The Second Half of Big Models: Uncovering the Data Annotation Landscape
 09/02 2025
09/02 2025
 601
601

In the latter stages of AI training, data emerges as the focal point.
Two months ago, Meta invested approximately $15 billion (roughly RMB 107.8 billion) in Scale AI, acquiring a 49% stake. Post-transaction, Scale's valuation soared to $29 billion.
As a formidable dark horse in the Silicon Valley AI race in recent years, Scale AI catapulted from inception to a $13.8 billion valuation in just five years, almost becoming an industry legend.
The company's core business revolves around data annotation. With a low barrier to entry for employees and extensive human involvement, this seemingly mundane and labor-intensive field has long been overlooked as the least glamorous and imaginative part of the AI industry chain.
However, it is precisely through this "unglamorous work" that Scale has swiftly transitioned from behind the scenes to the forefront in the era of large models, becoming Silicon Valley's hottest star company. Meta's move has further propelled the data annotation industry, which was originally at the bottom of the chain, into the limelight.
More intriguing is that this acquisition goes beyond a mere "bet" at the capital level.
As part of the deal, Scale's founder and CEO Wang Tao will step down and lead a team of core employees to join Meta, forming the so-called "Super Intelligence Group," while retaining a seat on the Scale board. In essence, Meta is not just acquiring data; it's also buying Wang Tao's strategic vision and execution prowess.
Behind this aggressive acquisition lies Meta's data anxiety.
In 2024, Meta's Llama4Behemoth faced heavy criticism for the quality of its training data. About 30% of the corpus originated from low-quality social media content, causing the model to lag behind GPT-4.5 by approximately 12% in key metrics such as multimodal understanding and long-text reasoning. For Meta, the scarcity of high-quality data has emerged as the greatest hindrance to its model's advancement.
As AI model training becomes increasingly reliant on data, data annotation, the first line of defense in model training, is being reevaluated for its strategic importance.
From Laborious Work to Intelligence: The Evolution of Data Annotation
What is Data Annotation?
In essence, data annotation involves labeling raw data to transform "information that humans can understand" into "training samples that AI can recognize." For instance, in autonomous driving scenarios, vehicles upload road images, but AI cannot directly interpret them. Only when human annotators meticulously frame and label elements like lane lines, road signs, and pedestrians do these images become truly valuable for training.
This industry broadly encompasses three types of players:
The first type comprises purely human-powered companies. Relying on a vast pool of low-cost laborers to complete annotations, they are ideal for standardized tasks such as image classification and speech transcription. The technical threshold is low, and clients often need to bring their own tools and platforms, aligning with the public perception that "data annotation is manual labor."
The second type includes crowdsourcing platforms of internet giants. Typical examples are JD Intelligence and Baidu Crowdsourcing, primarily used to fulfill the company's own business needs and then distribute tasks to external labor pools through a crowdsourcing mechanism.
The third type consists of intelligent service providers. These companies possess the capability to independently develop platforms and algorithms, offering automated annotation tools, quality control systems, and highly customized solutions. They excel in complex tasks such as 3D point clouds and multimodal tasks, often surpassing peers significantly in efficiency and accuracy.
For a long time, the first two types of companies have essentially been "labor-intensive" enterprises with limited scale and profit margins, and a distinct ceiling. Especially the first type, more often than not, serves as an outsourcing pool for the third type of intelligent companies. In fact, most of today's leading intelligent enterprises have evolved from such labor-intensive origins.
Taking industry leader Scale AI as an example, its predecessor was actually called "ScaleAPI." Initially, it wasn't a data platform company but provided a "human API": developers only needed to write one line of code to dispatch a remote labor team to assist with tedious tasks like content review, data extraction, and appointment scheduling.
This lightweight model driven by manual labor not only helped Scale secure early major customers such as Toyota and Honda but also amassed a substantial amount of high-value data.
With the accumulation of basic data and the advancement of AI capabilities, since 2018, Scale has gradually replaced some repetitive and routine manual tasks with models, establishing a hybrid workflow of "machine pre-annotation + manual review." Initially, the algorithm handles the pre-annotation, followed by human experts reviewing and correcting it.
This AI-replacement model has resulted in double improvements in efficiency and quality for the company. According to OpenAI's calculations, the average annotation cost of ChatGPT is less than $0.003, which is 20 times cheaper than traditional crowdsourcing platforms. In terms of accuracy, the annotation results completed by GPT-4 can reach 88.4%, even surpassing the 86.2% of human annotators.
Global Data Annotation Landscape: Why Does the United States Account for 40%?
According to a forecast report released by DMR (Dimension Market Research) in July 2024, the global data annotation industry market size is approximately $2 billion, with the US market size being $838 million, accounting for roughly 40% of the share. This is the latest data available.
Why has the United States long dominated the global data annotation industry?
On one hand, data annotation is inherently a labor-intensive industry. The low entry threshold and high mobility of annotators make labor almost the core competitiveness for cost control.
To mitigate organizational pressure, companies often opt to outsource or crowdsource projects. In this regard, American companies leverage the benefits of global division of labor to outsource basic annotation tasks to low-cost countries, achieving extreme cost compression.
A case in point is Scale AI, which distributes the most basic framing and annotation tasks through its crowdsourcing platform Remotasks to low-cost regions such as the Philippines and Kenya. In addition to the 900 official employees disclosed on the official website, there are over 240,000 registered workers on its platform, spanning the globe.
Secondly, there's a significant gap in technical proficiency and automation between domestic and foreign manufacturers. Currently, the largest domestic annotation company, CloudMinds Data, attempted to introduce automatic annotation functions as early as 2021, but the application scope is still mainly concentrated in the field of intelligent driving. Another company, Hispeech, which focuses on speech, is also developing tools such as automatic speech segmentation, but the overall level of intelligence is limited and still heavily reliant on manual labor.
In contrast, Scale AI deployed automated annotation in 2018. Though it also started in autonomous driving, its business has expanded to fields such as language, finance, healthcare, and even military.
More importantly, Scale AI is not just a data annotation company. Wang Tao, who was heavily recruited by Meta with a substantial sum, is renowned as a Chinese-American "prodigy." At the age of 19, he dropped out of the Massachusetts Institute of Technology in the United States to found Scale AI. In a recent interview, he mentioned that not only data annotation but also the recruitment process, quality control process, data analysis, sales reports, and other aspects have already been automated by Scale AI.
To some extent, as an industry born out of the demand for large model training, the shortcomings of domestic enterprise layout are largely determined by the lack of market demand.
The two largest service scenarios for data annotation are large models and autonomous driving, and the absolute main forces in these two industries are mostly distributed in the United States. Due to the inherent privacy and security considerations of data, companies prefer to collaborate with domestic annotation providers.
As a result, the United States has not only nurtured versatile players like Scale but also companies like SurgeAI and Turing that specialize in fine-tuning services, as well as data companies like Lionbridge that focus on text and speech.
In contrast, due to the relatively dense labor force in China, internet giants typically adopt a crowdsourcing model rather than specialized annotation companies, and under the premise of some models using distillation, the domestic market demand is far less than that of foreign countries.
In the Second Half of Large Models, the Status of Data Annotation is Reversing
With the rapid iteration of AI technology, there was once a prevailing view in the industry that AI annotation and synthetic data would completely replace manual annotation. However, based on current technological realities, this possibility is still a distant prospect.
The premise of AI annotation is that the data structure and rules are highly defined and supported by sufficient historical samples. Therefore, its application scope is naturally limited and can currently only cover relatively standardized tasks such as traffic images and face recognition.
In terms of workflow, AI primarily replaces the midstream part of annotation, while key nodes such as rule formulation and quality control still necessitate human intervention.
Simultaneously, as large models increasingly emphasize vertical scenarios, the focus of training has shifted from pre-training to reinforcement learning. Unlike pre-training, which has relatively lax requirements for data quality, reinforcement learning relies more on high-precision and specialized data, often involving high-threshold fields such as medical imaging, legal texts, and emotional language.
This change has made the role of annotators increasingly complex.
They not only need to possess professional knowledge but also require abstract thinking and interdisciplinary abilities. As an industry insider noted, today's tasks often involve new scenarios such as reasoning chains and multimodal alignment, "which are no longer solvable by simple framing and classification."
Surge AI is a typical representative of this trend. Since its inception in 2020, the company has focused on generating high-quality data, such as providing high-quality code data for programming models to enhance model performance. With this positioning, Surge AI's revenue in 2024 reached $1 billion, even surpassing industry leader Scale AI's $870 million.
Another promising alternative path is synthetic data. Theoretically, it can fill the gap when data is insufficient, but practical issues cannot be overlooked: synthetic data is generated under existing conditions, and when real-world scenarios change, it's challenging to maintain its effectiveness; simultaneously, data security risks also limit its large-scale generalization potential.
From this perspective, data annotation will not disappear but will evolve towards higher quality and stronger specialization.
Looking back, data annotation has long been considered the weakest link among the "three carriages": OpenAI for algorithms, NVIDIA for computing power, and even in the field of data annotation, the market value of industry leader Scale AI is less than one-tenth of that of OpenAI.
The reason, to a large extent, stems from the low industry threshold and limited income ceiling. However, as AI model training enters its second half, the technical barriers of data annotation are constantly being raised. Meta's acquisition of Scale AI is just the beginning. In the near future, data resources are being propelled to the core of industrial competition.
-
![]()
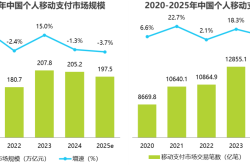
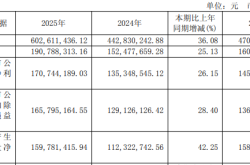
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming