One Article to Explain 'Point Cloud' in Autonomous Driving
 11/11 2025
11/11 2025
 688
688
When the topic of autonomous driving perception systems arises, a term that frequently surfaces is 'point cloud.' Acting as a conduit between the physical and digital worlds, it endows machines with depth perception capabilities that surpass those of human vision. This enables vehicles to precisely 'comprehend' their position within the environment and the true shapes of surrounding objects. Today, Smart Driving Frontier invites you on an in-depth exploration of the significance of 'point cloud.'
What is a Point Cloud?
In simple terms, a point cloud is a digital record of the position of each point in three-dimensional space. Each point in spatial coordinates can be represented by three coordinate values: x, y, and z. Some points may also carry additional information, such as reflection intensity or timestamps. When all the points in a scene are aggregated, they form a point cloud.
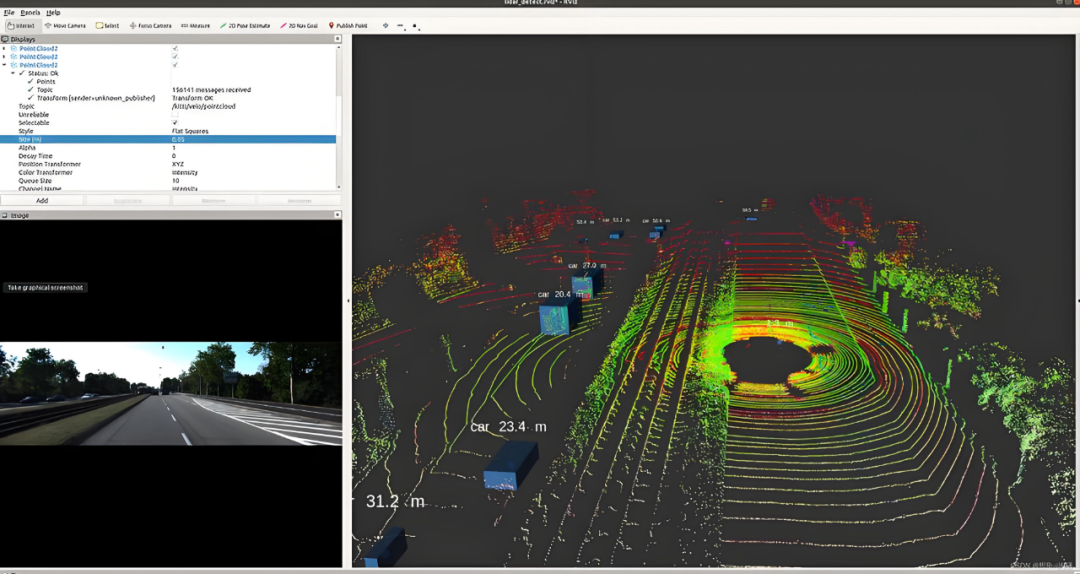
LiDAR Point Cloud Image (Right), Image Source: Internet
As depicted in the image above, this is a point cloud generated by LiDAR, showcasing the outlines of streets, intersections, and vehicles 'sketched' by countless tiny points. These points can reconstruct the shapes, distances, and spatial relationships of objects, providing autonomous vehicles with a wealth of traffic information. Unlike the pixel grid of photographs, point clouds consist of sparse or dense collections of independent points distributed in three-dimensional space. They directly express three-dimensional structures and offer a more intuitive reflection of the actual positions of objects in space compared to two-dimensional images.
Which Sensors Generate Point Clouds?
In the realm of autonomous driving, multiple sensors are capable of generating point cloud data. LiDAR, as the most pivotal acquisition device, calculates distances by emitting laser beams and precisely measuring their return times. Coupled with sophisticated scanning control, it can generate dense point clouds in real time, rich in three-dimensional coordinate and reflection intensity information.

LiDAR, Image Source: Internet
Stereovision systems emulate the principle of human binocular disparity, utilizing multiple cameras to capture the same scene from different angles and calculating pixel position differences to infer depth. Ultimately, they convert two-dimensional images into three-dimensional point clouds. This method excels in textured areas but experiences a significant decline in accuracy in flat regions or long-distance scenes with missing features.
Time-of-flight depth cameras calculate depth values for each pixel by directly measuring the round-trip time of light pulses, swiftly generating point clouds as well. However, their effective sensing range is relatively short, making them primarily suitable for near-field environmental perception.
Millimeter-wave radar detects targets by analyzing radio wave reflections, providing distance, speed, and angle information. Although the generated data points are sparse and the angular resolution is limited, it performs stably in adverse weather conditions and is often employed as a special 'sparse point cloud' for target tracking and fused perception.
Due to their varying working principles, the point clouds generated by these sensors differ significantly in terms of density, noise levels, and information dimensions. This directly impacts their specific application scenarios within the system and subsequent data processing strategies.
What Can Point Clouds Do?
Given that numerous sensors can generate point clouds, what exactly can they accomplish for autonomous driving? For autonomous vehicles, the primary function of point clouds is three-dimensional perception. Compared to two-dimensional images, point clouds can directly provide the distance, height, and approximate shape of objects. This is crucial for judging obstacles, identifying curbs, detecting pedestrians, and vehicle postures. Point clouds are frequently utilized for object detection and tracking, with algorithms directly outputting three-dimensional bounding boxes in three-dimensional space. This enables more precise estimation of distances and sizes, thereby enhancing the reliability of localization and obstacle avoidance decisions.
Another vital role of point clouds is mapping and localization. By aligning consecutive frames of point clouds (i.e., point cloud registration), vehicles can achieve point cloud-based localization when high-definition maps are unavailable or GPS signals are disrupted (e.g., through scan matching or feature-based localization). This serves as a redundant localization scheme for many autonomous driving systems.

Image Source: Internet
Point clouds also offer autonomous driving systems a profound understanding of the environment. By performing semantic segmentation on point clouds, the system can accurately distinguish key traffic elements such as roads, barriers, streetlights, and sidewalks. This not only achieves a structured understanding of the scene but also provides important semantic constraints for path planning, ensuring that vehicle behavior complies with traffic rules and scene characteristics.
Furthermore, point clouds supply reliable three-dimensional geometric information for the planning and control modules. Compared to schemes relying on two-dimensional projections, point clouds directly present spatial elevation changes and geometric features, enabling vehicles to accurately perceive critical parameters such as slopes and curb heights. With these data, path planning can fully consider actual terrain factors, significantly improving the accuracy and safety of decision-making.

Common Processing Workflows and Algorithmic Highlights for Point Clouds
Point cloud data is not immediately usable after generation. From raw point clouds to usable three-dimensional perception results, a series of processing steps are necessary. The initial step is preprocessing. During this stage, noise filtering is conducted first to eliminate abnormal data points caused by dust, rain, fog, or sensor errors in the air, ensuring the purity of the basic data. Subsequently, data reduction is implemented, reducing the total data volume while retaining the main geometric features of the scene through voxel downsampling methods to enhance subsequent processing efficiency. The final step in preprocessing is coordinate unification, converting point cloud data from different sensors into a unified vehicle or world coordinate system through time synchronization and coordinate transformations, laying the groundwork for subsequent advanced processing tasks such as obstacle detection and environmental perception.
Once preprocessing is complete, ground segmentation and ground plane fitting are performed to remove or mark the road surface, facilitating the separation of non-ground objects such as pedestrians and vehicles. After segmentation, clustering and candidate generation are carried out, extracting point sets of individual objects through Euclidean clustering or semantic-based segmentation, and then fitting three-dimensional bounding boxes for each cluster.
There are two prevalent approaches to processing point cloud data. One is the point-based method, exemplified by PointNet/PointNet++, which directly performs feature learning on raw point cloud data, fully retaining the three-dimensional coordinate information of each point. The other is converting irregular point clouds into structured representations such as regular voxel grids or bird's-eye views, and then utilizing mature convolutional neural networks for feature extraction. These two schemes possess their own advantages; point-based methods offer higher accuracy, while grid-based methods boast better computational efficiency.
After obtaining detection results, the system needs to associate objects detected at different times through object tracking techniques to form continuous motion trajectories. This process can employ algorithms such as Kalman filtering, predicting and updating target positions by establishing motion models. Meanwhile, to fuse point cloud data from multiple frames or different sensors, point cloud registration operations are required. Common registration methods include the Iterative Closest Point algorithm and feature-based matching methods, which effectively solve the spatial alignment problem between point clouds.
Limitations and Challenges of Point Clouds
Although point clouds can provide direct three-dimensional information, they also come with certain limitations. Point cloud density rapidly diminishes with distance, angle, and sensor resolution, resulting in sparse point clouds in distant and low-reflectivity areas, which degrades the performance of detecting small distant targets.

Image Source: Internet
For instance, in abnormal weather conditions such as rain, snow, fog, and dust, false echoes or laser absorption can occur, reducing the effective number of points from LiDAR. Similarly, the depth estimation performance of stereovision also deteriorates under low light or reflective surfaces. The reflectivity of different materials to lasers also varies greatly, with some dark or light-absorbing materials producing almost no echoes.
Additionally, point cloud data is voluminous and computationally intensive, necessitating efficient algorithms and dedicated hardware acceleration (such as GPUs and sparse convolution accelerators) for real-time processing. Labeling point clouds is also more time-consuming and labor-intensive than labeling images, requiring more complex three-dimensional labeling tools and consistency requirements, which affects the scale of training data.
If there are errors in time synchronization and spatial calibration between different sensors, it will directly lead to systematic deviations in point cloud data during fusion. In the time dimension, even a millisecond-level time difference can cause the spatial positions of the same target in different sensors to not correspond precisely due to the rapid motion of vehicles and objects. In the spatial dimension, small angular errors in extrinsic calibration will amplify with distance, causing data from different sensors such as LiDAR and cameras to not align seamlessly in space.
Final Thoughts
The role of point clouds is to provide autonomous driving systems with direct geometric information in three-dimensional space, enabling vehicles to perceive distances, shapes, and spatial relationships. This serves as an indispensable perception foundation for autonomous driving. However, point clouds have limitations such as sparsity, weather sensitivity, and dependence on material reflectivity. Therefore, to achieve better perception performance in autonomous driving systems, it is not sufficient to rely solely on point clouds. Instead, they should be combined with sensor information from cameras and radars, leveraging appropriate representations and efficient algorithms to fully exploit the advantages of point clouds while compensating for their shortcomings with other sensors.
-- END --
-
![]()
Hunan’s Wealthiest Entrepreneur Eyes Comeback with Apple’s Foldable iPhone
-
![]()
Planning to Secure 1.055 Billion Yuan to Propel AR Optics Forward! Lante Optics Receives Green Light for Private Placement on the Science and Technology Innovation Board
-
![]()
MiniMax: At the Heart of the AI Maelstrom
-
![]()
Securing 600 Million Yuan in Funding: This AR Optics Company Steps into the Limelight!
-
![]()
From a 706% Surge to a $340 Billion Market Cap Plummet: Has MiniMax's Moment Passed?
-
![]()
High Demand, Low Stock Price: Can the Emotional Companion Robot Ease UBTECH’s Worries?
-
![]()
Why Does Yin Qi, Who 'Doesn't Listen to Advice,' Insist on Making AI Agent Smartphones? | Interview with Jieyue Xingchen
-
![]()
AI-Generated Code Reveals Surprise That Thrills China