The Dawn of AI's 'Actuarial Era': NVIDIA Leads the Charge with Nemotron-Nano-9B-v2
 08/19 2025
08/19 2025
 605
605

In the ever-evolving landscape of AI, small models are now stealing the spotlight. From Liquid AI's vision model fitting snugly on smartwatches to those running seamlessly on Google smartphones, miniaturization and efficiency have emerged as key trends. NVIDIA has now joined this fray with its innovative small language model (SLM), Nemotron-Nano-9B-v2. This model not only excels in selected benchmarks among its peers but also allows users to toggle AI 'inference' on and off, heralding new horizons for AI applications.
From Edge Gadgets to Mainstream Workhorses: The Rise of 'Small' Models
Over the past three months, a cadre of 'mini' AI models has emerged, sparking a quiet revolution. Liquid AI's vision model, small enough for smartwatches, has elevated wearable intelligence to new heights. Google, meanwhile, successfully integrated Gemini-Nano into the Pixel 8, marking a significant leap in mobile AI capabilities. Now, NVIDIA's 9 billion parameter Nemotron-Nano-9B-v2, deployed on a single A10 GPU, further redefines the potential of small models.
This isn't just a 'small but mighty' tech demo; it's a meticulous balance of cost, efficiency, and control. As NVIDIA AI's Post-Training Director Oleksii Kuchiaev candidly noted on X, "Reducing from 12 billion to 9 billion parameters was specifically tailored to fit the A10—the most prevalent GPU in enterprise settings."
In essence, parameter size is no longer the sole metric for model quality; Return on Investment (ROI) is now paramount.
Turning Thought Chains into a Billable Asset
The 'black box' nature of traditional large models has long plagued enterprises, with long-duration inference leading to spiraling costs. Nemotron-Nano-9B-v2 offers a straightforward, efficient solution:
By appending '/think' to the prompt, the model activates its internal thought process, deriving results step-by-step akin to human thinking. Adding '/no_think' bypasses intermediate steps, directly outputting the answer. The system-level max_think_tokens function, akin to AWS's CPU credit system, caps thought chain expenses, ensuring precise cost control.
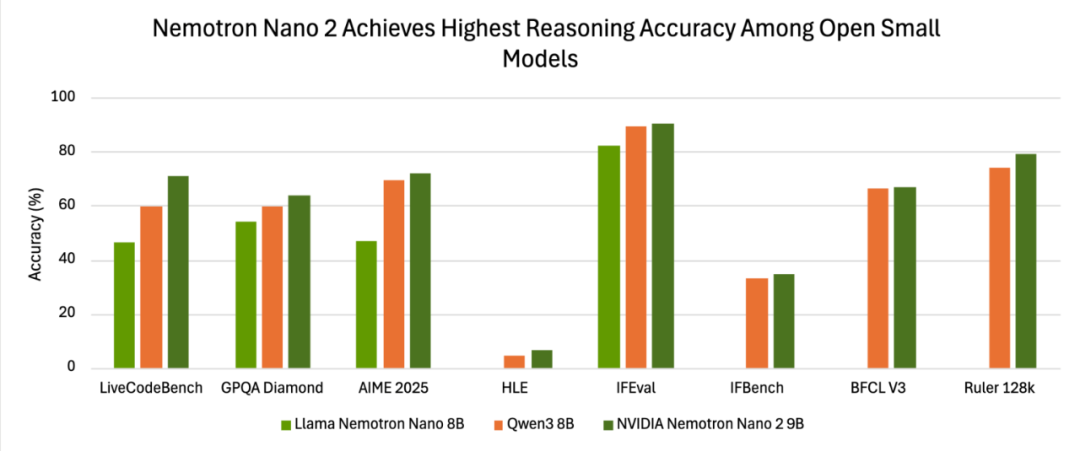
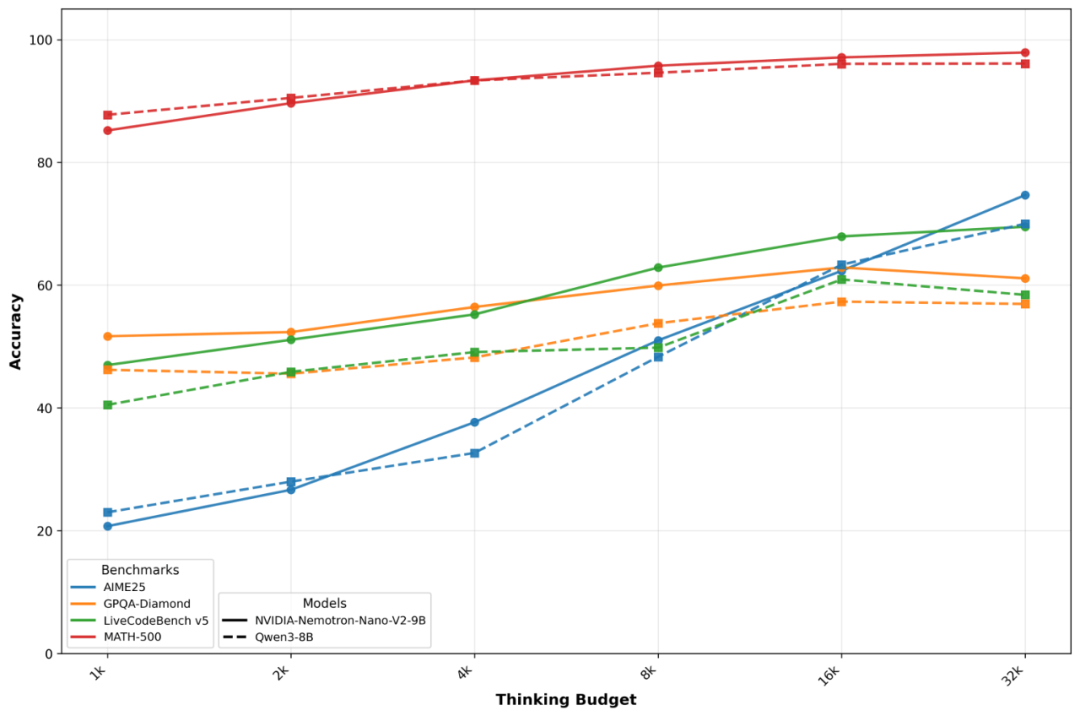
On-site measurement data (official report) speaks volumes:
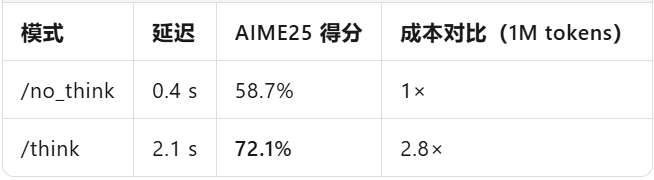
In summary, by making 'inference' an optional feature, enterprises can now pay for the depth of thought, much like purchasing cloud storage.
The 'Fuel-Efficient' Transformer Patch
How does a 9B model compete with a 70B in lengthy contexts? The answer lies in the Mamba-Transformer hybrid architecture:
Replacing 70% of attention layers with Mamba state-space layers reduces VRAM occupancy by 40%.
Sequence length scales linearly with VRAM, avoiding quadratic explosions.
Measured throughput for 128k tokens is 2.3× higher than an equivalent-sized pure Transformer.
In essence, Mamba doesn't replace Transformer; it transforms it into a fuel-efficient hybrid engine.
Commercial Dynamite: Permissive License + Barrier-Free Adoption
NVIDIA's licensing strategy is a 'commercial dynamite,' achieving 'three no's':
No Money: No royalties or revenue sharing; enterprises incur no additional fees.
No Negotiation: Direct download for commercial use, eliminating complex negotiation processes.
No Legal Worries: Simply adheres to Trustworthy AI safeguards and export compliance, minimizing legal risks.
Compared to OpenAI's tiered licensing and Anthropic's usage restrictions, Nemotron-Nano-9B-v2 resembles the 'AWS EC2 of the open-source world'—ready for immediate commercial deployment, significantly lowering the barrier to entry for enterprises.
Scenario Segmentation: Who Stands to Benefit First? 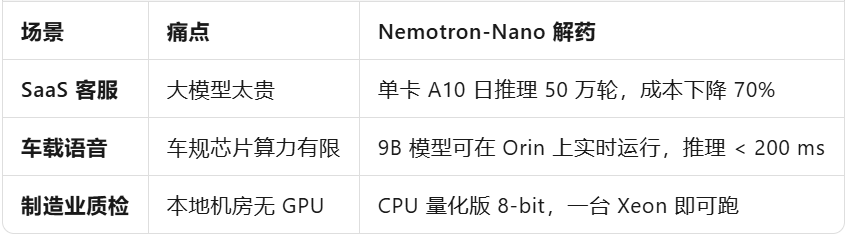
In summary, any edge/privatized scenario now boasts an 'intelligent and affordable' ace up its sleeve.
The AI 'Actuarial Era' Officially Begins
Over the past four years, we've witnessed the magic of scaling laws: Parameters × Compute Power = Performance. However, Nemotron-Nano-9B-v2, with its 9 billion parameters, now tells a different story: Architecture × Control × License = Sustainable AI Economy.
As Liquid AI crams models into watches and NVIDIA turns inference into a switch, 'small' is no longer a technical compromise but a well-calculated optimal solution.
In future funding pitches, entrepreneurs may forgo boasting about surpassing GPT-4 and instead confidently state, 'We achieve 90% of the effect with 1/10th the compute power, and we're still profitable.' This marks the dawn of the AI 'Actuarial Era.'
-
![]()
Will Changan Mazda, Mired in Difficulties, Follow Skoda’s Path Out of China?
-
![]()
This Week in Home Appliances: Domestic Cool, Overseas Hot – Haier, Midea, Gree, Hisense Break Through; JD.com, TCL, Samsung, Vanward Drive Transformation
-
Seres Anticipates Over 2.2 Billion Yuan Loss in Q2, with Core Subsidiary AITO Automobile Projected to Lose 1.9-2.15 Billion Yuan
-
![]()
Breaking Through Barriers: Five Models for Chinese Automakers to Access Global Markets
-
![]()
Young Generation Trades Cars as Often as Smartphones! Average Age of New Energy Vehicles: Just 1.8 Years...
-
![]()
Musk Declares SpaceX Will Surpass the Combined Value of Everything on Earth! Is He Just Making Bold Claims? Online Debates Rage On…
-
![]()
The Most Terrifying Truth Behind GPT-5.6: AI Has Started to Self-Evolve
-
![]()
Is AI Still the Main Theme of the Market After the Decline of Memory Stocks?