, the perception system continues to rely on CNNs for high efficiency and accuracy, while LLMs assist in reasoning tasks like behavior prediction and intention understanding, providing richer semantic support. There are even Transformers with 'world model' capabilities that can self-simulate and optimize through abstract modeling of complex traffic environments. Companies like Pony.ai and Waymo are adopting paths that combine generative AI with reinforcement learning to enhance the robustness of autonomous driving systems in 'long-tail scenarios'.
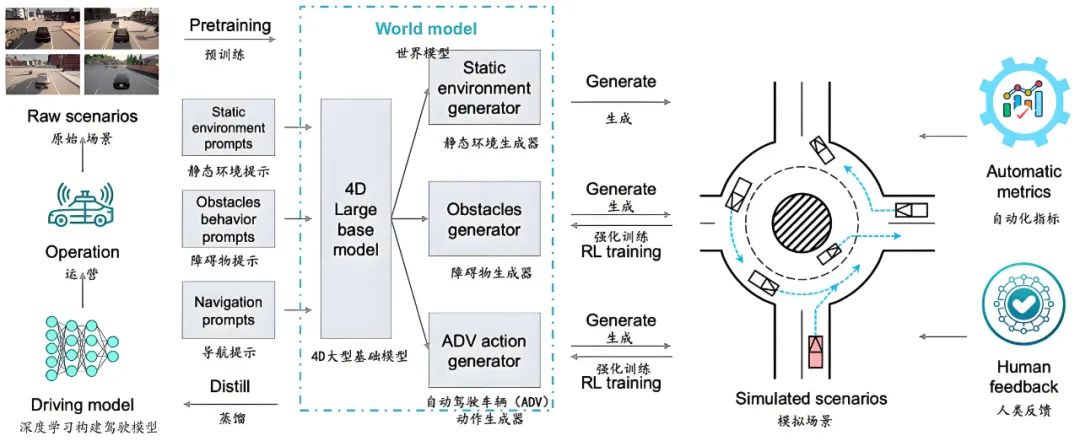
Pony.ai's Solution
'Long-tail scenarios' refer to rare but potentially hazardous traffic situations, such as a fallen iron drum on a highway or an electric vehicle driving against traffic. These scenarios are almost impossible to comprehensively capture in real datasets, making generative AI an effective means of supplementing training data. Transformers can construct a basic world model to simulate these rare events, thereby enhancing the system's generalization ability. This approach, akin to AlphaZero's self-play training logic rather than AlphaGo's imitation learning from human chess games, involves the system continuously optimizing its strategy through world simulation.
The advancement in simulation capabilities does not diminish the importance of real perception. Real-world road conditions are ever-changing, with unpredictable variables like lighting, weather, traffic facilities, and human behavior. Only the stable recognition capabilities of deep learning algorithms for real sensor data can ensure reliable system input. Transformers can build upon this foundation for further 'thinking' but cannot entirely 'take over' the task flow.
Another critical consideration is resource cost. LLMs often require high-performance computing platforms like GPUs, TPUs, or dedicated neural network acceleration chips, incurring substantial deployment costs. Especially in edge computing-based autonomous driving vehicles, in-vehicle chip resources are limited and cannot support the operation of large-scale parameter models. In contrast, traditional deep learning models have been optimized over the years and now offer standardized lightweight versions that run efficiently on embedded platforms. Therefore, most mainstream manufacturers currently use deep learning solutions for perception and control, while employing Transformers in the cloud or training phases for simulation generation, behavior reasoning, and other scenarios.
In the path planning phase, Transformers also encounter practical challenges. Path planning demands high real-time performance and reliability, with each decision needing to be made swiftly and with certainty. While large models show potential in strategy generation and rule formulation, they still cannot match traditional path planning algorithms like A*, RRT, and BEV-based learning in terms of execution efficiency and controllability. Furthermore, the randomness in the output of large models inherently conflicts with the certainty required in path planning tasks. Any uncertainty or deviation in the planned path can severely impact driving safety.
From the perspective of system architecture evolution, the autonomous driving industry is gradually shifting towards a 'multimodal + division of labor' model. Modules such as perception, control, and navigation maintain the use of stable and reliable deep learning systems, while the cognitive and interaction layers can gradually integrate LLMs to enhance the vehicle system's understanding and reasoning abilities. For example, when an autonomous driving vehicle approaches a construction area, traditional models can only recognize obstacles ahead, whereas LLMs can determine through 'semantic understanding' that these obstacles are temporary, thereby optimizing detour paths. In the future, it may also be possible to explore the integration of natural language with vehicle interaction, allowing passengers to issue commands like 'go to the nearest gas station' or 'avoid highways' via voice, which large models can then parse to generate traffic behavior strategies.

However, these explorations are still in the experimental and validation stages. Regulatory agencies are cautious about the 'black box' nature of autonomous driving systems. The instability observed in text generation by Transformer models could have catastrophic consequences if applied to the transportation system. Therefore, current large models are more likely to act as 'enhancement modules' in system design rather than fully replacing the deep learning infrastructure.
From an industry-wide perspective, the crux of whether Transformers replace deep learning lies not in technical route debates but in applicability and safety. Amidst the rapid development of large language models, we must recognize their potential in cognitive understanding, behavior modeling, and complex reasoning while acknowledging the practical challenges of high computational requirements, uncertain outputs, and lack of interpretability. In autonomous driving, a 'physical AI' scenario where any system module error can pose a life safety risk, technology introduction must be approached with caution.
In summary, the relationship between Transformers and deep learning is one of complementarity and fusion rather than substitution. They each excel at distinct tasks at different levels, collaboratively building a more intelligent, safe, and efficient autonomous driving system. As technology evolves and chip platforms are optimized, more lightweight, interpretable, and stable Transformer models may emerge, further expanding their role in autonomous driving systems. However, until then, deep learning will continue to operate stably at the foundation, solidifying the safety underpinnings of intelligent travel.
-- END --
-
![]()
Weekly Stock Review | Who Dominates the Market: Hedge Funds, Quant Traders, Institutions, or Hot Money?
-
![]()
Sales Slump Again: Why Are Affluent Buyers No Longer Exclusively Opting for Porsche?
-
![]()
Xiaomi’s New Auto Brand Launch Sparks Stock Rebound: Is a Trend Reversal on the Horizon?
-
![]()
Seres Mid-Year Report Catastrophe: Projected Losses Surpass 1.5 Billion Yuan!
-
![]()
"Fruit Chain Brother No.1" Plummets Below Issue Price on Debut Trading Day! Chaoshan's Wealthiest Woman Stakes HK$24 Billion on AI
-
![]()
Auto Market Undergoes Major Shake-Up: Winners and Losers Revealed
-
![]()
The Successful Recovery of the First Stage of the Long March 10B: What Does It Mean for China's Commercial Space Industry?
-
![]()
Xiaomi Pengcheng: Crafting the Future of Mobility