Is the Era of ASIC on the Horizon?
 08/19 2025
08/19 2025
 711
711
NVIDIA has fortified its position with its GPU and CUDA ecosystem, enticing numerous companies to invest in high hardware costs and substantial gross margins. During the technology exploration phase, the stability of computing power supply outweighs cost-effectiveness.
However, as AI applications advance into large-scale commercialization, tech giants, once indifferent to GPU prices, are now turning their focus towards more efficient, customized solutions. Similar to how Bitcoin mining evolved from CPUs to GPUs to ASICs, as the algorithm architecture solidifies, the flexibility of general-purpose computing chips becomes a constraint.
Cloud service providers' sensitivity to electricity costs and enterprise customers' demand for high return on investment (ROI) are fostering a consensus: in today's era of surging computing power demand, ASIC chips tailored for specific scenarios may offer the optimal balance between performance and cost.
01. Large Model Algorithms May Reach a Bottleneck
As AI applications transition into large-scale commercialization, cost issues are increasingly prominent: Grok3 training consumes roughly 200,000 H100 GPUs (costing approximately $590 million), and ChatGPT5 training costs reach $500 million, far surpassing the initial GPT3 investment of just $1.4 million. Behind this exponential growth lies the Transformer architecture's limitation: its quadratic complexity Attention mechanism leads to a surge in computing power demand, and the benefits of pre-training are gradually plateauing.
Large models, essentially statistical models based on probability weights, face challenges in balancing "hallucinations" and expressiveness. From an information entropy perspective, early capability improvements rely on technical optimizations, while subsequent improvements are constrained by data abundance – Grok3 and GPT5's capabilities are nearing the limits of data mining in the current environment. Although the performance ceiling under the Transformer architecture is emerging, breaking through the existing technical route remains uncertain: if a new architecture's starting standard must surpass GPT5, the industry entry threshold will significantly rise, potentially slowing technological iteration.
Nonetheless, large models' application value in vertical fields has been proven. In scenarios like music creation and code generation, they significantly enhance efficiency, enabling some practitioners to achieve commercialization. However, the concept of a "unified large model" is dissolving – customized development of industry application tools may become mainstream. Industry leaders prefer embedding AI modules in existing tools, balancing efficiency and system compatibility; for startups, accurately identifying niche demands and implementing solutions is crucial. For instance, in music generation, mastering large model technology alone is insufficient; a profound understanding of music characteristics is also required. For consumer-facing businesses, there are dual challenges of charging models and traffic entry points – giants control entry points through free strategies, monetizing through other businesses, while SMEs' breakthroughs are more likely in the B2B field.
Currently, large models' capability is no longer the core contradiction in industry implementation; rather, transforming technological advantages into real-world application value will shape the future landscape.
02. Is ASIC the Optimal Solution?
If the chip world were a toolbox, ASIC would be the "professional craftsman" tailored for specific tasks. Unlike GPUs, which are "jacks-of-all-trades" (capable of mining and running AI), ASICs (Application-Specific Integrated Circuits) are designed with a singular goal in mind – akin to an electric screwdriver designed solely for screwing, it's hundreds of times more efficient than a regular screwdriver.
Taking Bitcoin mining as an example, early miners used CPUs for calculations, later realizing GPUs' superior parallel computing capabilities. However, it was Bitmain's ASIC miners that truly industrialized mining. This chip dedicates all its circuit resources to executing the SHA256 hash algorithm, turning the entire chip into a "perpetual motion machine of computing power." Its mining efficiency per unit of energy consumption is a thousand times that of a GPU. This extreme optimization means that as Bitcoin network difficulty soars, only ASICs can maintain economic viability.
This characteristic is equally vital in AI. While NVIDIA GPUs can handle various algorithms, when running the Transformer architecture, a significant number of transistors are used for general-purpose computing rather than specific tasks. It's like using a Swiss Army knife to cut vegetables; while functional, it's far less efficient than a professional kitchen knife. ASICs, on the other hand, allocate all circuit resources to core operations like matrix multiplication and activation functions, theoretically achieving over 10 times improvement in energy efficiency ratio.
The difference in operational and maintenance costs is more intuitive. An NVIDIA GPU consumes approximately 700 watts of power, incurring an electricity cost of about 0.56 yuan per hour (at 0.8 yuan per kWh) when running large models. However, an ASIC chip with equivalent computing power can control power consumption within 200 watts, costing only 0.16 yuan per hour for the same task. For cloud service providers deploying tens of thousands of cards, this difference saves tens of millions of kWh of electricity annually – equivalent to a small power plant's annual generation.
However, ASIC's "specialization disease" is evident: once the algorithm is upgraded or the task changes, these customized chips may become "electronic waste." Like a lens designed for film cameras, it's obsolete in the digital era. Thus, they're more suited for scenarios where the algorithm is relatively stable, such as cloud-based inference services and autonomous driving perception systems requiring long-term stable operation.
The current AI industry faces a critical juncture: as large model training costs soar from tens of millions in the GPT3 era to billions in the Grok3 era, even tech giants are reassessing their technological routes. Just as the transition from CPUs to GPUs occurred, now it may be GPUs' turn to give way to more specialized ASICs.
03. Domestic Design Service Providers Stand to Benefit Significantly
Custom accelerated computing chips (ASIC) are emerging as the core driver behind the AI computing power revolution. It's predicted that the global market for custom accelerated computing chips will reach $42.9 billion by 2028, accounting for 25% of the accelerated chip market, with a compound annual growth rate of 45% from 2023 to 2028. This explosive growth stems from AI models' exponentially increasing computing power demand: training clusters have evolved from tens of thousands of cards to hundreds of thousands, while inference clusters, though smaller in single cluster size, will form an even larger market demand with millions of deployments.
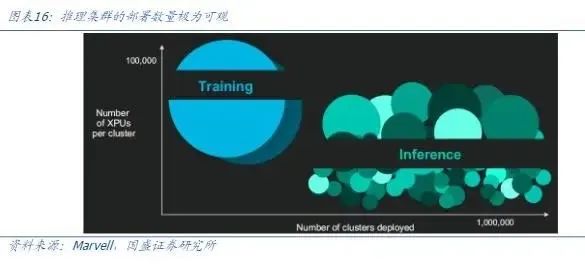
Tech giants are accelerating their layout of self-developed ASICs to seize the initiative. Google has launched the sixth-generation TPU Trillium chip, focusing on optimizing energy efficiency ratios, planning to replace TPU v5 on a large scale by 2025, and breaking the previous cooperation model with Broadcom, adding MediaTek to form a dual supply chain to strengthen the layout of advanced processes. Amazon AWS is using the Trainium v2, jointly designed with Marvell, as its mainstay while simultaneously developing Trainium v3. TrendForce predicts that its ASIC shipment growth rate will rank first among American cloud service providers in 2025. After successfully deploying its first self-developed inference chip, MTIA, Meta is now developing the next-generation MTIA v2 with Broadcom, focusing on energy efficiency and low-latency architecture to accommodate highly customized inference load demands. Although Microsoft still relies on NVIDIA GPUs, its self-developed Maia series chips have entered the iteration stage, with Maia v2 being mass-produced by GUC and the introduction of Marvell to participate in the advanced version design, diversifying technology and supply chain risks.
Chip design manufacturers are also experiencing growth opportunities. Broadcom's AI semiconductor revenue exceeded $4.4 billion in the second quarter of 2025, a year-on-year increase of 46%. Its custom AI accelerator (XPU) business benefits from the deployment plans of three customers with million-level clusters, and it's anticipated that inference demand will accelerate in the second half of 2026. Marvell's leading 3nm XPU program has secured advanced packaging capacity, with production set to commence in 2026, and it's engaged in iterative cooperation with a second hyperscale customer. The domestic market is also accelerating, with Alibaba's T-Head launching the Hanguang 800 inference chip, Baidu building a self-developed 10,000-card cluster (Kunlun 3 P800), and Tencent forming a combined solution through its self-developed Zixiao chip and investment in Suiyuan Technology.
The crux of this transformation lies in the shift from general-purpose to specialized computing power supply. As AI applications enter large-scale implementation, ASICs, with their extreme optimization capabilities for specific algorithms, are redefining the cost structure and technological route of the computing power economy.
- End -
-
![]()
Will Changan Mazda, Mired in Difficulties, Follow Skoda’s Path Out of China?
-
![]()
This Week in Home Appliances: Domestic Cool, Overseas Hot – Haier, Midea, Gree, Hisense Break Through; JD.com, TCL, Samsung, Vanward Drive Transformation
-
Seres Anticipates Over 2.2 Billion Yuan Loss in Q2, with Core Subsidiary AITO Automobile Projected to Lose 1.9-2.15 Billion Yuan
-
![]()
Breaking Through Barriers: Five Models for Chinese Automakers to Access Global Markets
-
![]()
Young Generation Trades Cars as Often as Smartphones! Average Age of New Energy Vehicles: Just 1.8 Years...
-
![]()
Musk Declares SpaceX Will Surpass the Combined Value of Everything on Earth! Is He Just Making Bold Claims? Online Debates Rage On…
-
![]()
The Most Terrifying Truth Behind GPT-5.6: AI Has Started to Self-Evolve
-
![]()
Is AI Still the Main Theme of the Market After the Decline of Memory Stocks?