Google's 'Banana' Outperforms Photoshop, Revolutionizing the Global Software Industry
 11/04 2025
11/04 2025
 629
629

When it comes to the hottest AI applications, Google's 'Banana'—Nano Banana—takes the crown.
Originally named Gemini 2.5 Flash Image, Nano Banana quickly became better known as 'Banana' after its reveal.
Google, 'listening to the feedback,' promptly reverted the model's name.
Whether in text generation or image editing, Nano Banana demonstrates an unparalleled lead.
First, let's look at the ratings:
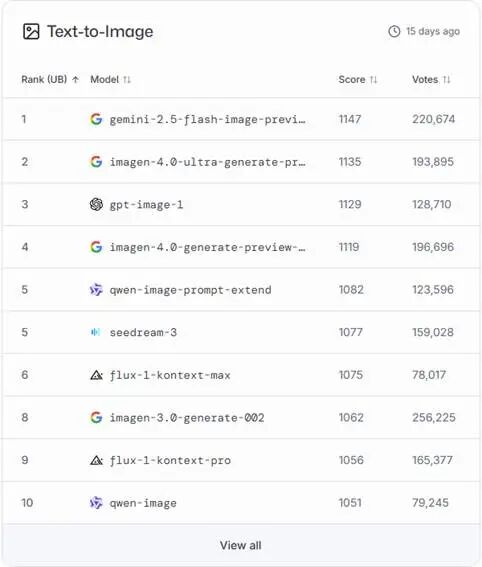
Figure: LMarena Text-to-Image Model Rankings
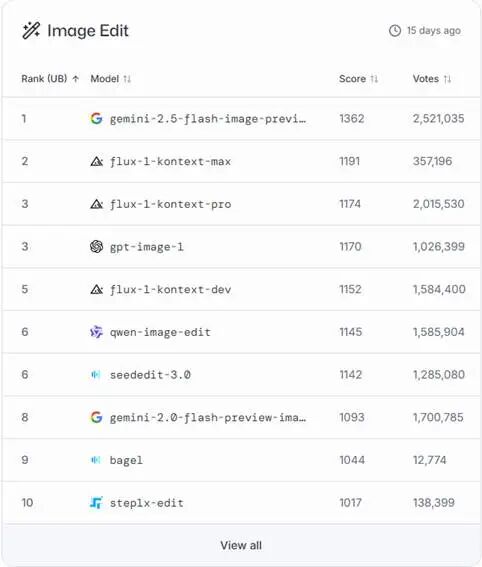
Figure: LMarena Image Editing Model Rankings
As seen, its text-to-image capabilities rank among the best, while its image editing prowess is overwhelming, nearly dismantling Photoshop's dominance.
We can confidently say that with Nano Banana, the global software industry has undergone a seismic shift.
01 User Experience: 'Astonishing' Falls Short
In truth, 'astonishing' barely captures Nano Banana's power.
In previous text-to-image evaluations, we've witnessed its capabilities.
However, according to the Gemini API documentation, it has several other 'killer features':

Before Nano Banana appeared on LMarena, most large models struggled with text in text-to-image generation.
Even with English words, the output often resulted in incomprehensible gibberish.
Nano Banana effortlessly overcame this challenge.

Recently, Nano Banana went viral online after users discovered its ability to create highly detailed figurine images.
The figurines in the images are indistinguishable from real ones, potentially fooling even enthusiasts.
Additionally, Google explicitly highlighted Nano Banana's other image generation strengths:
Such as realistic scenes, stylized illustrations and stickers, product mockups and commercial photography, minimalist designs, and negative space utilization.
In image editing, Nano Banana excels at tasks like adding and removing elements, local retouching, style transfer, combining multiple images, and high-fidelity detail preservation—effectively solving the 'change one thing, affect everything' issue prevalent in previous models.
This may sound abstract, so let's explain with examples from the Nano Banana team's interview.
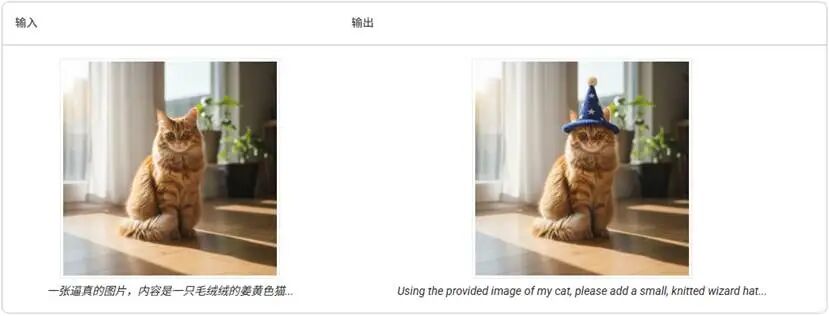
① Pixel-Level Retouching and Editing
One of the most common needs: modifying a single detail in an image while keeping everything else unchanged.
Removing passersby from travel photos or erasing dark circles from selfies posed significant challenges for previous multimodal models.
Minor edits often disrupted the image's overall style or structure, severely degrading the visual experience.
Robert Riachi mentioned in an interview that a major challenge during the model's 2.0 version was maintaining consistency with other image parts during editing.
However, through continuous 'iterative training' and user feedback collection, Nano Banana achieved marked improvements.
Whether adding a hat to a kitten or reorienting furniture, it preserves the scene's overall composition and structure, seamlessly blending edited parts with the rest of the image.
This precise control is vital for creative scenarios demanding high consistency.
② Multi-Angle Rendering
Although images are 2D, they represent 3D content.
Thus, accurately editing real-world objects requires AI to possess some 3D spatial understanding.
NanoBanana can render characters and objects from different angles, creating entirely new scenes.
For instance, uploading a furniture image and regenerating it from the side or back maintains high consistency.
This capability involves more than pixel duplication; it substantively transforms the original image by understanding the object's appearance and underlying structure, thereby expanding creative freedom.
③ Interleaved Generation
Images contain more information than text.
For complex image generation tasks, Nano Banana introduces a new 'interleaved generation' paradigm.
Traditional text-to-image models process all details at once, easily becoming 'saturated' when instructions contain numerous modifications or elements.
Nano Banana's solution is to 'break it down.'
It decomposes complex prompts into multiple steps, editing or generating incrementally.
This step-by-step approach enhances precision in detail handling.
Simultaneously, it accumulates contextual information, enabling the creation of highly complex and high-quality images.
The creative process becomes more flexible and controllable, significantly boosting the model's ability to handle intricate tasks.
④ Exceeding User Expectations
Mostafa Dehghani mentioned 'a sense of intelligence' in an interview.
He shared an intriguing example: when instructing the model to perform a task, it didn't follow his instructions verbatim.
Yet, the final output surpassed his description, leaving him pleasantly surprised.
Evidently, Nano Banana transcends being a mere 'command-executing tool.'
It possesses real-world knowledge and common sense, enabling it to refine and optimize vague or incorrect user instructions in specific contexts.
This 'intelligence' has dual implications—it may fail to meet user expectations but could also generate images that better align with users' latent needs or even exhibit greater creativity.
For most users, this 'intelligence' significantly enhances the experience, as 'creativity' remains elusive.
02 Commercialization Prospects: Breakeven in Text-to-Image Generation on the Horizon
The commercialization of any advanced technology hinges on cost-effectiveness.
Nano Banana's image applications naturally involve costs and potential profit models.
Robert Riachi explicitly stated in an interview that 'iterative training' for multimodal data (images, videos, etc.) is exceptionally challenging.
It requires extensive human preference signals, demanding substantial time and resource investments.
Machine learning necessitates an indicator to evaluate training effectiveness.
Traditional metrics often took hours to provide meaningful feedback, prompting Google's research team to relentlessly pursue more efficient training indicators.
Moreover, the extreme subjectivity of images makes collecting and processing user feedback equally time-consuming and costly.
Kaushik Shivakumar emphasized the cost-benefit issues of 'human scoring' in image generation evaluation.
As previously introduced in our AI Arena article, LMarena employs this 'human scoring' method.
The 'Votes' displayed in the rankings come from user submissions on the website.
Even for the highly capable Nano Banana, the current vote count hovers around 220,000.
Thus, while having sufficient users rate image quality provides valuable signals, the associated costs are likely prohibitive for Google.
This path being unviable necessitates seeking more efficient and economical evaluation metrics—namely, the 'text rendering metric' currently used by Nano Banana, which we'll explore later.
Beyond training costs, inference costs after model deployment must also be considered.
Currently, Nano Banana's API pricing is as follows:
Text Input: $0.30/M tokens
Text Output: $2.50/M tokens
Image Input: $0.30/image
Image Output: $0.039/image
It's freely available on Google AI Studio, though recent free usage limits have been imposed.
With such low pricing and high-quality generation, Nano Banana offers exceptional cost-performance.
Meanwhile, third-party platforms have emerged online this week, offering Nano Banana's API services at even lower prices.
Given the rapid iteration pace in the AI field, other vendors will likely release similarly capable models soon.
Relying solely on Nano Banana's usage fees would barely cover Google's substantial investments in this advanced model.
Thus, this model, redefining the AI image landscape, primarily aims to compete for market share and ecosystem dominance.
As AIGC remains a focal point in the tech giant rivalry, Google must continuously launch competitive products to counter OpenAI, Midjourney, and others.
The existence of Nano Banana and Gemini 2.5 Pro, both highly rated by users, effectively maintains Google's leadership in AI.
From a technical standpoint, model iteration and optimization constitute an ongoing process.
Affordable pricing attracts vast amounts of real user data, which all vendors desperately need.
Tech companies like Google primarily profit through services offered on their platforms.
Even if Nano Banana operates at a loss currently, its low-cost image generation and editing capabilities can draw users into Google's ecosystem, encouraging them to utilize related Google services. In the future, it could even become a core component of more lucrative businesses.
03 Technical Logic: A Cross-Era Powerhouse
Nano Banana's formidable capabilities in AI image editing stem from Google's long-term investments and efforts in multimodal learning, user feedback mechanisms, and innovative architectural design.
After watching Google's official 30-minute interview, one cannot help but marvel at its technical prowess.
① Text Rendering Metric
This metric, championed by Kaushik Shivakumar, initially seemed an unlikely key to success.
As mentioned earlier, Google's team needed an indicator independent of subjective user evaluations to determine if the model was improving.
Before Nano Banana's official release, multimodal models, both domestic and international, varied widely in image generation quality.
However, none could accurately incorporate text into images.
While text generation appears to be a niche within AI image editing, Google's team persisted in optimizing it as a goal.
The final results proved this decision incredibly correct.
During continuous text rendering optimization, the research team observed steady improvements in overall image generation quality.
A genius idea, coupled with relentless effort, forged Nano Banana's power.
② Multimodal Unified Model and Positive Transfer
Mostafa Dehghani proposed one of Nano Banana's core principles: achieving native image generation alongside multimodal understanding and generation.
This means the model learns all modalities and capabilities within a single training run, with the ultimate goal of enabling positive transfer across different dimensions.
Simply put, the model should not only understand and generate single modalities (e.g., text or images) but also leverage knowledge acquired from one modality to enhance understanding and generation of another.
For instance, the model can learn real-world knowledge from images, audio, and video to better comprehend and generate text.
As Robert Riachi mentioned, consider the phenomenon of 'reporting bias':
In daily conversations, people rarely mention obvious, mundane objects, like a friend's ordinary sofa.
Yet, when shown a room image, the sofa becomes immediately apparent.
Admittedly, this example seems somewhat perplexing, but it holds merit:
Visual signals like images and videos contain abundant implicit information about the real world, accessible without explicit requests.
For a multimodal model, visual signals offer a rare 'shortcut' to understanding the world.
This unified multimodal learning approach helps Google's team construct a more comprehensive and profound 'world model.'
The Gemini series of products have also demonstrated a higher degree of intelligence in various modal tasks, as validated by data from LMarena.
Therefore, the interview mentions that image understanding and image generation are seen as 'sisters,' mutually promoting each other in interleaved generation.
③ Learning from Mistakes: User Feedback-Driven 'Climbing Training'
Robert Riachi emphasized the importance of utilizing human preferences for 'climbing training.'
However, as previously mentioned, it is impossible to have humans judge the superiority or inferiority of every image generated by the model.
Therefore, the Google team collected a large amount of real user feedback from platforms like Twitter, transforming failed cases into evaluation benchmarks, which are precisely valuable signals for improving the model.
When the model's version 2.0 was released, team members keenly noticed a common failure case:
example:
Inability to maintain consistency in the rest of the image during editing.
Based on this, the team began 'climbing training' and iteration for specific issues.
This user-centered, mistake-learning mechanism is precisely the key to Nano Banana's ability to address this challenge.
④ Team Collaboration: The Fusion of Gemini and Imagen
At the end of the interview, Robert Riachi also mentioned that the success of Nano Banana is inseparable from the close collaboration between the Gemini and Imagen teams.
The Gemini team focuses on aspects such as instruction following and world knowledge, ensuring that the model can understand user intentions and generate logical content.
The Imagen team focuses on the visual quality of images, ensuring that the generated images are natural, aesthetically pleasing, and free from obvious issues.
The long-standing dominance of Gemini 2.5 Pro in rankings has already demonstrated its powerful functionality. By fusing the perspectives and expertise of both teams, Nano Banana achieves a balance between 'intelligence' and 'aesthetics' in images.
After Nano Banana's launch on Google AI Studio, we can also observe that it is seamlessly integrated with Gemini 2.5 Pro, directly usable within the original chat interface rather than as two separate models.
This deep cross-team collaboration has elevated Google's product ecosystem to a new level.
04 Conclusion
As many headlines have stated, the emergence of Nano Banana has undoubtedly brought revolutionary changes to the AI image field.
From pixel-perfect editing to complex interleaved image construction;
From intelligent understanding of user intentions to creative divergence beyond expectations;
The creative potential of artificial intelligence in visual arts is being gradually uncovered.
However, at the same time, high-quality, realistic images are also changing the status quo of many industries.
Although images generated by Nano Banana are now clearly marked as AI-generated, its works are already sufficient to meet the needs of most people.
What path should future creators and artists take?
The only certainty is that the future of the AI image field will be more intelligent, efficient, and creative.
Collaboration between humans and machines is about to begin writing a new chapter, reshaping the global software industry as a result.
-
Confirmed: Fossil Fuel Vehicle Ban! Hainan Unveils New '15th Five-Year Plan', Weakening Passenger Vehicle Sector and Initiating Petroleum Asset Depreciation
-
![]()
Research on the Underlying Industrial Logic of the Booming Sales of Chinese Action Camera Brands in Japan and the Decline of GoPro: The UGC+AIGC Creation Wave Reshapes the Market Landscape
-
![]()
Half-Year In-App Purchases Reach 105 Billion: The Most Lavish Starting Point and the Most Challenging Second Half
-
![]()
AI Enters Its Next Phase: From DeepSeek to Robots, What Lies Ahead for AI?
-
![]()
Jieyue Paves the Way for Agents with a New Phone and AgentOS
-
![]()
Research on the Industrial Logic Behind the Surge of Chinese Action Camera Brands in Japan and GoPro's Decline: How the UGC+AIGC Creative Wave is Reshaping the Market
-
![]()
Has Doubao Started Charging? Does ByteDance Face Commercialization Pressure?
-
![]()
Doubao Starts Charging: Does ByteDance Face Commercialization Pressure?




