Theme Consistency Surpasses All Open-Source and Commercial Models! USTC & ByteDance Open-Source Unified Innovation Framework BindWeave
 11/11 2025
11/11 2025
 541
541
Interpretation: The Future of AI-Generated Content
Key Highlights
BindWeave: Addresses the bottleneck of theme consistency in existing video generation techniques by proposing a novel framework tailored for theme-consistent video generation.
Introduces a multimodal large language model as a deep instruction parser. Replaces traditional shallow fusion mechanisms with MLLM, enabling deep cross-modal semantic associations.
Constructs a unified interwoven sequence and latent state generation mechanism. Integrates reference images and text prompts into a unified sequence, effectively bridging high-level semantic parsing with diffusion generation processes.
Multimodal condition fusion mechanism. Forms a synergistic conditional mechanism combining high-level reasoning, semantic identity, and low-level details to comprehensively enhance generation quality.
On OpenS2V, achieves comprehensive evaluation across theme consistency, temporal naturalness, and text-video alignment; consistently surpasses all existing open-source and commercial models in theme-consistent video generation tasks, reaching SOTA performance.
Demonstrates broad potential for research and commercial applications.
Summary Overview
Performance Overview
Single Person:

Multiple Persons:

Person + Object:
Problems Addressed
1. Core Bottleneck: Existing video generation models struggle to parse and understand complex spatial relationships, temporal logic, and multi-agent interactions in prompts.
2. Specific Deficiencies: Result in inadequate theme consistency in generated videos, failing to stably and accurately maintain specific agents' identities, attributes, and mutual relationships throughout the video.
Proposed Solution
Core Framework: Introduces a unified innovation framework named BindWeave.
Core Idea: Utilizes a multimodal large language model (MLLM) as an intelligent instruction parser, replacing traditional shallow fusion mechanisms to achieve deep semantic understanding and cross-modal associations of prompts.
Implementation Path:
Constructs Unified Sequences: Integrates reference images and text prompts into interwoven sequence inputs for MLLM.
Deep Parsing and Binding: Leverages MLLM to parse complex spatiotemporal relationships, anchors textual instructions to specific visual entities, and generates 'theme-aware latent states' encoding agent identities and interaction relationships.
Multi-Condition Synergistic Generation: Uses the aforementioned latent states alongside CLIP features of reference images (reinforcing semantic anchoring) and VAE features (preserving details) as conditions, input into a diffusion Transformer (DiT)-based generator to guide video generation.
Applied Technologies
Multimodal Large Language Model (MLLM): Serves as the core deep cross-modal reasoning engine.
Diffusion Transformer (DiT): Functions as the foundational video generation backbone model.
Multi-Source Condition Fusion Mechanism: Innovatively integrates three types of conditional signals:
Latent states output by MLLM (providing high-level reasoning and interaction relationships).
CLIP image features (providing semantic-level identity anchoring).
VAE image features (providing pixel-level appearance details).
Benchmark Dataset: Evaluated on the fine-grained OpenS2V benchmark.
Achieved Results
Superior Performance: On the OpenS2V benchmark, achieves outstanding performance across key metrics including theme consistency, temporal naturalness, and text-video alignment.
Industry-Leading: Comprehensively surpasses existing mainstream open-source methods and commercial models, reaching state-of-the-art performance levels.
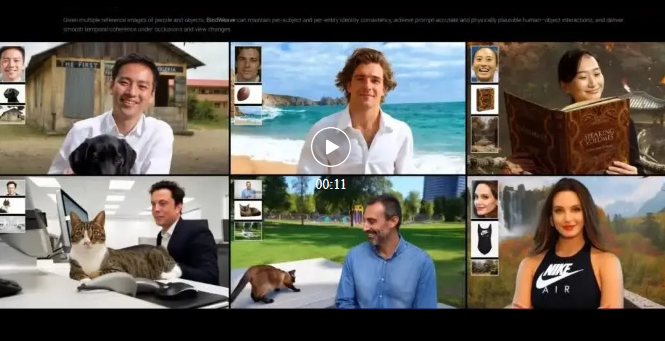
Exceptional Quality: Qualitative results (illustrated) demonstrate that generated video samples exhibit extremely high fidelity and theme consistency.
Application Potential: Shows immense potential for research and commercial applications in video generation.
Methodology
Architectural Design
The proposed BindWeave aims to overcome the limitations of shallow fusion paradigms in theme-consistent video generation. Its core principle involves replacing shallow post-hoc fusion with deep reasoning to understand multimodal inputs before the generation process begins. To achieve this, BindWeave first employs a multimodal large language model as an intelligent instruction parser. This MLLM guides the synthesis process throughout by generating latent state sequences encoding complex cross-modal semantics and spatiotemporal logic. Figure 2 below illustrates the BindWeave architecture.
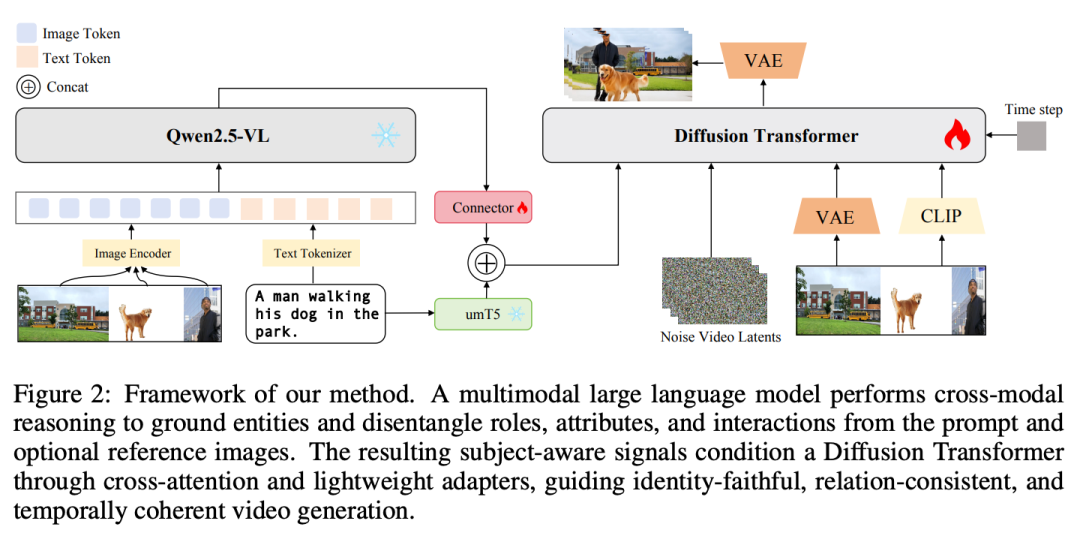
MLLM-Based Intelligent Instruction Planning
To effectively facilitate cross-modal joint learning between text prompts and reference images, this paper introduces a unified multimodal parsing strategy. Given text prompts and N user-specified agents (each corresponding to a reference image), we construct multimodal sequences by appending image placeholders after each text prompt. Subsequently, we provide the MLLM with this sequence and the corresponding image list:
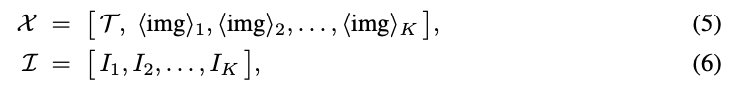
Here, img_k represents a special placeholder token internally aligned by MLLM with the k-th image. This unified representation preserves critical contextual links between textual descriptions and their corresponding visual agents, which is then input into the pre-trained MLLM. By processing multimodal inputs, the MLLM generates latent state sequences embodying high-level scene reasoning, effectively binding textual instructions to their specific visual identities:

To align the feature spaces of the frozen MLLM and diffusion model, these latent states are projected through a trainable lightweight connector, generating feature-aligned conditions:

While this MLLM-derived condition provides valuable high-level cross-modal reasoning information, we recognize that diffusion models are also highly optimized for parsing fine-grained text semantics. To provide this complementary signal, we independently encode the original prompts using a T5 text encoder to generate dedicated text embeddings:  We then concatenate these two complementary streams to form the final relational conditional signal:
We then concatenate these two complementary streams to form the final relational conditional signal:
 This composite signal encapsulates not only explicit textual instructions but also deep reasoning about agent interactions and spatiotemporal logic, laying a solid foundation for subsequent generation stages.
This composite signal encapsulates not only explicit textual instructions but also deep reasoning about agent interactions and spatiotemporal logic, laying a solid foundation for subsequent generation stages.
Collective Conditionalization for Video Diffusion
During the instruction planning process, we integrate useful semantic information into [latent representations]. Now, we need to inject these as conditions into the DiT module to guide video generation. Our generative backbone operates in the latent space of a pre-trained spatiotemporal variational autoencoder. To ensure high-fidelity and consistent video generation, we employ a collective conditionalization mechanism to synergistically integrate multi-channel information. As previously mentioned, our collective conditionalization mechanism operates at two collaborative levels: conditionalizing spatiotemporal inputs and cross-attention mechanisms.
To preserve fine-grained appearance details from reference images, we design an adaptive multi-reference conditionalization strategy (illustrated in Figure 3 below).
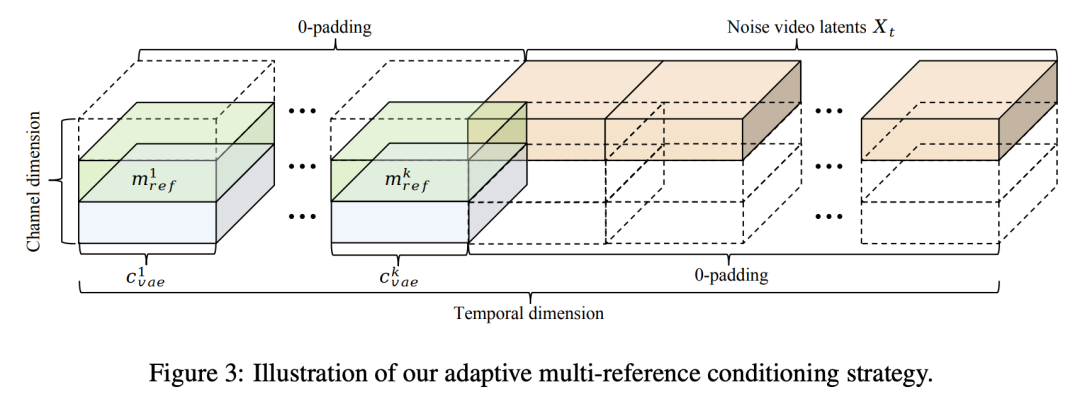
Specifically, we encode reference images into low-level VAE features, denoted as [VAE features]. Since theme video generation differs from image-to-video generation, reference images are not treated as actual video frames. We first extend the temporal dimension of noisy video latent representations, padding with zeros for N additional positions: [padded representation]. Subsequently, we place the VAE features of reference images at these padded temporal positions (with zeros elsewhere) and concatenate corresponding binary masks along the channel dimension to emphasize agent regions. After channel-wise concatenation followed by block embedding, we obtain the final input for the DiT module:
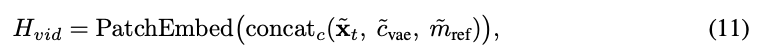
Here, [masks] and [VAE features] are zero outside the N padded time slots and carry reference conditions only within these slots. This design maintains the original video's temporal integrity while injecting fine-grained appearance and agent enhancement information through channel-level conditionalization.
Subsequently, high-level semantic guidance is injected through cross-attention layers. This involves two distinct signals: relational conditions from MLLM for scene composition, and CLIP image features for agent identity. Within each DiT block, evolved video tokens generate query vectors. Conditional signals [MLLM conditions] and [CLIP features] are projected to form their respective key-value matrices. The attention layer's final output is the summation of these information flows, extending Equation 4: 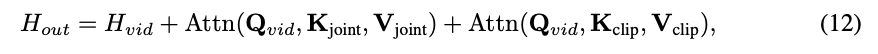 Here, [projected keys] and [projected values] are derived through linear projection layers from [MLLM conditions] and [CLIP features], respectively. By integrating high-level relational reasoning, semantic identity guidance, and low-level appearance details in this structured manner, BindWeave effectively guides the diffusion process to generate videos that are not only visually faithful to agents but also logically and semantically consistent with complex user instructions.
Here, [projected keys] and [projected values] are derived through linear projection layers from [MLLM conditions] and [CLIP features], respectively. By integrating high-level relational reasoning, semantic identity guidance, and low-level appearance details in this structured manner, BindWeave effectively guides the diffusion process to generate videos that are not only visually faithful to agents but also logically and semantically consistent with complex user instructions.
Training and Inference
Training Setup: Following the corrected flow formulation described earlier, our model is trained to predict real velocity fields. BindWeave's overall training objective can be expressed as the mean squared error between model outputs and ground truth:
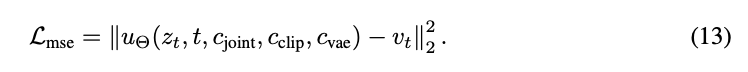 Our training data is selected from the publicly available 5M-scale OpenS2V-5M dataset. Through a series of filtering strategies, we ultimately refine approximately 1 million high-quality video-text pairs. Subsequently, we adopt a two-stage curriculum learning strategy for training. All training processes are conducted on 512 xPUs with a global batch size of 512, using a constant learning rate of 5e-6 and the AdamW optimizer. The initial stabilization phase lasts approximately 1,000 iterations, utilizing a carefully curated, high-quality representative subset from the 1 million data points. This phase is crucial for adapting the model to the specific demands of theme-to-video tasks, primarily focusing on aligning agent visual identities with textual motion instructions while maintaining authenticity, thereby laying a solid foundation for subsequent large-scale training. Training then transitions to a comprehensive phase lasting 5,000 iterations, where the model is exposed to the entire 1 million curated dataset. This second phase enables the model to further expand on a stable foundation, significantly enhancing generation capabilities and generalization performance through learning from a broader range of high-quality samples.
Our training data is selected from the publicly available 5M-scale OpenS2V-5M dataset. Through a series of filtering strategies, we ultimately refine approximately 1 million high-quality video-text pairs. Subsequently, we adopt a two-stage curriculum learning strategy for training. All training processes are conducted on 512 xPUs with a global batch size of 512, using a constant learning rate of 5e-6 and the AdamW optimizer. The initial stabilization phase lasts approximately 1,000 iterations, utilizing a carefully curated, high-quality representative subset from the 1 million data points. This phase is crucial for adapting the model to the specific demands of theme-to-video tasks, primarily focusing on aligning agent visual identities with textual motion instructions while maintaining authenticity, thereby laying a solid foundation for subsequent large-scale training. Training then transitions to a comprehensive phase lasting 5,000 iterations, where the model is exposed to the entire 1 million curated dataset. This second phase enables the model to further expand on a stable foundation, significantly enhancing generation capabilities and generalization performance through learning from a broader range of high-quality samples.
Inference Setup: During inference, our BindWeave can accept a flexible number of reference images (typically 1-4), while guiding generation through text prompts describing target scenes and behaviors. Similar to the Phantom method, we employ a prompt rewriter during inference to ensure text accurately describes the provided reference images. The generation process employs 50-step sampling using the corrected flow trajectory and is guided by classifier-free guidance with a scale factor of [guidance scale]. The guidance noise estimate at each step is calculated as follows:
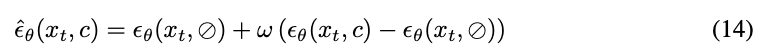
Here, [conditional noise] represents the noise prediction based on the prompt, while [unconditional noise] denotes the unconditional prediction. This estimate is subsequently used by the scheduler to derive [next step parameters].
Experiments
Experimental Setup
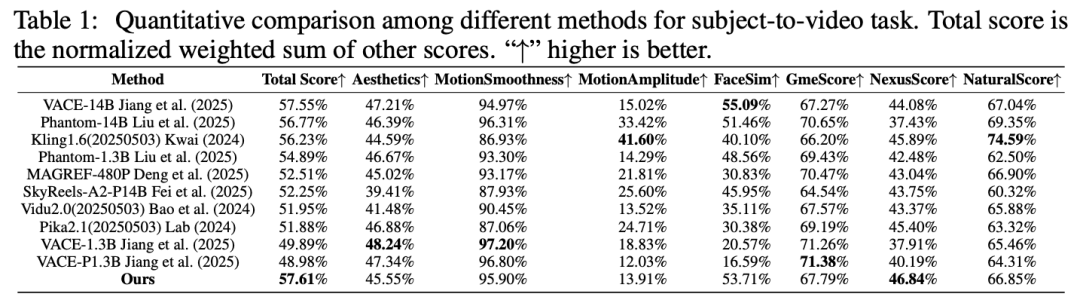
Benchmarks and Evaluation Metrics: To ensure fair comparison, we adopt the OpenS2V-Eval benchmark and follow its official evaluation protocol, which provides fine-grained assessment of subject consistency and identity fidelity for subject-to-video generation. The benchmark includes 180 prompts across seven distinct categories, covering scenarios from single-subject to multi-subject and human-object interactions. To quantify performance, we report the protocol's automated metrics, where higher scores indicate better results across all metrics. These include Aesthetic Score for visual appeal, Motion Smoothness for temporal continuity, Motion Magnitude for movement intensity, and Facial Similarity for identity preservation. We also utilize three human perception-aligned metrics introduced by OpenS2V-Eval: NexusScore for subject consistency, NaturalScore for naturalness, and GmeScore for text-video relevance.
Implementation Details: BindWeave fine-tunes a base video generation model built on the DiT architecture. Our evaluation excludes text-to-video and image-to-video pre-training stages. For the core instruction planning module, we employ Qwen2.5-VL-7B as the multimodal large language model. To align multimodal control signals with the DiT conditioning space, we introduce a lightweight connector that projects Qwen2.5-VL's hidden states. Specifically, the connector adopts a two-layer MLP structure with GELU activation. We train the model using the Adam optimizer with a learning rate of 5e-6 and a global batch size of 512. To mitigate copy-paste artifacts, we apply data augmentation techniques to reference images. During inference, we use 50 denoising steps and set the classifier-free guidance scale to 5.
Baseline Methods: We compare BindWeave against state-of-the-art video customization approaches, including open-source methods and commercial products.
Quantitative Results
We conduct a comprehensive comparison on the OpenS2V-Eval benchmark, as shown in Table 1 below, providing extensive and rigorous evaluation across diverse scenarios. Following the benchmark protocol, each method generates 180 videos for assessment to ensure statistical reliability and cover all categories. We report eight automated metrics described earlier to ensure holistic evaluation, uniformly capturing visual quality, temporal behavior, and semantic alignment. As shown in Table 1, BindWeave achieves a new SOTA in overall score, with a significant lead in NexusScore, highlighting its advantage in subject consistency. Notably, NexusScore addresses limitations of prior global frame CLIP or DINO comparisons by providing semantically grounded and noise-resistant evaluation that better reflects perceptual identity fidelity. It achieves this through a detect-then-compare strategy: first localizing true subjects, cropping relevant regions to suppress background interference, then computing similarity in a retrieval-based multimodal feature space, and finally aggregating scores from verified cropped regions for reliable summarization. Importantly, BindWeave maintains strong competitiveness across other metrics, including Facial Similarity, Aesthetic Score, GmeScore, motion-related metrics, and Naturalness, reflecting its advantages in identity preservation, visual appeal, text-video alignment, temporal coherence and motion magnitude, and overall naturalness across broad prompts and categories.
Qualitative Results
To clearly demonstrate our method's effectiveness, we present typical subject-to-video scenarios in Figures 4 and 5 below, including single human-to-video, human-object-to-video, single object-to-video, and multi-entity-to-video. As shown in the left panel of Figure 4, commercial models like Vidu, Pika, Kling, and Hailuo generate visually appealing videos but struggle with subject consistency. Among open-source methods, SkyReel-A2 shows relative competitiveness in subject consistency but lags in overall visual aesthetics compared to our BindWeave. VACE and Phantom similarly exhibit weak subject consistency. In the right panel of Figure 4, our method achieves significantly better subject consistency, text alignment, and visual quality. As shown in the left panel of Figure 5, in single object-to-video scenarios, commercial models like Vidu and Pika still demonstrate clear violations of physical and semantic plausibility - which we summarize as 'common sense violations'. Kling achieves strong visual aesthetics but poor subject consistency. SkyReels-A2 shows severe distortions and equally weak subject consistency, while Phantom also struggles to maintain subject consistency. Among baseline methods, VACE better preserves subject consistency but has limited motion coherence and naturalness. In contrast, our BindWeave provides strong subject consistency while achieving naturally coherent motion. Notably, under multi-object and complex instruction settings shown in the right panel of Figure 5, methods like Vidu and Pika frequently omit key prompts, Kling exhibits severe physical implausibility, MAGREF fails to maintain subject consistency, and other baselines also ignore critical prompt details. In contrast, our results preserve strong subject consistency while presenting fine-grained details. We attribute this to BindWeave's cross-modal capability of explicitly integrating reference images and text prompts through MLLM, enabling joint parsing of entities, attributes, and inter-object relationships. Consequently, BindWeave retains subtle yet critical details and constructs unified, temporally consistent scene planning to guide coherent generation. This deep cross-modal integration reliably reinforces key prompt elements and embeds basic physical common sense for multi-entity interactions, thereby reducing implausible outcomes.


Ablation Study
We conduct ablation experiments on the control conditioning mechanism that combines MLLM with T5-derived signals to guide DiT generation. We compare a baseline scheme using T5 alone against our T5+Qwen2.5-VL combination. Notably, the MLLM-only scheme proved unstable during training and failed to converge, thus excluded from quantitative analysis. As shown in Table 2 below, the T5+Qwen2.5-VL combination consistently outperforms the T5-only scheme in aesthetic quality, motion performance, naturalness, and text relevance. The qualitative comparison in Figure 6 further validates this finding: when scale mismatch exists in reference images, the T5-only baseline tends to generate unrealistic subject sizes and frequently misparses action-object relationships under complex instructions, whereas the T5+Qwen2.5-VL combination maintains accurate grounding and executes intended interactions. We attribute these improvements to the complementary conditioning mechanism - MLLM provides multimodal identity and relationship-aware cues to disambiguate subjects and enhance temporal coherence, while T5 offers precise linguistic grounding to stabilize the optimization process. Their concatenation produces richer and more reliable control signals for DiT.


Conclusion
BindWeave - a novel framework for subject-consistent video generation that produces coherent, text-aligned, and visually appealing videos in both single-subject and multi-subject scenarios through explicit cross-modal integration techniques. By deeply fusing reference image and text prompt information via MLLM to facilitate joint learning, BindWeave effectively models entity identities, attributes, and relationships, enabling fine-grained grounding and robust subject preservation. Empirical results demonstrate that BindWeave has fully mastered cross-modal fusion knowledge, capable of generating high-fidelity subject-consistent videos. On the OpenS2V benchmark, BindWeave achieves state-of-the-art performance, surpassing existing open-source solutions and commercial models, and fully demonstrating its technical advantages. Overall, BindWeave provides a fresh perspective for subject video generation tasks and points the way for future breakthroughs in consistency, realism, and controllability.
References
[1] BINDWEAVE: SUBJECT-CONSISTENT VIDEO GENERATION VIA CROSS-MODAL INTEGRATION
-
![]()
Hunan’s Wealthiest Entrepreneur Eyes Comeback with Apple’s Foldable iPhone
-
![]()
Planning to Secure 1.055 Billion Yuan to Propel AR Optics Forward! Lante Optics Receives Green Light for Private Placement on the Science and Technology Innovation Board
-
![]()
MiniMax: At the Heart of the AI Maelstrom
-
![]()
Securing 600 Million Yuan in Funding: This AR Optics Company Steps into the Limelight!
-
![]()
From a 706% Surge to a $340 Billion Market Cap Plummet: Has MiniMax's Moment Passed?
-
![]()
High Demand, Low Stock Price: Can the Emotional Companion Robot Ease UBTECH’s Worries?
-
![]()
Why Does Yin Qi, Who 'Doesn't Listen to Advice,' Insist on Making AI Agent Smartphones? | Interview with Jieyue Xingchen
-
![]()
AI-Generated Code Reveals Surprise That Thrills China