Significantly Surpassing π0.5 and X-VLA! Tsinghua-Peking University's Latest Motus: All-in-One Understanding, Generation, and Control, Nurturing a "Super Brain" with Massive Video Data
 12/19 2025
12/19 2025
 689
689
Interpretation: AI Generates the Future 
Highlights
Unified Foundation Model: Motus, a unified embodied foundation model, integrates five mainstream paradigms (world models, inverse dynamics models, VLAs, video generation models, and video-action joint prediction models) within a single generative framework without sacrificing general multimodal priors.
MoT Architecture and Joint Attention: Introduces a Mixture-of-Transformer (MoT) architecture, connecting pre-trained video generation, action, and understanding experts through a "Tri-modal Joint Attention Mechanism."
Latent Actions: Utilizes optical flow to learn "latent actions," addressing the challenge of leveraging large-scale unlabeled video data for action pre-training.
Scalable Training Recipe: Proposes a "three-stage training process" and "six-layer data pyramid" to learn transferable motion knowledge across embodied agents using heterogeneous data (internet videos, human videos, multi-robot data, etc.).
Addressed Problems
Fragmented Capabilities: Existing embodied intelligence methods typically isolate perception, world modeling, and control (e.g., VLAs for static policies, WMs for prediction), lacking a unified system to integrate scene understanding, instruction following, future imagination, and action generation.
Heterogeneous Data Utilization: The action spaces of different robots vary significantly, and vast internet video data lack action labels. Current methods struggle to leverage these large-scale unlabeled datasets for learning general motion and physical interaction priors, limiting model generalization.
Proposed Solution
Unified Architecture Motus: Based on the MoT architecture, it integrates a pre-trained video generation model (Wan 2.2 5B) and a visual-language model (Qwen3-VL-2B). Using a UniDiffuser-style scheduler, it achieves unified modeling of marginal, conditional, and joint distributions by allocating different timesteps and noise scales, supporting flexible inference mode switching.
Action-Dense Video-Sparse Prediction: To balance the number of video and action tokens and improve efficiency under action chunking, a sampling strategy with lower video frame rates than action frame rates is adopted.
Optical Flow-Based Latent Actions: Uses a deep compression autoencoder (DC-AE) to reconstruct optical flow, encoding it as low-dimensional latent vectors. Combined with a small number of task-agnostic action labels for supervision, the model learns physical dynamics from unlabeled videos.
Applied Technologies
Mixture-of-Transformer (MoT): A mixture-of-experts architecture.
Tri-modal Joint Attention: A mechanism for cross-modal knowledge fusion.
Rectified Flow: A generative objective based on rectified flows for joint video and action prediction.
Optical Flow & DC-AE: Utilizes DPFlow for optical flow computation and a convolutional variational autoencoder for compression as latent action representations.
UniDiffuser-style Scheduler: A noise scheduling strategy for multimodal generation.
Achieved Results
Simulation Environment (RoboTwin 2.0): In a benchmark test with 50+ tasks, Motus improved by 15% over X-VLA and 45% over , particularly excelling in randomized scenarios.
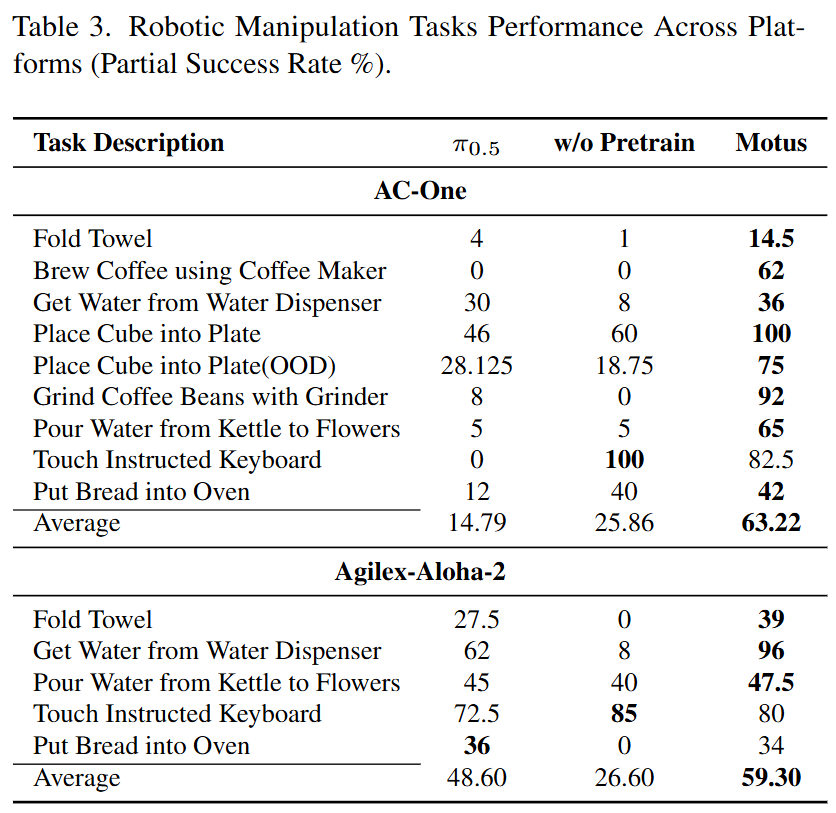
Real-World Environment: Tested on AC-One and Agilex-Aloha-2 dual-arm robots, covering long-range planning and fine manipulation tasks, with success rates improved by 11%–48% over baselines.
Multimodal Capabilities: Demonstrates that the model can serve not only as a policy for robot control but also as a high-quality video generator and world model for future prediction.
Problem Statement and Challenges
Embodied Policies
This work considers language-conditioned robotic manipulation tasks. For each embodied agent, the task defines actions , observations (visual input), language instructions , and the robot's proprioceptive perception , where denote the action space, observation space, and language instruction space, respectively. The task typically provides an expert dataset , containing robot proprioception, visual observations, and actions collected by experts over timesteps, along with language annotations for each trajectory. This work trains a policy parameterized by on . At each timestep , the policy predicts the next actions (i.e., action chunking) based on the current observation and proprioception, modeling either or . The training objective for policy is to maximize the likelihood:
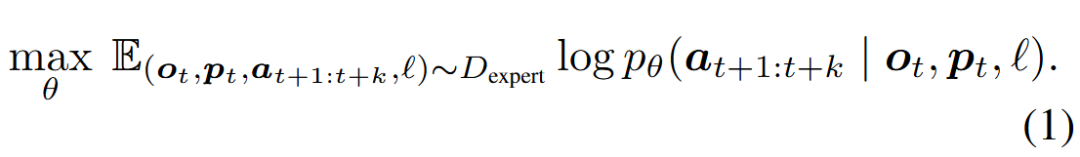
Furthermore, based on the above notations, the probability distributions for five types of embodied intelligence modeling can be derived and integrated into a single model for training:
VLA: .WM (World Model): .IDM (Inverse Dynamics Model): .VGM (Video Generation Model): .Video-Action Joint Prediction Model: .
Challenge 1: Unified Multimodal Generation Capability
A capable embodied agent must function as a unified whole, integrating a range of cognitive functions—from understanding scenes and instructions, imagining possible futures, to predicting consequences and generating actions. Current models are fragmented, unable to capture all necessary capabilities within a single system. This raises a challenge: how to uniformly model five key distributions—VLA, world model, IDM, video generation model, and video-action joint prediction model—within one framework. While previous work (e.g., UWMs) has made progress, a critical limitation remains: these methods are either trained from scratch, built upon smaller foundation models, or—even when incorporating some priors—always lack comprehensive knowledge, missing either visual understanding priors from VLMs or physical interaction priors from VGMs. Consequently, they lack the holistic world knowledge required for robust and generalizable embodied intelligence. Thus, the extraordinary challenge of jointly modeling various distributions of vision, language, and actions within a unified framework remains unresolved—a gap this work fills.
Challenge 2: Utilization of Heterogeneous Data
A core challenge in embodied intelligence is effectively leveraging large-scale heterogeneous data. The action spaces of different embodied agents vary significantly in dimensionality, range, and semantics, while robots also differ in morphology, actuation, and sensing. As a result, control signals cannot be directly reused, and policies struggle to learn generalizable priors transferable across embodied agents. Existing methods attempt to address this by using generic backbone networks with embodied-specific information injection or constructing high-dimensional action vectors that forcibly unify different embodied agents. However, they still rely primarily on labeled robot trajectories and fail to integrate these datasets with large-scale internet videos or egocentric human videos that lack action annotations but contain rich motion and physical interaction cues. This limitation hinders large-scale pre-training of action experts and reduces the ability to learn general motion priors.
Methodology: Motus
Model Architecture: To address the challenge of unified multimodal generation capability outlined earlier, this work proposes Motus, a unified latent action world model. First, Motus is designed as a general generative model for joint learning on heterogeneous multimodal data, integrating multiple capabilities of a general system (e.g., modeling five distributions) within a single network. Second, to avoid impractical demands for massive aligned multimodal data, Motus leverages the rich pre-training priors of existing foundation models. It integrates a pre-trained VGM (generation expert), an understanding expert with a pre-trained VLM, and an action expert within a Mixture-of-Transformer (MoT) architecture (as shown in Figure 1), effectively fusing their complementary strengths—covering scene understanding, instruction interpretation, consequence prediction, future video imagination, and action planning—without requiring complete training from scratch.
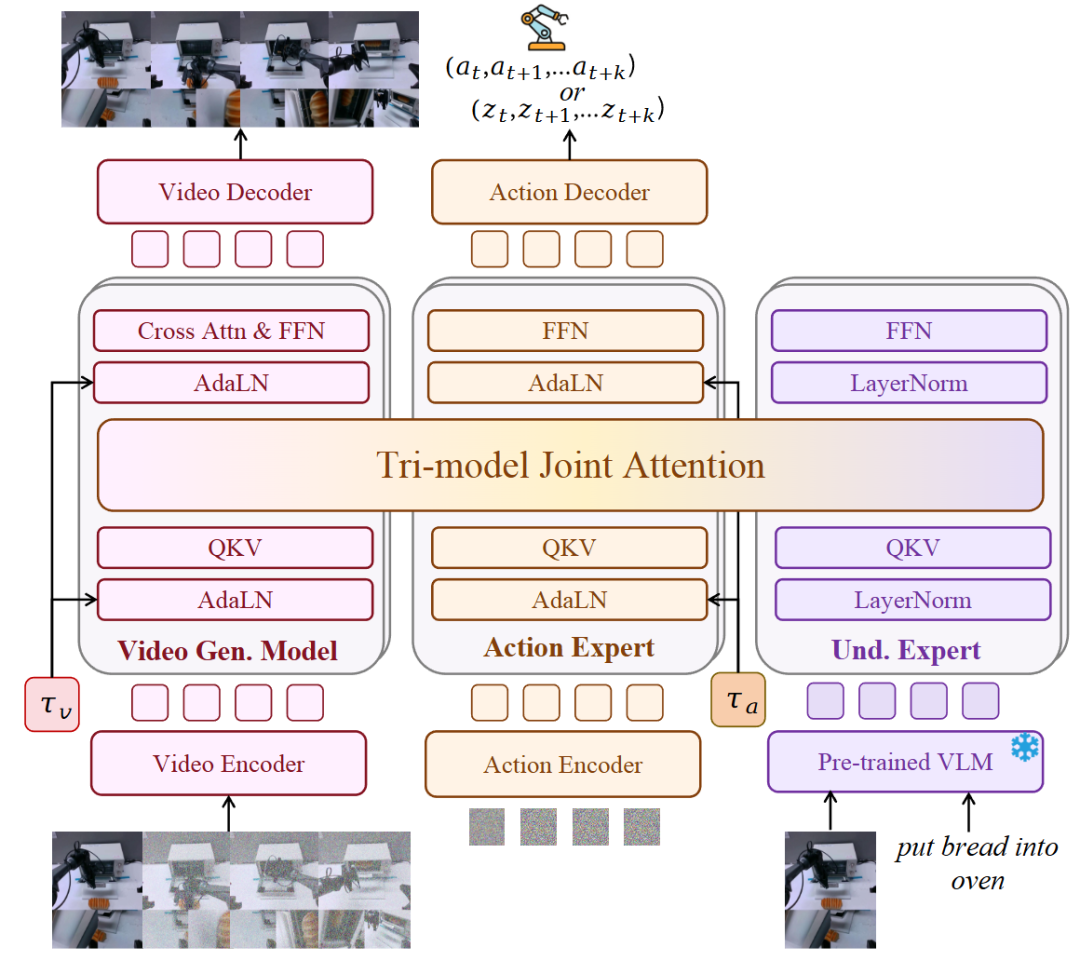 Figure 1. Motus Architecture. Here, ... represents actions, ... represents latent actions, and τv and τa are the rectified flow timesteps for the video generation model and action expert, respectively.
Figure 1. Motus Architecture. Here, ... represents actions, ... represents latent actions, and τv and τa are the rectified flow timesteps for the video generation model and action expert, respectively.
Unlike Unified World Models (UWMs), which simply concatenate observation tokens and action tokens and process them through a single block of UWMs (containing self-attention and feedforward network (FFN) layers), our approach leverages pre-trained VLMs and VGMs through the MoT structure. In this model, each expert maintains an independent Transformer module, while the multi-head self-attention layers are connected, i.e., **Tri-modal Joint Attention**. This not only preserves the unique functional roles of experts without causing task interference but also enables effective cross-modal feature fusion, encouraging diverse pre-trained knowledge to complement each other. During training, Motus jointly predicts video chunks and action chunks using a rectified flow-based objective:
where is the conditional frame, are subsequent observations and actions, and are the allocated timesteps, is the sampled Gaussian noise, is the velocity field predicted by the unified model, and are the losses for observations and actions, respectively. By assigning different timesteps and noise scales to videos and actions, Motus establishes a UniDiffuser-style scheduler to capture heterogeneous data distributions and adaptively switch between various embodied foundation model modes during inference (e.g., VLA, world model, IDM, VGM, joint prediction). The final model achieves scene understanding, instruction following, consequence prediction, future imagination, and action output within a unified multimodal architecture.
Action-Dense Video-Sparse Prediction: Since our model builds upon the widely cited action chunking technique, Motus needs to predict future video chunks and action sequences . This leads to several issues: (1) low training and inference efficiency, (2) redundant video frame prediction, and (3) imbalance in the tri-modal joint attention mechanism—where the number of video tokens significantly exceeds action tokens. This imbalance causes the model to overfit video prediction, weakening its action prediction capability. To address these issues, this work proposes an Action-Dense Video-Sparse Prediction strategy, as shown in Figure 2. During training and inference, we downsample video frames to balance the number of video and action tokens—e.g., setting the video frame rate to one-sixth of the action frame rate.
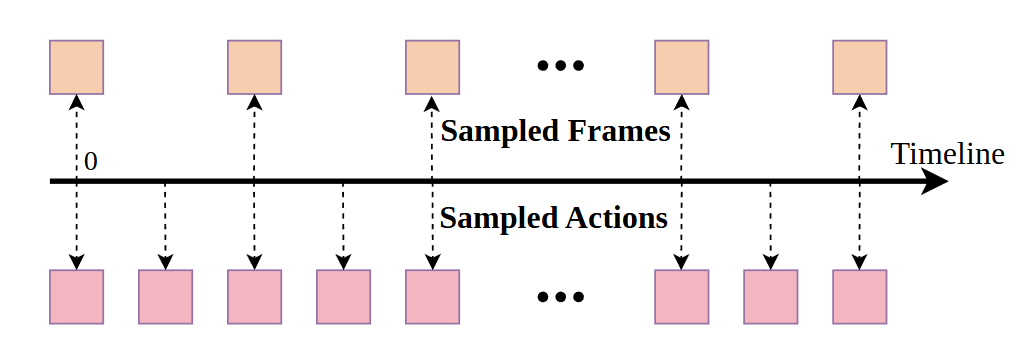 Figure 2. Action-Dense Video-Sparse Prediction. Different sampling rates for video frames and actions.
Figure 2. Action-Dense Video-Sparse Prediction. Different sampling rates for video frames and actions.
Expert Details
For the generation expert, this work adopts Wan 2.2 5B as the video foundation model due to its accessibility and ease of use. We extend its self-attention context to create a cross-modal tri-modal joint attention mechanism. For the action expert, we construct a Transformer block with the same depth as Wan. Each block includes AdaLN for injecting rectified flow timesteps, a feedforward network (FFN), and tri-modal joint attention for cross-expert interaction. We choose Qwen3-VL-2B as the understanding expert for its inherent capabilities in 3D grounding, spatial understanding, and precise object localization, which are crucial for robotic manipulation. The expert's input is taken from the last layer of corresponding VLM tokens. The understanding expert itself consists of several Transformer blocks, each containing layer normalization, an FFN, and tri-modal joint attention.
Latent Actions
This work further addresses Challenge 2 by learning generalizable action patterns directly from visual dynamics to leverage large-scale heterogeneous data. Specifically, we introduce **latent actions**, which encode motion learned directly from pixels. These latent actions allow the model to absorb motion knowledge from diverse sources such as internet videos, egocentric human demonstrations, and multi-robot trajectories, enhancing the pre-training of action experts even on data without explicit action labels.
Optical Flow-Based Representation
This work adopts optical flow as a natural representation of motion, capturing pixel-level displacements between consecutive frames. Specifically, optical flow is computed by DPFlow and then converted into an RGB image. To compress this high-dimensional representation into a control-level space, we employ a deep convolutional variational autoencoder (DC-AE), which reconstructs optical flow while encoding it into four 512-dimensional tokens. A lightweight encoder then projects these concatenated features into a 14-dimensional vector, roughly matching the scale of typical robotic action spaces. The overall architecture is shown in Figure 3. This dimensional correspondence ensures that latent representations naturally align with real robotic control and serve as a bridge between perception and action.
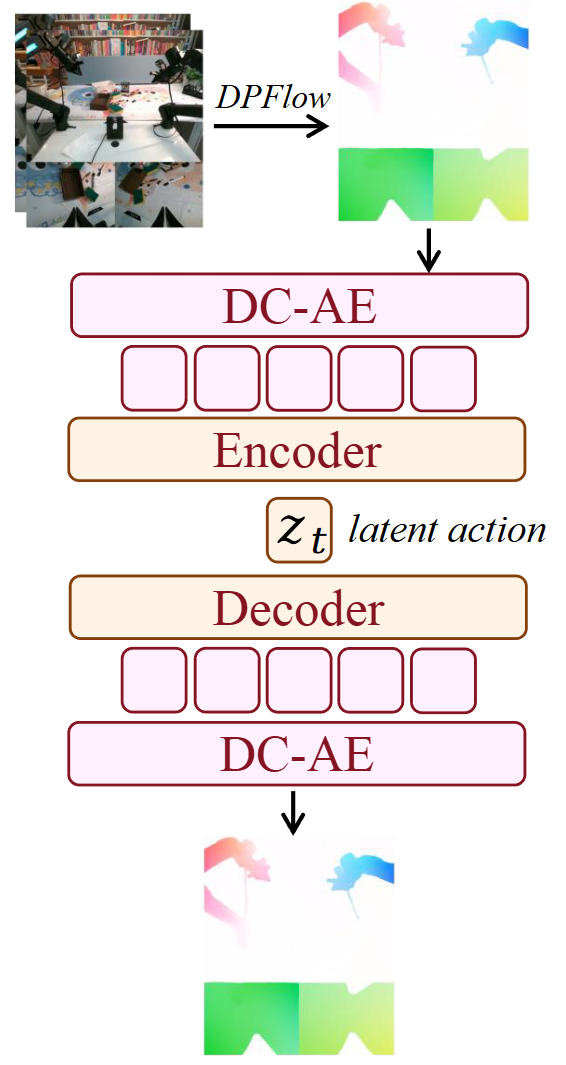 Figure 3: Latent Action VAE
Figure 3: Latent Action VAE
Training and Distribution Alignment: To facilitate the alignment of the latent space with realistic action spaces, we follow the approach of AnyPos by integrating task-agnostic data. Specifically, task-agnostic data is collected using Curobo to randomly sample the target robot's action space in a task-independent manner, generating image-action pairs. These data provide additional real-world action supervision, aiding the VAE in learning embeddings that reflect feasible motion behaviors and anchoring latent actions to realistic control distributions.
During training, we mix 90% unlabeled data for self-supervised reconstruction with 10% labeled trajectories for weak action supervision. The labeled portion includes both task-agnostic data and standard robot demonstrations. Dimensional correspondence and weak action supervision jointly drive the alignment of the latent action distribution with the real action distribution, enabling motion priors learned from videos to naturally map to executable controls.
The total loss combines reconstruction, alignment, and KL regularization:
Here, minimizes optical flow reconstruction error, the second term aligns latent and real actions, and regularizes the latent space; and are hyperparameters.
Model Training and Data
Motus Training: Motus is trained in three structured phases (Table 1), progressively integrating physical interaction priors from diverse datasets into policies transferable to target robots. Each phase addresses a key challenge:
Phase 1: Learning Visual Dynamics. To anchor the model in realistic physical interactions, we first fine-tune a video generation model (VGM) using multi-robot trajectories and human videos. This enables the VGM to generate plausible future video sequences for a task based on language instructions and an initial image.
Phase 2: Latent Action Pretraining. In this phase, we use a latent action VAE to encode optical flow into "pseudo-action" labels. This allows an action expert to pretrain on large-scale video datasets (including internet and human videos) without requiring real action annotations. This process establishes a general motion prior and an understanding of physical causality in the action expert.
Phase 3: Embodiment-Specific Action Fine-Tuning. Finally, we fine-tune the entire model (including understanding, generation, and action experts) on a specific dataset for the target robot. This phase adapts the model to the specific kinematics and dynamics of the target embodied agent, transforming general motion knowledge into precise control policies.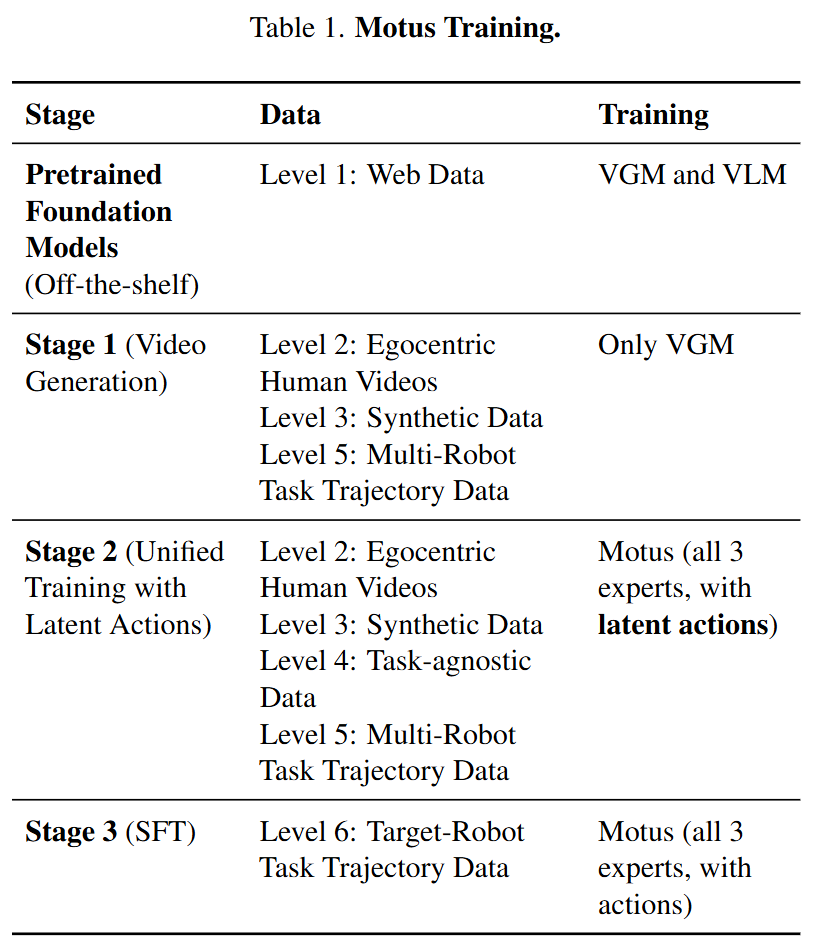
Six-Layer Data Pyramid: To support this progressive learning, we construct a hierarchical data pyramid organized by scale and specificity:
Web-Scale Videos: Provide broad world knowledge and diverse scenarios (e.g., Ego4D, Something-Something v2).
Human Egocentric Videos: Offer rich hand-object interactions from a robot-like first-person perspective (e.g., Ego4D subsets).
Simulation Data: Supply large-scale, diverse physical interactions with perfect action labels (e.g., SimplerEnv, RoboTwin).
Task-Agnostic Robotic Data: Bridge visual motion and physical control without task-specific semantics.
Multi-Robot Trajectories: Demonstrations from various robot platforms (e.g., BridgeData V2, Open X-Embodiment) provide cross-embodiment generalization.
Target Robotic Data: Task-specific demonstrations for the target robot, used for final fine-tuning. Figure 4. The embodied data pyramid organizes data into six tiers, ranging from Level 1 at the bottom to Level 6 at the top. Data volume decreases from bottom to top, while data quality improves. The order of Levels 3 and 4 may occasionally vary.
Figure 4. The embodied data pyramid organizes data into six tiers, ranging from Level 1 at the bottom to Level 6 at the top. Data volume decreases from bottom to top, while data quality improves. The order of Levels 3 and 4 may occasionally vary.
Experiments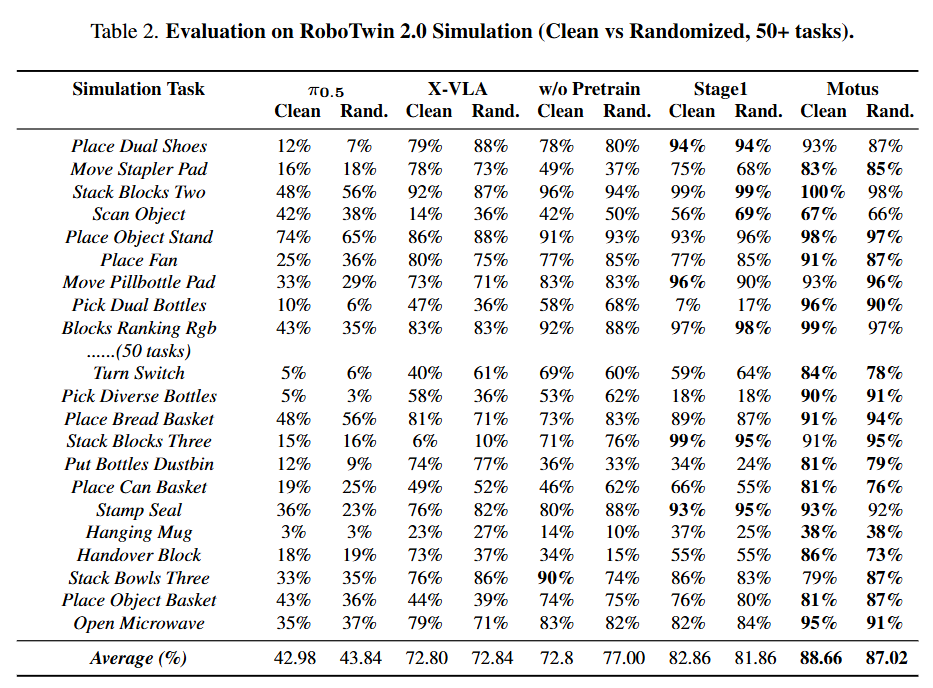
Experimental Setup:
The model has a total of approximately 8B parameters (Wan 2.2 5B + Qwen3-VL 2B + lightweight Action Expert).
Baselines: Compared with models such as (Pi-zero), X-VLA, and Octo.
Simulation Experiments (RoboTwin 2.0):
Tested on a benchmark containing 50+ tasks, including "clean scenes" and "randomized scenes" (with randomized backgrounds, lighting, and distractors).
Results: Motus achieved an average success rate of 87.02% in randomized settings, improving by approximately 45% over (42.98%) and by approximately 15% over X-VLA (72.84%). This demonstrates Motus's strong robustness in handling out-of-distribution (OOD) scenarios.
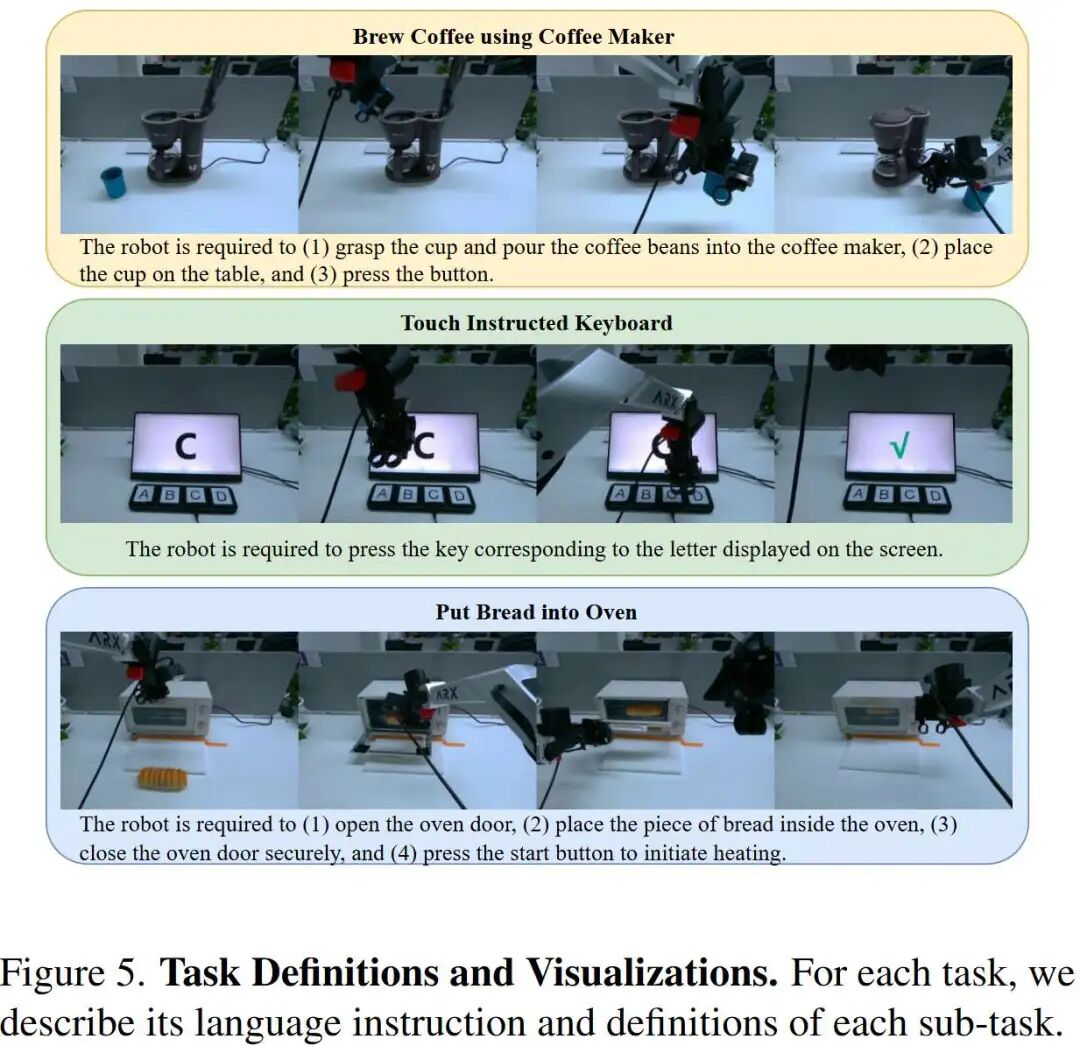
Real-World Experiments:
Platforms: AC-One and Agilex-Aloha-2 dual-arm robots.
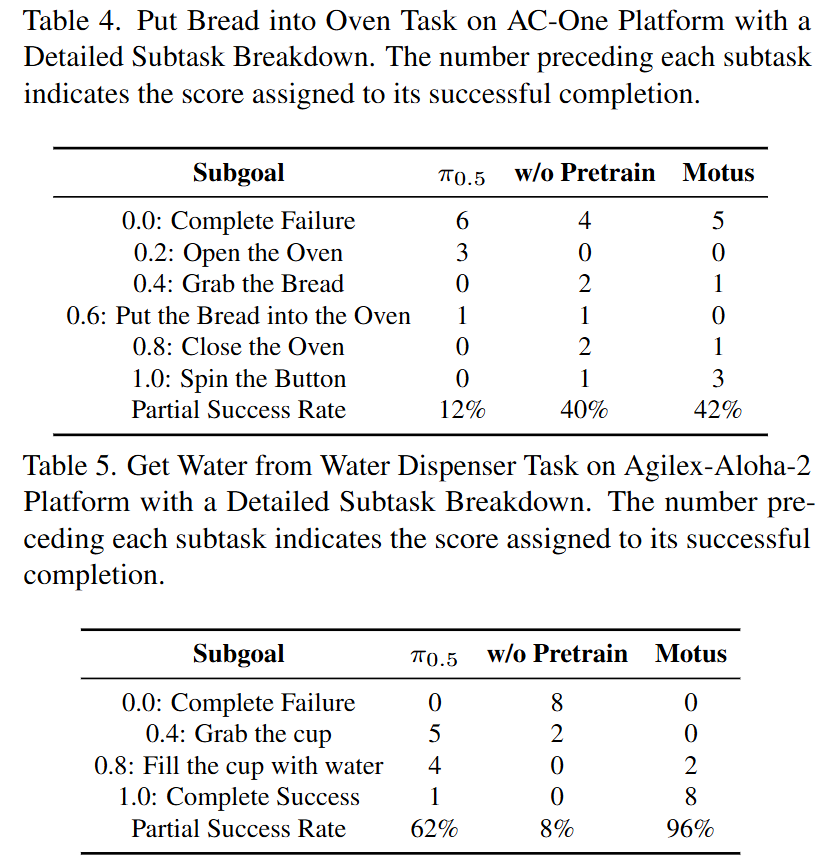
Tasks: Included long-horizon tasks such as folding towels, brewing coffee, pouring water, and grasping objects.
Results: On AC-One, Motus achieved an average success rate of 63.22% (baseline was 14.79%); on Aloha-2, Motus achieved 59.30% (baseline was 48.60%). This showcases the model's generalization ability to unseen objects (OOD Cube) and complex operational sequences.
Ablation Studies:
Verified the importance of the pretraining phase. Models without pretraining performed the worst, while Phase 1 pretraining (visual dynamics) alone provided some improvement. Full Phase 2 pretraining (latent actions) delivered the largest performance leap.
Multimodal Capability Verification:
VGM Mode: Generated high-quality future video frames.
WM Mode: Accurately predicted future states based on actions.
IDM Mode: Outperformed specially trained ResNet/DINOv2 IDM baselines in inverse dynamics prediction error (MSE) (0.014 vs. 0.044/0.122).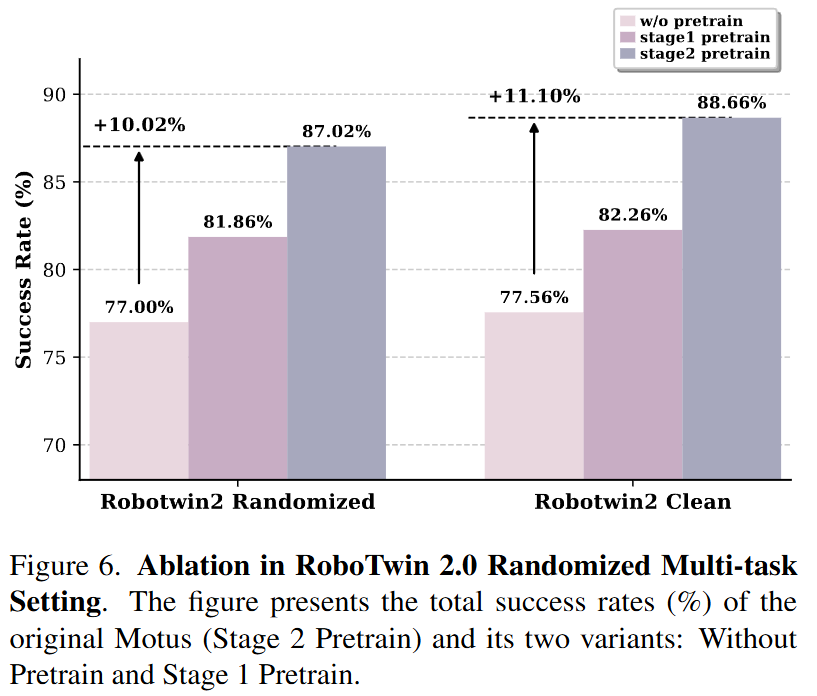
Conclusions and Limitations
Motus is a unified latent action world model that integrates mainstream capabilities of embodied foundation models into a single generative framework, including visual-language understanding, video generation, inverse dynamics, world modeling, and joint video-action prediction. By connecting pretrained experts with MoT, coordinating multimodal modeling with a UniDiffuser-style scheduler, and introducing latent actions as pixel-level "Delta Actions" and motion representations, Motus effectively learns from large-scale heterogeneous data and inherits general multimodal priors and rich physical interaction knowledge. Extensive experiments in simulated and real-world scenarios demonstrate that unified modeling of all capabilities and priors significantly benefits downstream robotic tasks.
Limitations: Despite promising results, Motus requires substantial computational resources for training and inference, which may limit its real-time applicability. Additionally, while latent actions bridge the gap between vision and control, their fidelity may still fall short of direct high-frequency proprioceptive control in extremely fine-grained manipulation tasks. Future work will focus on optimizing inference efficiency and exploring higher-fidelity latent action representations.
References
[1] Motus: A Unified Latent Action World Model
-
![]()
China’s Computing Reaches New Heights: From LingSheng to Shuguang 8000
-
![]()
Avita's Second Attempt at HKEX Listing: What Sets It Apart? | Auto Circle
-
![]()
Tencent Spearheads Manus Buyback: Unveiling the Strategy
-
![]()
Will Changan Mazda, Mired in Difficulties, Follow Skoda’s Path Out of China?
-
![]()
This Week in Home Appliances: Domestic Cool, Overseas Hot – Haier, Midea, Gree, Hisense Break Through; JD.com, TCL, Samsung, Vanward Drive Transformation
-
Seres Anticipates Over 2.2 Billion Yuan Loss in Q2, with Core Subsidiary AITO Automobile Projected to Lose 1.9-2.15 Billion Yuan
-
![]()
Breaking Through Barriers: Five Models for Chinese Automakers to Access Global Markets
-
![]()
Young Generation Trades Cars as Often as Smartphones! Average Age of New Energy Vehicles: Just 1.8 Years...