How Far Can VLA and World Models Propel Autonomous Driving?
 09/01 2025
09/01 2025
 736
736
Imagine navigating a rainy night intersection. You're mid-road, with a hesitant e-bike ahead and a taxi signaling to turn left. Suddenly, a bright pair of high beams flashes from behind and to your right. What do you do? Experienced drivers swiftly analyze: the e-bike might dart across, the taxi could merge lanes, and the trailing car is too close for sudden braking. The safest move is to slow down, creating space around you. This apparently quick decision encompasses perception, prediction, reasoning, and trade-offs.
But what if this scenario were entrusted to autonomous driving? Traditional systems are rule-based and rely on simplistic predictions. They can detect the e-bike, identify the taxi, and recognize the high beams, but they may not "decipher" the intentions and logic behind these signals like humans. Consequently, the car might either halt overly cautiously or rush out recklessly, ultimately lacking human intuition. This prompts the industry to ask: can cars be equipped with the ability to "understand and reason"? The answer lies in the burgeoning fields of VLA (Vision-Language-Action) and World Models.
Autonomous driving's development over the past decade has been as tumultuous as a rollercoaster. Early solutions believed that a modular system combining perception, prediction, planning, and control, backed by comprehensive rules and ample data, could enable autonomous driving. However, as projects scaled, practitioners realized this approach's inherent limitations. The modular chain is lengthy, with significant information loss between links, and manual interfaces hinder joint system optimization. Even with vast resources, covering long-tail complex scenarios is challenging. VLA and World Models enable cars to transcend mere "rule execution" and engage in "understanding and reasoning" akin to humans.
The Logic of VLA: From 'Seeing' to 'Thinking'
VLA's essence shifts autonomous driving from purely data-driven to knowledge-driven. Past end-to-end attempts directly linked image input to vehicle action output, lacking interpretability in between. Conversely, VLA leverages multimodal large models, encoding visual, point cloud, map, and sensor information into a unified semantic space, then using language models for logical reasoning and high-level decision-making. In other words, it empowers the car to not only 'see' but also 'think'. The visual encoder extracts features from images or point clouds, the alignment module maps these features to the language space, the language model functions as the 'reasoning area' of the human brain, drawing conclusions based on context and logic, and finally, the generator converts this high-level intention into executable vehicle trajectories or actions. VLA, for the first time, brings the cognitive process of human driving into the machine world in a relatively complete manner.
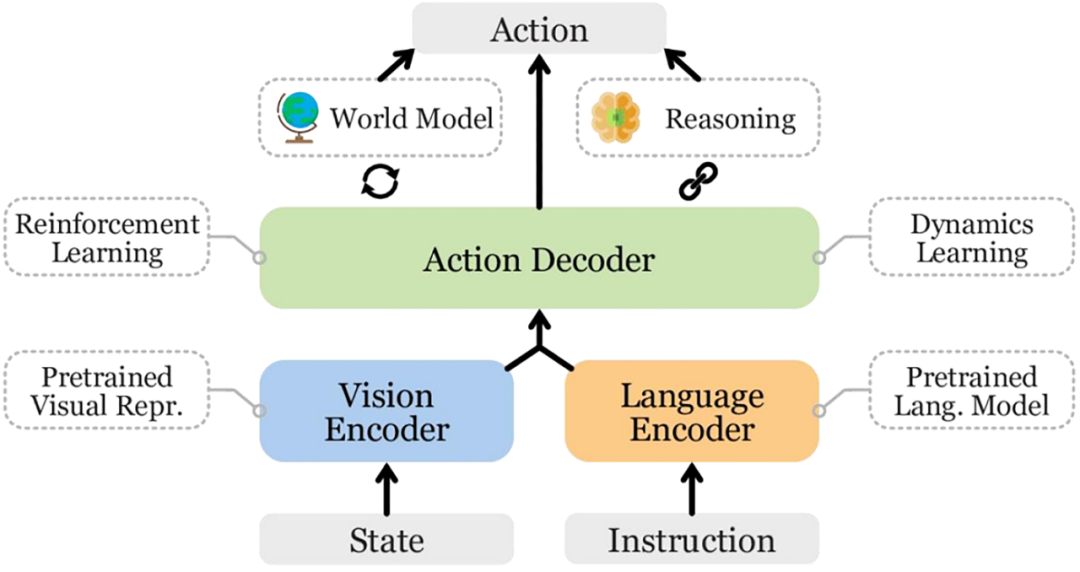
The overall architecture of the VLA model, encompassing encoder, decoder, and output actions.
To make VLA truly functional, three major technical challenges must be addressed. First, representing 3D features. Cars operate in a three-dimensional world, where two-dimensional image information is insufficient. The 3D Gaussian Splatting technique, frequently mentioned in recent years, aims to solve this. It uses Gaussian distributions to explicitly represent 3D points, saving computing power compared to traditional voxel grids while achieving real-time rendering. Implicit scene representations like NeRF render extremely realistically but require too much computation, making them impractical for on-vehicle use. 3D GS strikes a balance between efficiency and realism, making it a candidate for intermediate features for many teams. However, it's highly dependent on the initial point cloud's quality, necessitating accurate data collection; otherwise, rendering results will be significantly affected. Overall, 3D GS is a crucial step in enabling cars to understand the world in a more 'three-dimensional' manner.
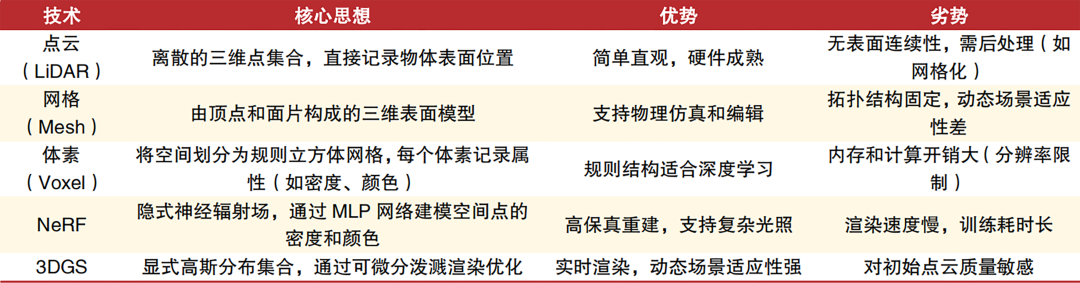
The difference between 3D GS and other 3D reconstruction techniques.
The second challenge is memory and long-term sequential reasoning. Driving is a continuous task, not a single-frame reaction. The car must remember traffic participants' behavior for several seconds to judge their intentions to overtake, turn, or go straight. However, traditional Transformers are computationally expensive when processing long sequences, and once the window exceeds a few thousand steps, computation becomes unmanageable, and information is easily diluted. To solve this, some techniques introduce sparse attention and dynamic memory modules. Sparse attention significantly reduces computational complexity by focusing on key locations, while dynamic memory acts like an external storage, extracting and saving key historical information for retrieval when needed. This approach enables the model to handle long-term dependencies without crashing in environments with limited on-vehicle computing power. Xiaomi's QT-Former optimizes long-term memory, and Ideal's Mind architecture explores similar ideas, indicating industry consensus.
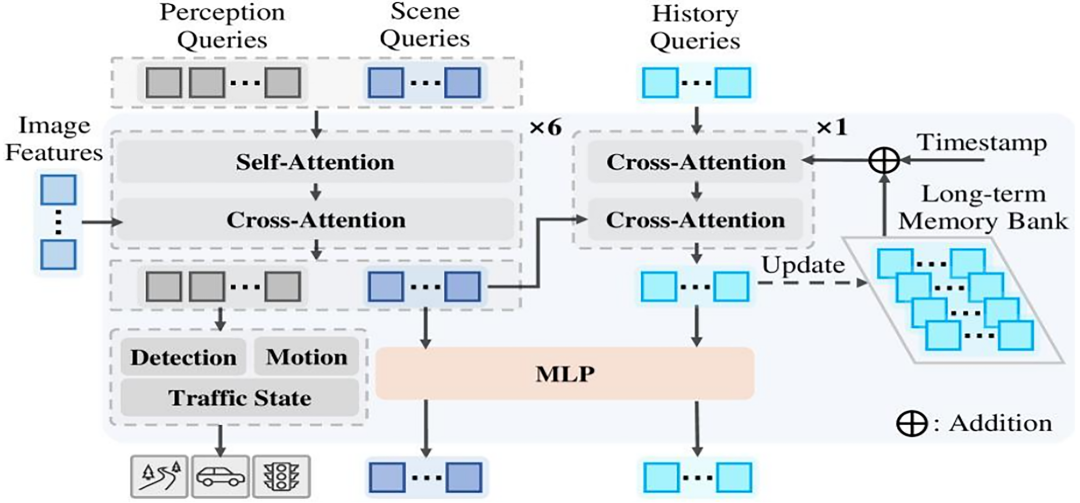
Xiaomi QT-Former model architecture.
The third challenge is reasoning efficiency. On-vehicle computing power and power consumption are limited, prohibiting the stacking of unlimited GPUs like in the cloud. Therefore, traditional model compression methods like quantization, distillation, and pruning are essential for deployment. Ideal adopts post-training quantization methods like GPTQ to shrink large models for real-time operation, while also exploring Mixture of Experts (MOE) models to reduce overhead by activating only select experts. This architecture maintains large models' capabilities without slowing down the entire system due to reasoning speed. Zhijia Qianyan believes that future on-vehicle large models will inevitably adopt a 'sparse + quantized' form, as otherwise, it would be infeasible in terms of energy consumption and cost.
World Models: The Proving Ground in a Virtual World
If VLA is the car's 'brain', World Models are its 'training ground'. Real-world data cannot cover all situations or allow infinite trial and error. High-fidelity World Models generate diverse road scenarios, supplement long-tail data, and provide a low-cost, safe closed-loop environment for models to learn repeatedly in a virtual world. Ideal's DriveDreamer4D is a prime example, capable of generating new trajectory videos aligned with real data to expand datasets; ReconDreamer reduces artifacts in long-distance generation through progressive data updates; and OLiDM addresses LiDAR data scarcity by using diffusion models to generate point clouds. These names may sound academic, but essentially, they all aim to restore the real world's complexity using virtual means, allowing models to adapt in advance to future situations.
In terms of training paradigms, both VLA and World Models have evolved. Previously, behavioral cloning, where the model imitates human driving, was prevalent, but this often fails in unseen situations. Now, a three-stage closed loop is more common: behavioral cloning to establish a foundation, inverse reinforcement learning to learn reward functions from expert data, and finally, continuous iterative optimization through reinforcement learning in World Models. This approach enables the model to not only imitate but also explore better solutions independently, gradually surpassing human demonstration levels.
Industry Perspective: Why are Car Companies Racing Ahead?
Integrating large language models into autonomous driving isn't as simple as turning a car into a chatbot. VLA's core lies in 'multimodal' and 'action generation'. The visual encoder must encode images, videos, and even point clouds into language-friendly intermediate representations; the alignment module maps these visual representations to the language space; the language model handles long-term reasoning and decision-making; and the decoder refines high-level intentions into executable vehicle actions or trajectories. Cars' tasks are relatively simple—driving—and scenarios are rule-based, with clear road markings, traffic lights, and vehicle behavior constraints. Coupled with car companies' vast fleets and data collection capabilities, VLA can easily form a scale effect on vehicles. This explains why domestic and foreign manufacturers are entering this field. Waymo launched the EMMA system, setting the direction; Ideal is building a comprehensive Mind architecture, Xiaomi is testing QT-Former in mass-produced vehicles, Xpeng is attempting end-to-end large model integration, and Huawei is reserving large model interfaces on the MDC platform for future use. Different companies have distinct approaches, but the goal is the same: to equip cars with enhanced understanding and reasoning capabilities.
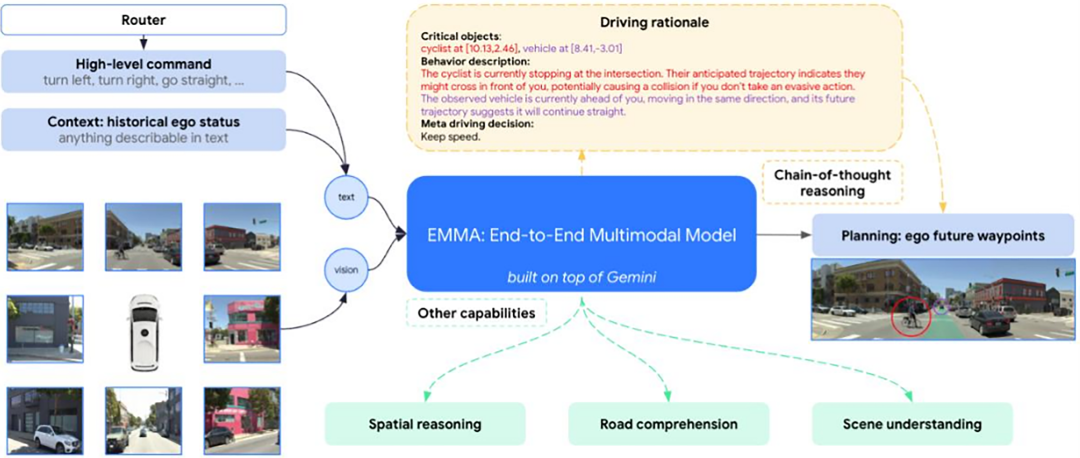
EMMA model architecture.
Closing Remarks
In summary, the fusion of VLA and World Models signifies a cognitive upgrade in autonomous driving. They represent not just algorithmic improvements but paradigm shifts, moving from 'seeing and driving' to 'thinking and reasoning'. This path is fraught with challenges in 3D representation, memory mechanisms, computational constraints, and simulation fidelity. However, as architectures mature, World Models become more realistic, and closed-loop training becomes more sophisticated, we have reason to believe that future autonomous driving will transcend being a cold perception and control machine, evolving into a 'driving agent' that understands the environment, explains behavior, and interfaces with human logic. Whoever can first translate these technologies into large-scale, real-world experiences will take the lead in the next phase of competition.
-- END --
-
![]()
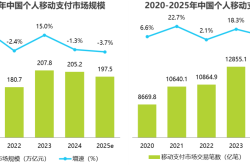
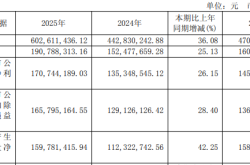
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming