The Research Team from Meta and Oxford University Unveils Latent Visual Reasoning Abilities in LLMs through Pre-training on Reasoning-Centric Data. The study delves into the effects of model and data
 11/17 2025
11/17 2025
 548
548
Leveraging this discovery, Meta introduces a data-centric pre-training methodology tailored for visual perception in LLMs and substantiates its effectiveness through extensive pre-training involving 1 trillion tokens.
Below are the key highlights from the paper:
Throughout the pre-training phase, the team utilized a singular set of decoder-only Transformer models, adhering strictly to the Llama-3 architecture and encompassing five distinct model scale parameters. These models underwent training on varying token volumes, with the maximum reaching 1 trillion.
The research investigated the influence of key variables such as model and data scale, data sources, and the integration of visual world and reasoning data.
The findings demonstrate a positive correlation between VQA performance and both model and data scale. However, this correlation does not manifest uniformly across all visual capabilities.
Generally, both model size and pre-training data volume contribute to enhanced downstream multimodal performance, particularly evident in overall average VQA scores. Yet, a closer examination of different VQA categories reveals notable nuances. While general VQA and knowledge VQA exhibit similar scaling trends, continuously improving with larger model and data sizes, OCR and chart VQA display heightened sensitivity to model size over data volume, with significant performance disparities between models.
Furthermore, specific categories of language pre-training data can bolster certain visual abilities in the final MLLMs. Notably, data pertaining to reasoning and the visual world can markedly enhance performance on vision-centric tasks.
The outcomes reveal substantial variations in downstream multimodal performance attributable to different pre-training data sources. This disparity underscores that varying text data categories lead to distinct and uneven visual priors. Specifically, in vision-centric VQA tasks, superior performance correlates strongly with two data types: reasoning-centric data (e.g., code, mathematics, academia) and corpora rich in visual world descriptions (e.g., art, cuisine).
The team discovered that a modest amount of visual world data is pivotal, yet its contribution swiftly plateaus. Conversely, augmenting the proportion of reasoning-centric data in the pre-training mix incrementally enhances visual abilities, with performance improvements peaking at up to 75%.
Boosting the proportion of reasoning-centric data yields significant performance enhancements, with advantages stabilizing upon reaching 75%. This underscores the importance of a robust reasoning foundation for augmenting visual abilities. In contrast, data explicitly describing the visual world exhibits a rapidly diminishing return trend, with only a small amount being crucial for establishing a baseline.
Meta also puts forth three key hypotheses concerning the structure of perceptual priors, the universality of reasoning, and the impact of data structure on cross-modal matching.
Previous analyses suggest that the origins of perceptual priors are diffuse and most pronounced in diverse data. Is this prior a unified ability, or does it possess more fine-grained characteristics?
The results indicate that perceptual priors are indeed scale-dependent. A plausible explanation is that diverse, unstructured text encompasses a vast vocabulary, compelling the model to learn representations sensitive to fine-grained visual concepts—an ability less critical when recognizing large, obvious objects.
The team posits that the reasoning abilities LLMs acquire from text are not confined to the linguistic realm. Through pre-training on reasoning-centric data, the model can internalize abstract, generalizable principles of logic, structure, and compositionality.
The findings demonstrate that the reasoning abilities LLMs glean from text can be transferred to the visual domain. The team observed a distinct trend: as the proportion of reasoning-centric data increases, the visual reasoning generated by the models becomes not only more logically sound but also significantly longer. For instance, escalating the proportion of code reasoning data from 0% to 100% enhanced logical soundness from 4.52% to 9.52%, while reasoning depth surged more than sixfold.
The team hypothesizes that the structural properties of language data can partially foster representational consistency with visual data.
The results reveal an overall positive but non-monotonic trend in LLM vision alignment scores. As the proportion of structured reasoning data increases, alignment scores generally improve, suggesting that learning from abstract structures can foster more consistent latent spaces. However, this trend peaks at a 75% proportion and then declines at 100%. This may stem from models trained solely on reasoning data acquiring abstract structures but lacking the vocabulary from other text types necessary to effectively map them onto diverse visual concepts, thereby impeding final alignment.
-
![]()
Hunan’s Wealthiest Entrepreneur Eyes Comeback with Apple’s Foldable iPhone
-
![]()
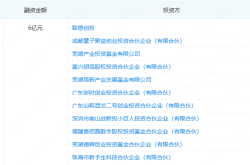
Planning to Secure 1.055 Billion Yuan to Propel AR Optics Forward! Lante Optics Receives Green Light for Private Placement on the Science and Technology Innovation Board
-
![]()
MiniMax: At the Heart of the AI Maelstrom
-
![]()
Securing 600 Million Yuan in Funding: This AR Optics Company Steps into the Limelight!
-
![]()
From a 706% Surge to a $340 Billion Market Cap Plummet: Has MiniMax's Moment Passed?
-
![]()
High Demand, Low Stock Price: Can the Emotional Companion Robot Ease UBTECH’s Worries?
-
![]()
Why Does Yin Qi, Who 'Doesn't Listen to Advice,' Insist on Making AI Agent Smartphones? | Interview with Jieyue Xingchen
-
![]()
AI-Generated Code Reveals Surprise That Thrills China