What is the Role of GOD Often Mentioned in Autonomous Driving?
 11/03 2025
11/03 2025
 625
625
In the realm of autonomous driving, "obstacle detection" stands as a pivotal and frequently debated topic. Within this domain, there exists a more specialized subset known as "General Obstacle Detection" (GOD, General Obstacle Detection). The impetus behind studying GOD lies in the limitations of traditional object detection systems, which typically recognize only a predefined set of categories, such as pedestrians, vehicles, bicycles, and traffic cones.
However, real-world traffic scenarios are replete with unexpected objects. Examples include fallen cargo containers, overturned fences, large plastic sheets suddenly appearing on the road, animals, temporarily placed toolboxes, plastic films obscured by rain reflections, and even oddly shaped debris. These items, though categorized as "unknown," are real and cannot be overlooked by autonomous driving systems.
The mission of GOD is to universalize obstacle detection. It must not only identify objects from known categories but also detect abnormal objects absent from the training set, providing a critical safety foundation for subsequent tracking, prediction, and planning modules.
To simplify, GOD must do more than just recognize "that is a pedestrian" or "that is a vehicle." It must accurately inform, under varying lighting, weather, and speed conditions, that "there is an entity ahead that will obstruct or affect driving safety." This capability is particularly crucial in complex urban road conditions, temporary construction zones, and adverse weather, as autonomous driving cannot rely solely on recognizing a few fixed labels to ensure safety; it must remain highly sensitive to unknown, rare, and dangerous situations.
How Does GOD Operate?
The input sources for GOD are diverse; the most common are camera images and LiDAR point clouds, sometimes fused with millimeter-wave radar or ultrasonic sensor data. Cameras are inherently sensitive to semantics and textures, while LiDAR provides precise three-dimensional geometric information.
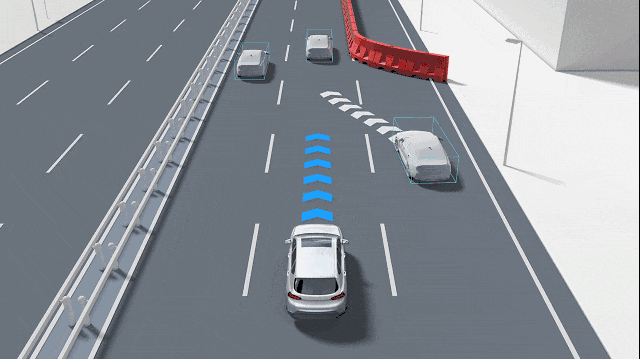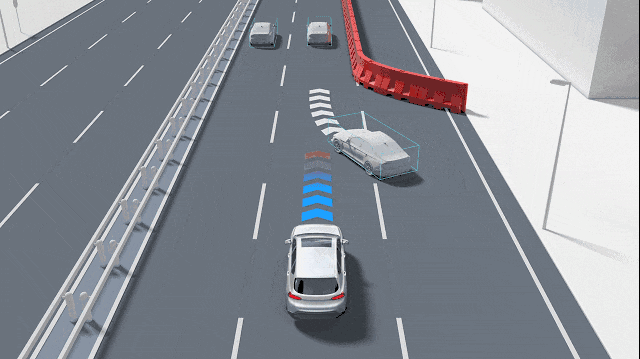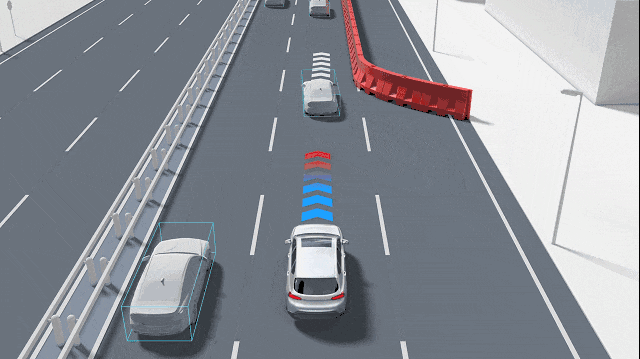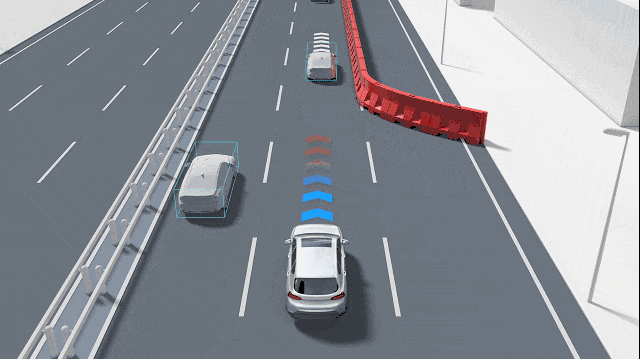
Image Source: Internet
The core task of a practical GOD system is to integrate information from different sensors and output a unified set of "candidate obstacles." These obstacles can be represented as bounding boxes, segmentation masks, or occupancy grids in a bird's-eye view. Furthermore, each candidate obstacle is accompanied by key attributes, such as confidence (the certainty that the object is an obstacle), speed estimation (how fast it is moving), category probability (if identifiable), and uncertainty assessment (a score indicating the reliability of all the above judgments).
Some GOD systems adhere to typical detection architectures, initially extracting features using convolution or Transformers, then outputting bounding boxes and classification information through detection heads. Unlike conventional obstacle detection, GOD emphasizes two key aspects: first, the ability to handle "open-set" problems, i.e., recognizing objects where "I don't know what it is, but it's important"; second, greater robustness to small objects, transparent objects, reflective objects, and partially occluded objects. To achieve these goals, many solutions incorporate anomaly detection submodules, output segmentation masks, and fuse geometric consistency checks (e.g., comparing LiDAR depth projections with camera detection results and raising alert levels when inconsistencies arise).
For GOD, the temporal dimension is vital. GOD does not make judgments based solely on a single image frame but combines temporal information to enhance stability. Through kinematic consistency tracking, it can filter out temporary false detections and maintain objects that have been temporarily occluded but are already on the trajectory.
Core Technical Points and Implementation Details of GOD
GOD can be implemented using traditional one-stage or two-stage detectors. One-stage detectors (such as anchor-based RetinaNet or anchor-free CenterNet, FCOS) directly predict object positions and categories; two-stage detectors (such as the Faster R-CNN series) first generate candidate regions and then perform fine classification and adjustment. In recent years, Transformer architectures (such as DETR and its series of models) have also been introduced into the field of obstacle detection, enabling direct modeling of global contextual relationships. However, in practical applications, computational costs and convergence speeds still need to be balanced.
In backbone network design, models must strike a balance between performance and efficiency. For visual inputs, classic networks like ResNet and EfficientNet are commonly used to extract features. To accommodate the computational limitations of automotive-grade chips, lighter-weight networks like MobileNet and GhostNet are also employed. For LiDAR point cloud data, common processing methods include voxel-based 3D convolutions, point-based direct processing with PointNet/PointNet++, or the use of more efficient sparse convolution architectures in recent years.
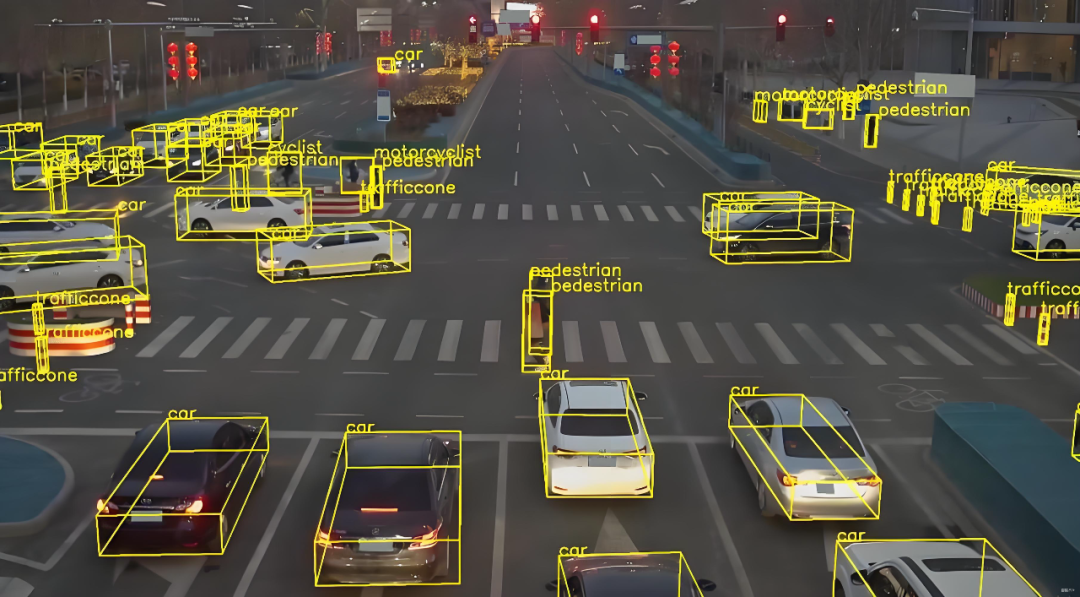
Image Source: Internet
GOD not only optimizes target localization and classification accuracy but also introduces specialized anomaly/novelty losses to enhance sensitivity to unseen categories. Some technical solutions employ contrastive learning or self-supervised pre-training to help the model grasp the distribution of "normal backgrounds," making it easier to identify objects that deviate from this distribution. Another approach is to split the detection task into two parts: conventional finite-category detection is optimized using cross-entropy or Focal Loss, while "general object presence" is represented through self-supervised anomaly scores or reconstruction errors.
Training data is pivotal for determining effectiveness. To enable detectors to perceive various "strange" objects, relying solely on existing driving datasets is insufficient. Additional rare samples, synthetic data, or abnormal scenarios generated in simulation environments must be introduced to expand the training set. Common data augmentation techniques include random occlusion, color perturbation, lighting variations, and geometric distortions. More advanced methods involve combining single-frame images with dense depth or bird's-eye projections generated by LiDAR, using geometric consistency supervision to enhance detection capabilities for transparent or reflective objects.
After delving into so many technical details, what about the actual performance of GOD? Traditional object detection relies on static metrics such as mAP (mean Average Precision), precision/recall rates, and IoU (Intersection over Union) for evaluation. However, these metrics are not entirely suitable for General Obstacle Detection (GOD), which must consider the actual risks posed by missed detections and false alarms. Missing a box on the road could directly lead to a collision, while frequent false alarms could trigger unnecessary emergency braking, severely affecting the riding experience and posing unnecessary following risks. Therefore, GOD's evaluation system must transcend static metrics and incorporate dynamic factors that reflect real-time threat levels, such as "critical safety distance" or "time to collision."
What Challenges Does GOD Face?
Applying GOD to real vehicles encounters numerous practical issues. Due to the inherent limitations of sensors, camera performance degrades at night or under backlighting conditions, LiDAR is insensitive to transparent objects (such as glass or films), and millimeter-wave radar has low resolution for small objects. This necessitates mutual complementarity among different sensors. To address this, a prudent approach is to fuse detection results from different sensors. If the camera identifies an object with distinct textures but the LiDAR receives no echo, the system does not immediately draw a conclusion but marks it as a "high-uncertainty" obstacle and hands it over to the tracking and rule modules for continuous observation. Meanwhile, the system also makes judgments based on scene context to ensure driving safety, such as increasing detection sensitivity in construction zones based on high-precision maps or geographic database information.
Because real-world traffic environments are open and prone to long-tail problems, the variety and forms of objects on real roads will inevitably far exceed the coverage of training sets. Therefore, it is necessary to expand the training set, annotate rare scenarios, and strengthen sampling. Unsupervised/self-supervised methods should also be employed to establish a "normal world" model, treating any objects that deviate from the normal distribution as potential obstacles. Additionally, meta-learning or few-shot learning can be used to enable the model to quickly adapt to newly emerging categories.
When a vehicle is traveling at high speeds, the detection module's latency must be controlled within tens of milliseconds, while computational power is limited by the onboard computing platform (often a power-constrained and heat-dissipation-limited automotive-grade SoC). To ensure normal GOD detection, extensive optimization work is required, including model compression, quantization, using efficient operators to accelerate inference, scheduling part of the computational tasks to dedicated accelerators, and implementing priority management at the system level (e.g., setting lane keeping and nearest obstacle detection ahead as higher priorities). Designing degradation strategies is also essential; when computational resources are tight or sensors malfunction, the system should be able to switch to more conservative but reliable perception/planning modes, such as reducing speed, increasing safe following distances, or handing over control to remote human monitoring.
A qualified GOD system must not only perform well on standard test sets but also be able to handle adversarial attacks (e.g., sticker interference targeting cameras), optical distortions, and partial sensor failures, with clear degradation handling mechanisms. Therefore, large-scale corner case testing in simulated scenarios is necessary, even replaying real-world failure samples in simulation environments for stress validation to ensure robustness.
Final Remarks
The goal of GOD is to harmonize an open, infinitely possible physical world with a closed, data-driven computational system. It is not a static model but a dynamic, continuously learning "ecosystem." The system's effectiveness directly depends on its ability to successfully translate "unseen" threats in the real world into "uncertainties" or "anomalies" that the algorithm can understand.
-- END --
-
![]()
It's already crowded in car manufacturing, yet Chunnan insists on joining in.
-
Confirmed: Fossil Fuel Vehicle Ban! Hainan Unveils New '15th Five-Year Plan', Weakening Passenger Vehicle Sector and Initiating Petroleum Asset Depreciation
-
![]()
Research on the Underlying Industrial Logic of the Booming Sales of Chinese Action Camera Brands in Japan and the Decline of GoPro: The UGC+AIGC Creation Wave Reshapes the Market Landscape
-
![]()
Half-Year In-App Purchases Reach 105 Billion: The Most Lavish Starting Point and the Most Challenging Second Half
-
![]()
AI Enters Its Next Phase: From DeepSeek to Robots, What Lies Ahead for AI?
-
![]()
Jieyue Paves the Way for Agents with a New Phone and AgentOS
-
![]()
Research on the Industrial Logic Behind the Surge of Chinese Action Camera Brands in Japan and GoPro's Decline: How the UGC+AIGC Creative Wave is Reshaping the Market
-
![]()
Has Doubao Started Charging? Does ByteDance Face Commercialization Pressure?





