Apple Launches VSSFlow Model: Enabling Silent Videos to 'Speak' and Paving the Way for Apple Intelligence in China?
 02/12 2026
02/12 2026
 598
598
It's somewhat useful, but not groundbreaking.
At WWDC 2024, Apple unveiled its AI platform, Apple Intelligence. In autumn 2024, Apple Intelligence commenced testing in the U.S., with plans to gradually expand to more regions.
However, as of now, the Chinese version of Apple Intelligence is yet to be launched. Apple's official stance is that "the introduction of Apple Intelligence in China is contingent upon regulatory approval."
" "
"
(Image source: Apple)
Recently, the renowned Apple news site 9to5Mac reported that Apple, in collaboration with Renmin University of China, has introduced the VSSFlow, a new AI model, marking a breakthrough in audio generation technology. This move by Apple not only showcases its AI technical prowess but also hints at positive developments regarding Apple Intelligence in China. Is Apple Intelligence truly on the horizon?
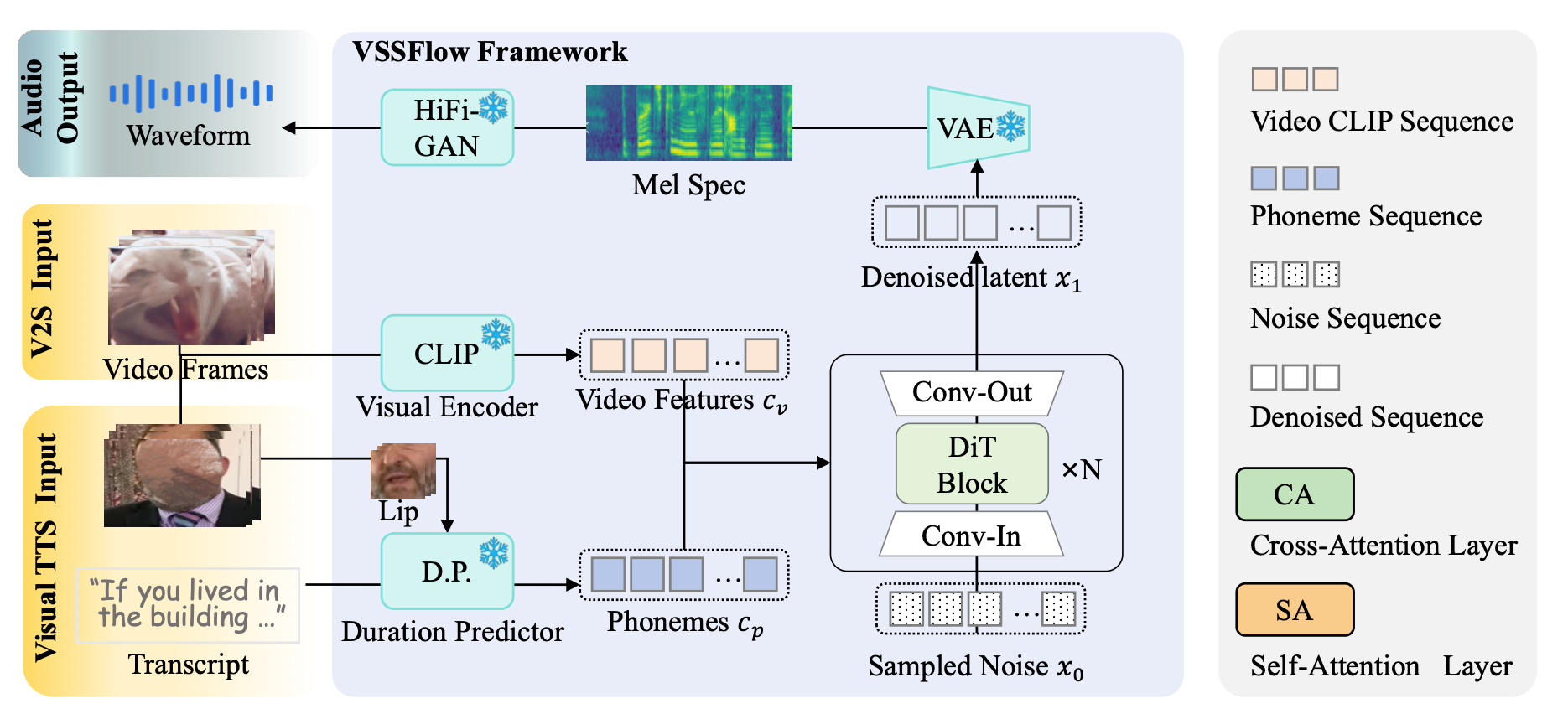
What challenges can VSSFlow address with its automatic dubbing capabilities for silent videos?
Through the joint paper released by Apple and Renmin University of China, as well as related reports from 9to5Mac, we learn that VSSFlow's main innovation is breaking the previous limitation where 'ambient sounds' and 'dialogue voices' had to be generated separately. Specifically, most prior video-to-speech models processed ambient sounds and human voices in audio independently, whereas VSSFlow excels in one-stop, simultaneous generation.
" "
"
(Image source: arXiv)
According to the official description, the VSSFlow model generates ambient sounds by analyzing 10 video frames per second as cues and then gradually 'constructing' the sound from random noise. While this may sound straightforward, the implementation is complex. For a silent video, AI cannot 'hear' anything; it essentially 'predicts' the most realistic ambient sounds based on the video frames, such as identifying specific real-world scenes and matching corresponding ambient sounds.
The paper on VSSFlow highlights a key technical aspect—Flow-matching. In the AI realm, models must infer and generate the most plausible sounds from chaotic information. Video frames contain clues corresponding to sounds, and AI must establish a pathway—a 'flow'—between this chaotic 'noise' and the target sound. The key to establishing this 'flow' is a precise understanding of video frames and text scripts.
" "
"
(Image source: arXiv)
Regarding text-to-speech capabilities, many solutions have existed since the early days. For instance, earlier smartphones and numerous reading apps featured TTS (text-to-speech) functionality, which simply converted text directly into pre-recorded audio from a voice library. However, this approach was rudimentary, resulting in mechanical-sounding voices with awkward phrasing in long sentences. In the AI era, large models have significantly enhanced the text-to-speech experience, making voices sound more human-like, with natural phrasing, tone, and emotion.
VSSFlow's video-to-human-voice technology generates audio by combining video scripts and frames, matching speech tone, emotion, and rhythm based on factors like characters' lip movements and facial expressions, resulting in more realistic AI-generated human voices.
As mentioned earlier, VSSFlow can simultaneously generate ambient sounds and human voices for videos. According to the official description, they integrate video signals and text transcriptions into the audio generation process. To achieve this, researchers conducted mixed-data training, specifically using silent videos with ambient sounds, silent speaking videos with text, and pure text-to-speech data for VSSFlow model training.
In summary, VSSFlow is a large video-to-audio model capable of simultaneously generating ambient sounds and human voices for silent videos. Its core advantage lies in enhancing generation efficiency and audio quality through flow-matching technology.
AI-generated speech: somewhat useful but still limited
What specific scenarios can VSSFlow's ability to generate ambient sounds and human voices for videos be applied to? The primary applications that come to mind are audio restoration for old films, assistive audio for individuals with speech impairments, and dubbing for film and television. After all, VSSFlow still relies on text scripts to generate human voices and cannot infer them solely from video frames, making it more akin to an advanced dubbing tool.
The large model most similar to VSSFlow currently on the market is likely Google's DeepMind V2A (Video-to-Audio). V2A also generates corresponding ambient sounds and dialogue based on video frames and text scripts, using a technical approach that establishes a mapping mechanism between visual and auditory information.
Specifically, visual information primarily includes space, color, shape, and motion, while auditory information generally involves timbre, frequency, and rhythm—different semantic domains. By mapping visual and auditory features at multiple levels and undergoing continuous training, AI can 'predict' the audio with matching auditory characteristics based on video frame information.
" "
"
(Image source: Google)
However, in my view, the application scenarios for video-to-speech technology are still somewhat niche. For average users, this functionality is not particularly impactful. In contrast, current popular video generation technologies are more welcomed by creators and ordinary users. With just a few sentences or images, users can quickly generate highly realistic videos, offering both practicality and entertainment. For example, the recent Seedance 2.0 went viral immediately after its release, with many users trying it out right away.
" "
"
(Image source: Leikeji, created using Seedance 2.0)
However, the scenario of dubbing silent videos is rarely encountered by most people, as we don't typically create or obtain silent videos without reason. It is more applicable to niche areas within the film and television production industry, such as the work of traditional Foley artists.
Many ambient and action sounds heard in films and TV shows are actually recorded by Foley artists in studios, such as using coconut shells to simulate horse hooves or rattling a doorknob to mimic cocking a pistol. Meanwhile, VSSFlow's ability to generate human voices based on scripts and frames is similar to the dubbing work done by anime voice actors. It is foreseeable that audio generation technology will have a significant impact on the film and television industry in the future.
At the same time, speech generation models like VSSFlow are unlikely to be released as standalone applications for ordinary users but will play a greater role when combined with other AI technologies. For example, they could be integrated with video generation models. Currently, most videos generated by popular video generation models include dubbing.
However, the quality of background audio and human voices in many AI-generated videos is relatively average. With the assistance of speech generation models like VSSFlow, the overall effect would be better. In fact, Google DeepMind's V2A technology was not released as a standalone model but was partially integrated into Google's own video generation model, Veo.
Is Apple's AI for China on the horizon after partnering with a top Chinese university?
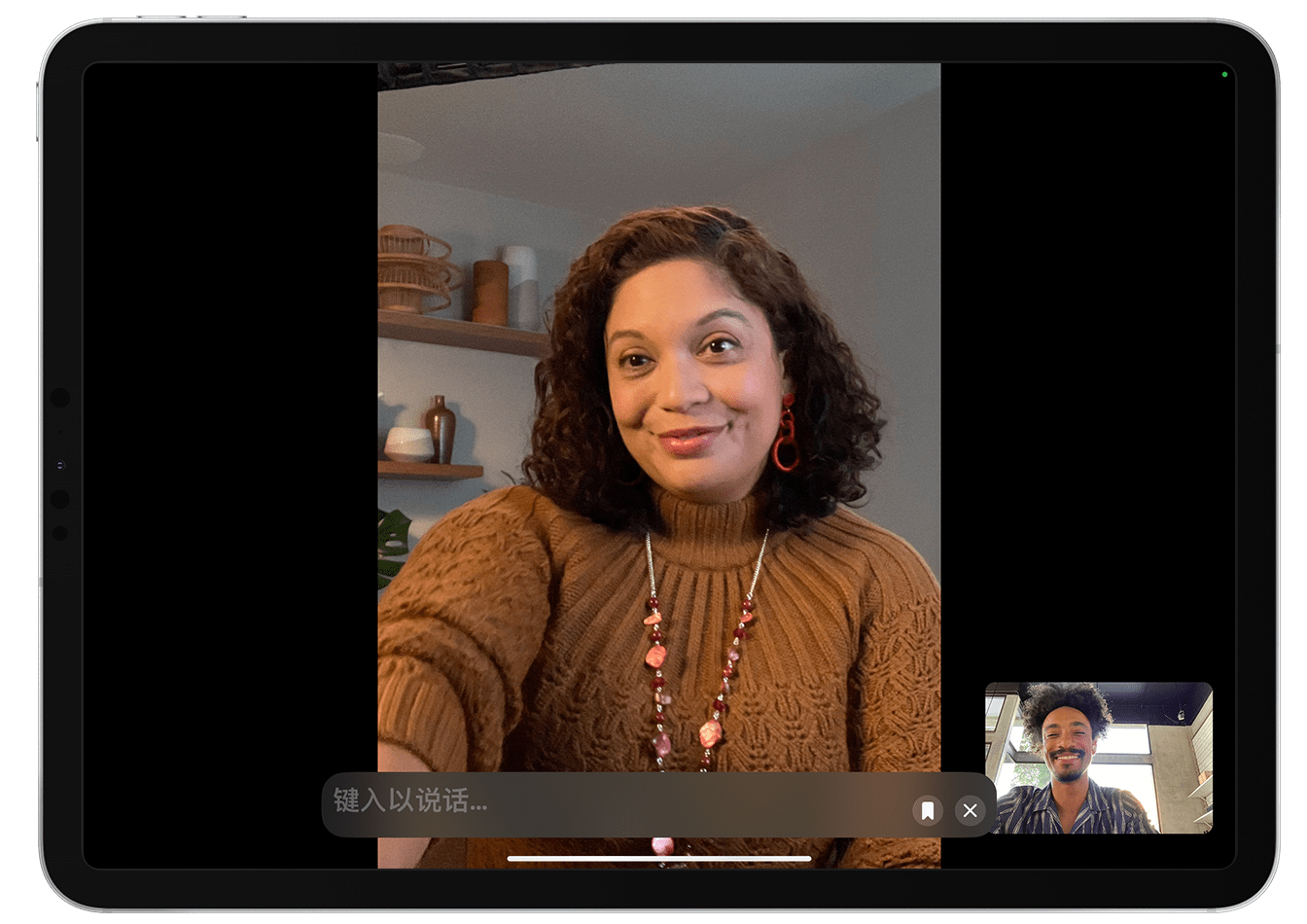
For Apple products, the first scenario that comes to mind for VSSFlow's application is accessibility features. Currently, Apple devices already offer real-time voice functionality in their accessibility options, allowing users to type on their phones and convert the text into audio.
" "
"
(Image source: Apple)
If VSSFlow could be applied in this scenario, individuals with speech impairments could input text during video calls on FaceTime and have AI generate more natural-sounding human voices by combining video frames. Of course, this technology could also serve as a reserve in Apple's AI arsenal, supporting future functions or applications like video generation.
Moreover, Apple's collaboration with a top Chinese university to jointly release VSSFlow undoubtedly sends a positive signal about its commitment to the Chinese market and its efforts to promote the launch of Apple Intelligence in China. In the VSSFlow paper, six of the authors are scholars from Renmin University of China, while three are Apple researchers. In this project, Apple's role is closer to that of a supporter and participant rather than a leader.
Currently, the Chinese version of Apple Intelligence has not yet been released. According to Apple's policy, Chinese versions of iPhones and other devices cannot use the international version of Apple Intelligence, and future international hardware products will not be able to use the Chinese version of Apple Intelligence.
It is almost certain that in the rollout of the Chinese version of Apple Intelligence, Apple will collaborate with domestic AI giants. Previous rumors have mentioned Baidu, Alibaba, and DeepSeek as companies Apple has approached. In 2025, renowned Bloomberg journalist Mark Gurman revealed that the Chinese version of Apple Intelligence would use a local model provided by Alibaba for on-device support and Baidu's ERNIE Bot for cloud-based AI support. However, the Chinese version of Apple Intelligence failed to launch in 2025, primarily due to engineering challenges and underwhelming performance of the domestic AI.
Even ignoring the absence of the Chinese AI version, Apple's AI strategy lags behind competitors. Currently, the functions and scenarios implemented by the international version of Apple Intelligence are not particularly remarkable and have even been criticized for Apple's relatively weak AI capabilities. For example, Apple's recently launched generative image app, Image Playground, has faced significant backlash. The app strictly controls image generation, rejecting many user requests and being criticized as a product suitable only for children.
Apple Intelligence has also brought in external support, primarily ChatGPT, with Gemini to follow. ChatGPT has been integrated into Siri, making it more like a fully-fledged intelligent assistant rather than a traditional voice assistant. Additionally, AI-related features include a writing assistant and image erasure. However, Apple's so-called AI features lack a strong sense of impact and feel somewhat trivial in practice.
Moreover, the AI promises Apple made for iOS 26 have yet to materialize for users. According to the latest news, the first beta version of iOS 26.4 will be released in late February, bringing some AI-related changes. This system update will primarily enhance Siri, including adding contextual understanding, cross-app operation capabilities, and screen awareness. Frankly, these upgrades are still unexciting and will only make iOS 26 slightly more usable.
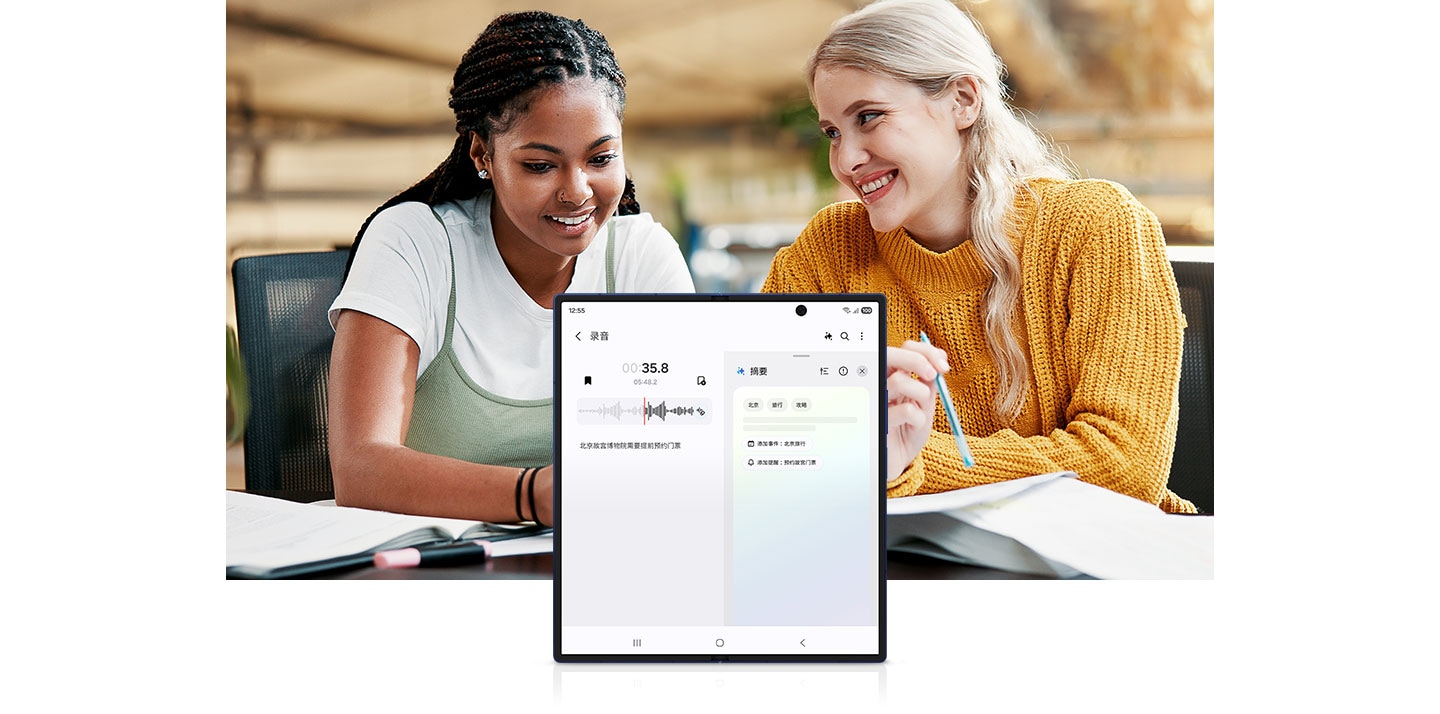
In contrast, Samsung launched its AI phone as early as 2024 and quickly completed AI localization for its Chinese versions. Specifically, the large model responsible for text understanding and generation in Chinese versions is Baidu's ERNIE Bot, used in scenarios like note-taking assistants and audio transcription summaries. Its generative image editor integrates Meitu's MiracleVision model for functions like smart erasure and image expansion. The Chinese version's circle-to-search feature relies on backend data from Baidu Search and JD.com. Additionally, Samsung's Chinese phones offer some on-device AI functions, such as real-time call translation and split-screen simultaneous translation, based on Samsung's self-developed local AI models.
" "
"
(Image source: Samsung)
In other words, Apple could largely follow Samsung's example for its China AI strategy. Compared to the international version of Apple Intelligence, the core task for the Chinese version is to replace the large models involved with domestic alternatives, as Samsung has demonstrated.
Personally, I believe the slow progress of Apple's China AI is primarily Apple's responsibility. After all, the rollout of the international version of Apple Intelligence has also been fraught with challenges, and the actual AI experience has been underwhelming. With such execution, the efficiency of promoting the Chinese version of Apple Intelligence is predictable.
Nevertheless, Apple's involvement in VSSFlow at least shows that the company is not idle in the AI field. If Apple can continue to produce results in AI research, its hardware AI transformation process will benefit, which is key to building Apple's future underlying competitiveness.
" "
"
Apple Apple Intelligence VSSFlow AI Large Model
Source: Leikeji
Pictures of this article are from 123RF royalty-free library Source: Leikeji
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




