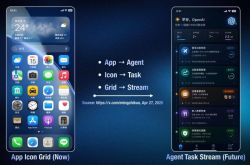
How Does the Transformer Architecture Elevate the Intelligence of Autonomous Driving?
 11/17 2025
11/17 2025
 608
608
The Transformer, a term frequently encountered in the realm of autonomous driving, represents a neural network architecture that initially rose to prominence within the field of natural language processing. Distinct from Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs), the Transformer possesses the unique ability to automatically scrutinize all input data and dynamically ascertain which segments hold greater significance. Moreover, it can adeptly establish connections between these crucial pieces of information.
This capability is of paramount importance in autonomous driving. Given the intricate and constantly evolving nature of driving scenarios, autonomous driving systems are tasked with simultaneously processing data from a multitude of sources. These sources encompass cameras, millimeter-wave radars, LiDAR, and high-definition maps. Furthermore, the systems must comprehend the dynamic interactions unfolding among vehicles, pedestrians, and other road users over time. Traditional methods often struggle to effectively manage such multi-modal and long-term sequential information associations. In contrast, the architectural attributes of the Transformer precisely address these shortcomings.

Image Source: Internet
The Transformer has the capacity to amalgamate seemingly disparate fragments of information. For instance, it can integrate details such as "a blurry object 100 meters ahead," "a car in the adjacent lane slowing down," and "a pedestrian suddenly appearing at the intersection a few seconds ago" into a unified set of "input units." Subsequently, it automatically forges meaningful connections among these units, ultimately extracting the most valuable core information to inform current driving decisions. This formidable global association capability enables perception, prediction, and planning—modules that were traditionally distinct—to collaborate in a more integrated and intelligent manner.
Core Mechanisms of the Transformer: Self-Attention and Multi-Head Attention
The potency of the Transformer lies in its "self-attention" mechanism. Self-attention entails transforming each input element (for example, a patch of an image or a point from LiDAR) into three distinct vectors: Query, Key, and Value.
Query: This can be conceptualized as the current element posing the question, "To whom should I direct my attention?"
Key: This serves as the identifier provided by other elements, essentially stating, "Who am I?"
Value: This represents the actual information carried by other elements, declaring, "What do I possess?"
The query is then compared for similarity with all keys to obtain weights. These weights are subsequently applied to all values, resulting in a new representation for the current position. This process empowers the model to autonomously determine, "From which other positions' information should I draw to update my understanding of the current position?" To ensure the stability of the training process, attention calculations are adjusted using a scaling factor.
The Transformer does not limit itself to a single attention calculation. Instead, it employs "multi-head attention," which allows for multiple sets of independent attention operations to take place simultaneously. This is analogous to having multiple experts analyze the same information from diverse perspectives. Some experts may focus on local details, while others excel at discerning global relationships. Ultimately, they synthesize their insights to form a more comprehensive and profound understanding.

Image Source: Internet
For common time-series problems encountered in autonomous driving, the Transformer can effortlessly utilize data from several past frames as an input sequence. Through the attention mechanism, it can directly learn the dependencies between different moments. Supplemented by "positional encoding," which informs the model of the sequential order of input units, it can effectively predict the future trajectories of vehicles and pedestrians.
Advantages of the Transformer for Perception
In the past, the most prevalent approach in perception involved using convolutional networks for image feature extraction, followed by specialized detection heads (such as Faster R-CNN and YOLO) for object detection. The Transformer, however, reformulates the detection problem as "a set of queries matching objects in the scene." Methods like DETR and its subsequent variants have streamlined the process by reducing many manually designed steps, such as anchor boxes and Non-Maximum Suppression (NMS), offering a more straightforward and unified approach.
1) Enhanced Detection of Long-Range and Sparse Targets
Thanks to its global attention mechanism, the Transformer can simultaneously reference nearby large objects and the overall scene context when analyzing a distant small target. This capability proves particularly valuable when the target is partially obscured or the image resolution is limited. The model can infer "that might be a pedestrian" or "there is a parked vehicle in the distance" based on other relevant cues.
2) More Seamless Multimodal Fusion
Autonomous vehicles are equipped with a variety of sensors, including cameras, millimeter-wave radars, and LiDAR. The Transformer provides a unified framework to represent data from these different sources as "input units." Subsequently, it enables these units to freely exchange information through cross-modal attention mechanisms. For example, precise 3D point cloud information from LiDAR can complement the rich texture and color information from cameras. The model can autonomously learn when and how to rely on which sensor, achieving true early fusion.

Image Source: Internet
3) Simplified Integration of End-to-End Detection and Tracking
The Transformer can treat detection boxes, historical trajectories, and even ID information as tokens. This allows the model to perform detection and association simultaneously, reducing post-processing steps and lowering the probability of misassociation (ID-switch). Advances in Transformer for Multi-Object Tracking (MOT) can effectively address the challenge of maintaining object identities across consecutive frames in autonomous driving.
How the Transformer Enhances Decision-Making Insight
Predicting the future trajectories of other road participants and planning a safe path for the autonomous vehicle are core tasks in autonomous driving. To accomplish this, the model requires robust reasoning capabilities to comprehend the complex spatiotemporal interactions among participants. The self-attention mechanism of the Transformer once again showcases significant advantages in this regard.
1) Improved Modeling of Interactive Behaviors
Traditional methods often appear rigid when modeling multi-agent interactions. In contrast, the attention mechanism of the Transformer can inherently calculate the degree of influence between any two participants and dynamically focus attention on "key participants." For example, when navigating through an intersection without traffic lights, the Transformer can simultaneously consider the intentions of vehicles approaching from the left, pedestrians preparing to cross from the right, and vehicles ahead. It can then generate multiple reasonable future probability distributions to enable safe and efficient driving for the autonomous vehicle.
2) Greater Compatibility with Long-Term Memory
Predicting certain driving behaviors necessitates reviewing extensive historical information. For instance, to make a prediction, it may be required to look back at past states over a long period (e.g., a vehicle's turn signal has been on for several seconds, but it has been driving slowly and now finally starts to merge). The Transformer handles long sequences more robustly than traditional LSTMs and can perform parallel computations, leading to higher training efficiency. Of course, to process longer historical information, techniques such as sparse attention, local-global hybrid mechanisms, or caching mechanisms are needed to control the computational load.
Image Source: Internet
3) Planning Can Directly Leverage Predictive Attention
When both the prediction and planning modules are built on the Transformer architecture, the flow of information between them becomes smoother. The planning module can not only observe the trajectories output by the prediction module but also "perceive" the attention distribution during the prediction process, i.e., which other traffic participants are of greatest concern. This provides deeper context for the autonomous vehicle's decisions. For example, when passing through a crowded intersection, the autonomous vehicle can maintain a greater safety distance from a vehicle with highly dispersed attention and uncertain behavior.

Final Thoughts
The Transformer introduces a more powerful and flexible paradigm for "information association and understanding" in the field of autonomous driving. It empowers machines to examine complex driving environments more comprehensively, akin to human perception, and integrate information from diverse sources and timeframes. This, in turn, leads to more proactive and reasonable decisions.
-- END --
-
![]()
Hunan’s Wealthiest Entrepreneur Eyes Comeback with Apple’s Foldable iPhone
-
![]()
Planning to Secure 1.055 Billion Yuan to Propel AR Optics Forward! Lante Optics Receives Green Light for Private Placement on the Science and Technology Innovation Board
-
![]()
MiniMax: At the Heart of the AI Maelstrom
-
![]()
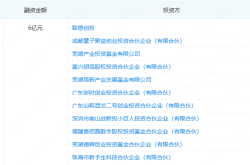
Securing 600 Million Yuan in Funding: This AR Optics Company Steps into the Limelight!
-
![]()
From a 706% Surge to a $340 Billion Market Cap Plummet: Has MiniMax's Moment Passed?
-
![]()
High Demand, Low Stock Price: Can the Emotional Companion Robot Ease UBTECH’s Worries?
-
![]()
Why Does Yin Qi, Who 'Doesn't Listen to Advice,' Insist on Making AI Agent Smartphones? | Interview with Jieyue Xingchen
-
![]()
AI-Generated Code Reveals Surprise That Thrills China