Enhancing Pure Vision-Based Autonomous Driving with the VLA Model
 08/28 2025
08/28 2025
 656
656
Recently, during a discussion with a colleague, an intriguing question arose: Is the VLA model particularly suited for pure vision systems, and can it accelerate the maturation of their algorithms? This query merits deep consideration. To address it, let's start with a clear conclusion: The VLA (Vision-Language-Action) model is not a "one-size-fits-all" solution for pure vision systems. Instead, it injects invaluable capabilities and training paradigms into these systems, steering algorithms towards greater maturity. In essence, the VLA model introduces not just a replacement but a new toolbox and training concepts. Properly integrated and validated, it can bolster the robustness and semantic understanding of pure vision systems. However, it also introduces new complexities, data demands, and engineering risks that must be navigated with caution.
What is VLA?
Before diving into today's topic, it's essential to define "VLA." (Related reading: What is VLA often mentioned in autonomous driving?) Over the past two years, the term VLA has gained popularity in academia and industry. Its core concept involves jointly modeling and end-to-end training of vision (camera images), language (natural or symbolic descriptions), and action (control commands and trajectories for robots or vehicles) within a unified large model. A typical approach is to use a large-scale vision-language model (VLM) as the backbone for perception and reasoning, followed by an action decoder that maps semantic representations from vision and language into continuous or discrete action outputs. Initially, VLMs were applied to robot manipulation (e.g., RT-2's work), followed by open-source projects like OpenVLA and large models for general embodied control (such as Helix and NVIDIA solutions). These all integrate "understanding vision," "understanding language," and "being able to act" into a cohesive chain.
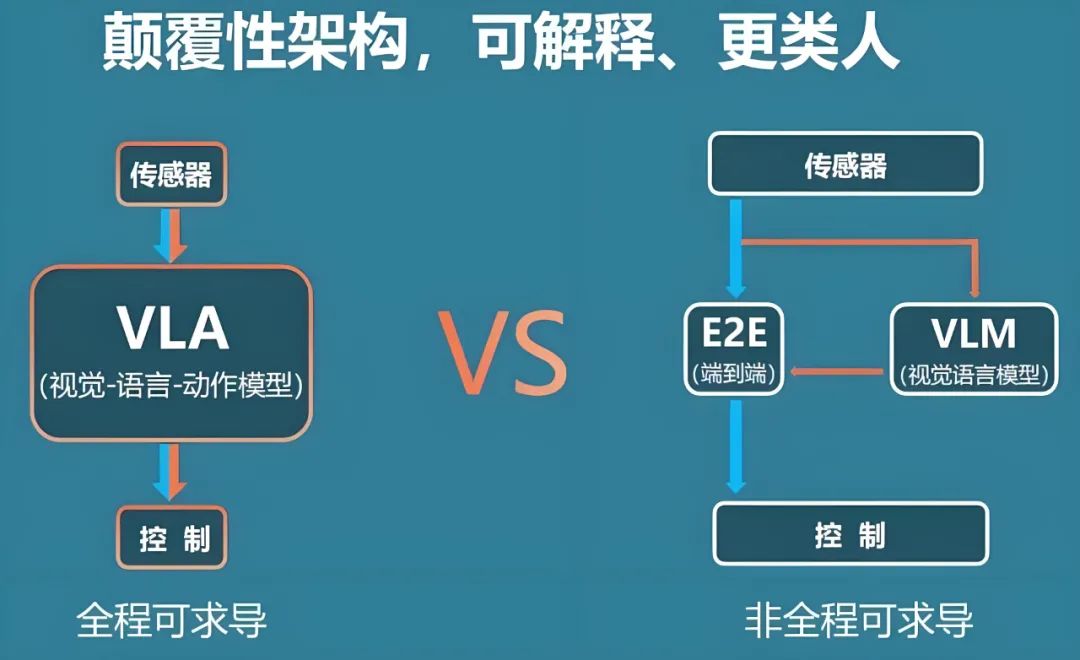
When discussing the VLA model, why is it compared to "pure vision" in the same context? In recent years, vision-language large models (VLMs) have demonstrated robust generalization and reasoning abilities, extracting fine-grained semantic information from images, making inferences with world knowledge, and converting scenes into readable natural language descriptions. These are VLMs' strengths. Connecting these abilities with control strategies aims to achieve a tighter coupling of "perception + reasoning + control." For autonomous vehicles, if the model can not only detect a bicycle ahead but also output executable action trajectories or steering/speed commands based on goals and constraints, it significantly enhances autonomous driving capabilities. The widespread use of large models in autonomous driving is driven by two main factors: the trend towards "fewer modules, more end-to-end" simplifies engineering and retains implicit knowledge within the model, and the pre-training of large models enables cross-scene transferability, potentially reducing the extensive labeling required for each scene. This explains why VLA is used in autonomous driving, especially by teams aiming to rely primarily on cameras (pure vision) for perception and decision-making.
Is VLA Really More Suitable for Pure Vision?
The question of whether VLA is better suited for pure vision systems needs to be addressed at two levels: conceptual and engineering/safety. Conceptually, VLA is inherently multimodal, using language as an intermediate abstraction layer to enable higher-level semantic scene understanding. This complements pure vision systems that rely solely on pixel information. Language serves as a supervisory signal, a task instruction carrier, and can provide high-level descriptions of complex traffic scenarios (e.g., "Someone is chasing a ball and crossing the road ahead, please slow down and yield"), making the mapping from visual perception from "pixels to semantics" more explicit and interpretable. In other words, VLA offers a robust semantic channel and training paradigm for pure vision systems, enhancing their understanding in long-tail scenarios.
However, engineering and safety considerations bring us back to reality. Autonomous driving demands certainty, real-time performance, verifiability, and redundancy under various sensor failures. Currently, autonomous driving systems are divided into perception, localization, planning, and control modules, not just for functional differentiation but also for controllability and verifiability at each level. Integrating all these into an end-to-end VLA model poses challenges, including whether action output accuracy and latency meet real-time closed-loop control requirements, whether failure modes in rare scenarios can be explained and safely mitigated, and whether model outputs satisfy deterministic proof required by regulations/certifications. While these issues are partially accepted in robotics (due to high-frequency closed-loop control and direct action labels for supervision), automotive-grade autonomous driving, especially on highways and in complex urban environments, has low risk tolerance and high regulatory standards. Simply handing control to a large model still faces numerous hurdles.
How Does VLA Promote the Maturity of Pure Vision?
So, how can VLA "help" mature pure vision algorithms? Consider it as several capabilities and tools that can be referenced and integrated. VLA's large-scale multimodal pre-training enhances vision models with stronger semantic representations. With language supervision or alignment, visual features can more easily learn "concept-level" discriminative power, improving robustness and interpretability in small-sample scenarios. For pure vision teams, this injects "world knowledge" and "semantic understanding" into visual features, often lacking in pure pixel supervision. Open-source efforts like OpenVLA have demonstrated improved cross-task generalization by combining instructional data with language descriptions.
Furthermore, VLA provides new supervisory signals and training paradigms. Traditional visual perception training relies on expensive pixel-level or box-level labels, which are difficult to scale to long tails. VLA uses natural language descriptions, instruction sequences, or trajectory data as supervision, supporting behavioral cloning, sequence prediction, and mapping learning from language to actions. This means that in controlled scenarios, pure vision systems can leverage VLA-style distillation or joint training to learn behavioral priors and strategy-level features, possessing a consistent semantic foundation at the decision-making level. The industry has shown the potential of this approach through VLM pre-training and fine-tuning for action tasks.
VLA can also bridge "simulation to reality" and aid data synthesis. Pure vision systems lack samples for long-tail extreme scenarios. VLA's multimodal pre-training and generative capabilities can generate complex interactive samples with language annotations in simulations or convert real-world visual content into structured language descriptions to expand training sets. This semantic-level data synthesis better compensates for models' understanding of complex traffic participants' behaviors than simple pixel enhancement, aiding pure vision perception modules in semantic judgment.

These are aspects of "assistance." Now, let's discuss practical limitations and points of caution. First, there's a shortage and high cost of action supervision data. To teach models to convert visual representations into safe, reliable control commands, vast amounts of high-quality trajectory/control data (closed-loop demonstrations with timestamps, various speed/steering control sequences, etc.) are needed, harder to obtain than labeled images. While some million-level instructional datasets exist in robotics, multi-scene, long-time-series data at the automotive level is scarce, and system dependence on instructional data can become a bottleneck.
Second, there's the issue of closed-loop control frequency and latency. Vehicle control requires millisecond-level or higher response and stability, but large VLMs/VLAs' inference latency and computational cost may not directly meet this. A common industry approach is using VLA for "slow thinking" (high-level decision-making, intention prediction, strategy selection) rather than direct control. This leverages VLA's reasoning while retaining traditional control loops' real-time performance and determinism. For instance, handing over VLA's high-level instructions (slow down, overtake, yield) to traditional planning and control modules for execution is a compromise engineering path.
Third, there's safety verifiability and fallback strategies. Pure vision systems inherently have sensor blind spots and misidentification issues, and placing more "decision-making responsibility" on end-to-end models increases unpredictable failure modes. From a compliance and engineering perspective, a hybrid architecture is feasible, where VLA provides rich semantics and strategic advice while maintaining an independent rule-based safety stack (based on radial redundant sensors, rule-based judgments, and baseline controllers) to enforce final safety constraints. In other words, use VLA to enhance "intelligence" and "understanding" without compromising safety.
How Should VLA Be Applied to Pure Vision?
So, how can VLA be applied to pure vision autonomous driving? Consider VLA as a "semantic enhancer" and "strategy tutor," prioritizing its use to enhance semantic perception and strategic-level learning rather than replacing low-level control. Possible approaches include:
- Using visual features from VLM/VLA pre-training to initialize pure vision perception networks.
- Using language-aligned signals for multi-task supervision (learning detection/segmentation/behavior prediction with descriptive language).
- Using VLA to synthesize complex interactive scenarios with text annotations in simulations to enhance rare long-tail samples.
This maximizes VLA's strengths while keeping risks可控.
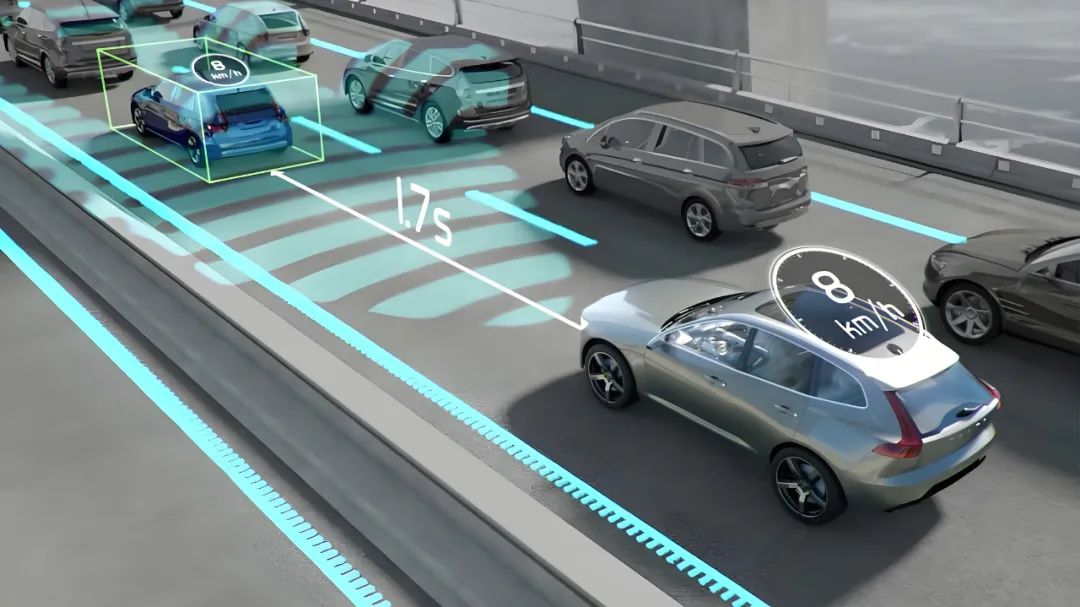
Additionally, data governance must be rigorously graded and verified. When action learning is the main training objective, perform strict quality control and anomaly elimination on instructional data, and build an offline evaluation system capable of causal attribution and counterfactual testing. Vehicle action output cannot be solely evaluated based on training set average error; it must also assess extreme scenario, edge case, and chain reaction safety. This requires the R&D team to invest equally or more resources in building rigorous simulation validation, scenario replay, and closed-loop safety testing when introducing VLA.
Collaborative software and hardware design is also essential. VLA's computational load and inference characteristics determine its deployment, whether fully cloud-based auxiliary reasoning, semi-real-time deployment with edge acceleration, or offline training and sparse online invocation. Each choice involves different latency and safety trade-offs. For camera-based vehicles, VLA's reasoning tasks can be divided into "long-term/slow decision-making" and "short-term/fast strategy prompts," leaving high-frequency control to dedicated controllers on the vehicle side while integrating VLA's high-level outputs as constraints or suggestions into the planner. This leverages VLA's versatility while meeting automotive-grade reliability requirements.
Summary
How will VLA be applied to autonomous driving in the future? In the short term, VLA's most realistic role is as a "cognition and strategy enhancement module." It handles semantic understanding, long-tail scenario summarization, and cross-scenario transferability, aiding pure vision systems' maturity in semantic judgment and strategy generation. In the medium term, with data accumulation, improved model inference efficiency, and advancements in interpretability technologies (e.g., controllability constraints and provably safe fallback), VLA is expected to undertake more high-level decision-making tasks and become an autonomous driving stack staple. Long-term, it aligns with the broader "embodied intelligence" vision, where vehicles are intelligent agents with long-term memory, world models, and natural language interaction capabilities. Paradigms like VLA will be foundational infrastructures, evidenced by open-source projects (e.g., OpenVLA) and commercial endeavors (RT-2, Helix, NVIDIA, and automotive research).
In summary, Vision-Language Alignment (VLA) is not a mere "shortcut" to replace pure vision systems. Rather, it represents a robust suite of tools and training paradigms. By leveraging language as a conduit, VLA elevates visual representations to the semantic level, fostering enhanced cross-scene generalization and fortified strategic learning capabilities. These attributes have a distinctly positive impact on the maturation of pure vision algorithms. For the industry, there are several promising investment avenues to explore: how to effectively harness pre-trained features from Vision-Language Models (VLMs), how to employ language signals as bridges for reinforcement and imitation learning, how to bridge the gap between simulations and real-world scenarios, and how to devise verifiable fallback and redundancy mechanisms. By addressing these issues comprehensively, VLA will undeniably emerge as a pivotal catalyst for the advancement of pure vision systems.
-- END --
-
![]()
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming