Which AI Excels at Generating Images?
 08/29 2025
08/29 2025
 773
773

AI's reach is expanding into every domain. Many illustration websites now routinely include an "AI generated" tag.
From an artistic standpoint, AI-generated images remain a subject of intense debate. Nevertheless, it's undeniable that in professional settings, AI image generation is a highly efficient tool.
Currently, the number of models supporting text-to-image generation within the realm of multimodal large models is surging.
To alleviate the "choice paralysis," we've selected six models for a comparative evaluation.
The contestants are:
Tencent Hunyuan, Zhipu CogView-4, Tongyi Qianwen, Jimeng, Keling, and Gemini 2.5 Flash Image.
Among them, the model nano-Banana, which recently gained popularity on LMarena, is rumored to outperform all other text-to-image models.
This claim has now been "verified" by Gemini 2.5 Flash Image, released by Google on August 27th.
Before diving into the evaluation, let me clarify:
I have no formal training in fine arts.
Therefore, we won't delve into intricate theories or obscure art history.
Instead, we'll use AI-provided scoring criteria to assess the images from an ordinary person's perspective, focusing on whether they are "pleasing to the eye." These are solely my opinions and are intended for reference.
01
First Dimension: Basic Aesthetics and Realism
Test Objective: Evaluate AI's basic drawing skills, focusing on aesthetics and realism.
Prompt: A young woman in the evening sunlight
Prompt: Hyper-realistic photo, a freckled young woman with a smile, sitting by the window during the golden hour, warm sunlight passing through her hair, cinematic lighting, 8K, high detail.
Scoring Criteria:

Evaluation Results:

Tencent: The character's skin texture is overly smooth, with minor flaws.
Zhipu: The skin is too smooth, and the freckles are uniformly distributed, appearing deliberate and thus flawed.
Qianwen: The hands' proportions and shapes are unnatural, lacking realism and exhibiting an "obvious AI look," which is a significant flaw.
Jimeng and Keling: Both are outstanding, approaching perfection, truly worthy of "professional artists."
Gemini: The skin texture is too smooth and delicate, lacking some realism.
Overall, the AIs are adept at shaping characters. Although some models generate images with minor flaws, the overall viewing experience is good.
02
Second Dimension: Imagination and Creativity
Test Objective: Evaluate AI's imagination and ability to create non-existent entities.
Prompt: A lion made of nebulae
Prompt: A majestic lion carved from rotating galaxies and nebulae, with cosmic dust forming its mane, eyes sparkling like stars, against a backdrop of the deep universe.
Scoring Criteria:

Evaluation Results:

This round's prompt seems challenging for the AIs.
Tencent: While visually impressive, there's a misunderstanding. This is a statue made of cosmic material, not a living being made of nebulae.
Zhipu: It generated a solid lion against a cosmic backdrop, a complete conceptual deviation.
Qianwen: It has a "half-god, half-beast" feel, mixing a solid lion with nebulae, but still not meeting the requirements.
Jimeng: It has a strong sci-fi vibe, but the lion's body remains solid, offering novelty in appearance.
Keling: The best performer, with excellent visual effects, achieving fusion with the nebulae.
Gemini: The lion's body is opaque, but its charm, quality, and details are good.
It seems that for non-existent entities, AI's likelihood of conceptual misunderstandings increases, and imagination remains a lacking area.
Reasons could include limitations in training data, physical world path dependence, or a lack of conceptual fusion ability.
03
Third Dimension: Instruction Comprehension and Execution
Test Objective: Evaluate AI's obedience and ability to follow instructions correctly.
Prompt: Math problems in a fruit basket
Prompt: A wooden bowl containing three red apples and two yellow bananas, placed on a white table.
Scoring Criteria:

Evaluation Results:

A simple problem for humans, but challenging for AIs.
Among the six models, only Zhipu, Qianwen, and Gemini correctly completed the instruction.
Jimeng and Keling miscounted the apples, while Hunyuan had numerous flaws.
Based on these results, we infer:
AI image generation models do not work according to our mathematical concepts or artistic processes.
Rather, they do not follow our direct train of thought, drawing one apple, then another banana, until the required number is met.
The number "3" in the instruction does not represent an exact quantity for AI but a "compositional feature" to be rendered.
In vector space, "three apples" and "four apples" may be very close.
Additionally, we cannot ascertain the training sets provided to these AIs.
Labels cannot be entirely accurate, and AI learns from massive but imperfect data over time.
The AI's ultimate goal is to generate images closest to the "three apples" it has seen before, rather than "generating a number of apples equal to 3."
04
Fourth Dimension: Style Imitation and Control
Test Objective: Evaluate AI's ability to imitate specific artists or artistic genres.
Prompt: Mech in ink wash style
Prompt: A giant ancient Chinese mech warrior standing in a misty valley, in the style of traditional Chinese ink wash landscape painting.
Scoring Criteria:

Evaluation Results:

Another abstract prompt.
Gemini performed best, drawing in a landscape painting style, largely meeting the requirements.
Qianwen's mech looks imposing with detailed handling, but it's clearly a sketch, lacking the spirit of ink wash style.
Jimeng's image is also not an ink wash painting but a digitally painted piece with a realistic feel, resembling game concept design.
Keling demonstrated excellent splicing ability, inserting a Japanese-style mech into an ink wash background, with a disjointed style.
Hunyuan and Zhipu's images are strange, failing to achieve the ink wash style and misunderstanding the "mech warrior" subject, depicting figures more like ancient warriors.
It seems AI does not yet fully imitate specific artists or genres, and achieving "resemblance in form but not in spirit" is challenging.
05
Fifth Dimension: Cultural Understanding and Conceptual Expression
Test Objective: Evaluate whether AI can understand specific cultures and express abstract concepts.
Prompt: A Hanfu girl celebrating Mid-Autumn Festival
Prompt: A beautiful young girl dressed in traditional Chinese Hanfu, celebrating Mid-Autumn Festival, holding a delicate rabbit lantern, with a bright full moon behind her.
Scoring Criteria:

Evaluation Results:

Gemini and Keling scored high, demonstrating high cultural literacy.
They understand Hanfu and cultural elements like the moon, lantern, and garden.
It's speculated their training data on traditional Chinese culture is accurately labeled.
These models' algorithms correctly associate keywords like "Hanfu" with visual features.
Jimeng and Qianwen succeed in aesthetics and atmosphere but have blurry Hanfu structures.
While this ancient-style painting suggests AI's limited historical knowledge of clothing, it still meets the "pleasing to the eye" requirement.
Zhipu generated the only anime-style image, lacking depth in historical culture reproduction.
Hunyuan's image is beautiful but has obvious clothing structure errors, indicating cultural confusion.
Therefore, AI's cultural expression has a "double-edged sword" effect.
Top-tier AI possesses considerable cultural knowledge, aiding in the dissemination and creation of excellent traditional culture.
However, some AIs still have "stereotypes" influenced by low-quality data, potentially exacerbating cultural misunderstandings.
06
General Evaluation
The total scores are:
Gemini: 44 points
Keling: 40 points
Jimeng: 39 points
Qianwen: 38.5 points
Zhipu: 33.5 points
Tencent: 28.5 points
In terms of effect, Qianwen, Jimeng, Keling, and Gemini perform well in text-to-image generation.
Especially Gemini 2.5 Flash Image, the former nano-Banana, scored highest, proving its worth.
However, our core goal is to see through the phenomenon to the essence.
People are amazed by AI's "creativity," which surpasses most people's drawing skills.
But AI images do not originate from human-like inspiration or intention.
AI does not draw like an artist, starting from a blank sheet and drawing stroke by stroke.
Instead, it starts from a "chaotic canvas" filled with random noise points and performs denoising based on prompt words.
In other words, AI image generation is based on probability, not logical reasoning.
The apple count error may stem from the frequent appearance of the instruction "compose a harmonious still life of fruit" in training data, outweighing the numerical symbol "3."
The struggle between nebulae and lions may be due to conflicting pixel patterns: "lions" are "solid" and "hairy," while "nebulae" are "gaseous" and "translucent." AI cannot satisfy both probability distributions simultaneously, leading to denoising failure.
For the mech in ink wash style, it's the AI's database at work. If there are high-quality labels like "ink wash" and "mech," the denoising process will guide to a high-quality probability space.
In simple terms, AI does not draw based on instructions but attempts to give the most probable image matching the instructions through denoising based on its knowledge base.
Regarding errors, text-to-image generation is complex, and we cannot pinpoint the exact issue.
Therefore, at least for now, we are not "creators" but "probability guides."
-
![]()
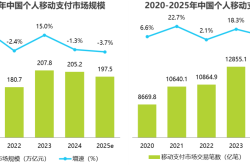
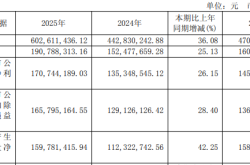
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming