Pricing Power vs. War of Attrition: Strategies for Large Models in the Second Half
 04/09 2026
04/09 2026
 575
575


Faced with the anxiety over AI computing power, the large model industry is experiencing a divergence. On one hand, there are companies like Zhipu and Kimi, which employ a traffic-centric strategy, competing on price to achieve scale. On the other hand, firms such as Xiaomi are focusing on reducing consumption to enhance efficiency on end devices. This divergence is not merely technical but represents the ultimate contest between computing infrastructure and soft-hard ecosystem barriers.
Original Tech Insights, AI New Tech Team
The AI community is currently grappling with profound concerns over computing power.
Faced with the Sino-US AI competition and the exponential growth in large model inference demand, spurred by trends such as "lobster" (a metaphor for rapid growth), the computing power shortage looms large over all industry players. However, the industry is responding to this challenge through two distinct approaches.
On one side is the "price-cutting faction," led by Zhipu, Kimi, and the overseas chip upstart Taalas. They leverage capital and hardware innovation to drastically reduce token prices, aiming to scale their ecosystems through extreme affordability. On the other side is the "consumption-reducing faction," represented by end-device giants like Xiaomi, which argue that the solution lies not in cheaper tokens but in more token-efficient underlying frameworks.
This divergence is not just a technical debate but a strategic dispute over discourse power, business models, and the flow of computing power in the AI era.
01
The Ruthless Efficiency of the Price-Cutting Faction

At the forefront of the large model landscape, the price-cutting faction is undoubtedly the most vocal and aggressive. Their core strategy is straightforward: if high computing power costs hinder AI adoption, then token prices must be driven down through commercial subsidies or disruptive hardware restructuring, making AI as accessible and ubiquitous as tap water. This faction includes AI startups aiming to expand the market with classic internet tactics and hardcore enthusiasts driving innovation from the chip physics layer.
First, there is the commercial strategy of reducing prices at the software and API levels. Led by AI "Six Little Dragons" such as Zhipu, Kimi, and MiniMax, a fierce price war has erupted in recent months, with API call prices for some foundational models nearing zero.
This tactic is familiar to internet veterans—a classic loss-leader strategy. They understand that in the large model era, the competitive advantage lies in application ecosystems and data flywheels. Only if frontend tokens are cheap enough will B-end developers dare to build native apps, and C-end users adopt them as high-frequency tools.
These AI startups are using anticipated future market share to offset current computing costs. They bet on scale effects: when call volumes explode geometrically, data center marginal costs will plummet. Meanwhile, massive high-quality interaction data feeds back into models, creating winner-takes-all monopolistic barriers. In this logic, price cuts are not a last resort but a strategic weapon to seize the AI-era operating system gateway.
Second, there is the physical-level price-cutting revolution at the silicon layer. The price-cutting faction is not limited to software subsidies; hardware disruptors like Taalas have also emerged. Founded by Tenstorrent's former CEO Ljubisa Bajic, this AI chip startup has ambitions far beyond mere API price cuts. Taalas's approach is to hardcode specific large models (e.g., 100-billion-parameter models) directly into silicon to create dedicated AI chips (ASICs), bypassing the massive resource redundancy and energy waste associated with general-purpose GPUs.
 Figure/Ljubisa Bajic
Figure/Ljubisa Bajic
By implementing model computation logic directly on chips, Taalas aims to bypass traditional memory read bottlenecks, achieving efficiency gains and cost reductions hundreds to thousands of times greater than traditional GPUs. If China's AI Six Little Dragons slash frontend token prices through business models, Taalas seeks to obliterate backend token production costs through hardware restructuring.
Whether through subsidy wars or chip wars, the price-cutting faction's ultimate belief lies in the continuation of Moore's Law. They believe computing power's absolute price will inevitably trend toward cheapness, and whoever provides the cheapest computing power first will dominate as the AWS or infrastructure king of the AI era.
02
The Efficiency Revolution of the Consumption-Reducing Faction
While the price-cutting faction clashes fiercely in the cloud computing arena, the consumption-reducing faction, led by Xiaomi, is moving in the opposite direction. A quote from Luo Fuli, head of Xiaomi's MiMo team, perfectly encapsulates this camp's technical philosophy: the solution to AI's computing power shortage lies not in cheaper tokens but in the co-evolution of more token-efficient frameworks and higher-efficiency models.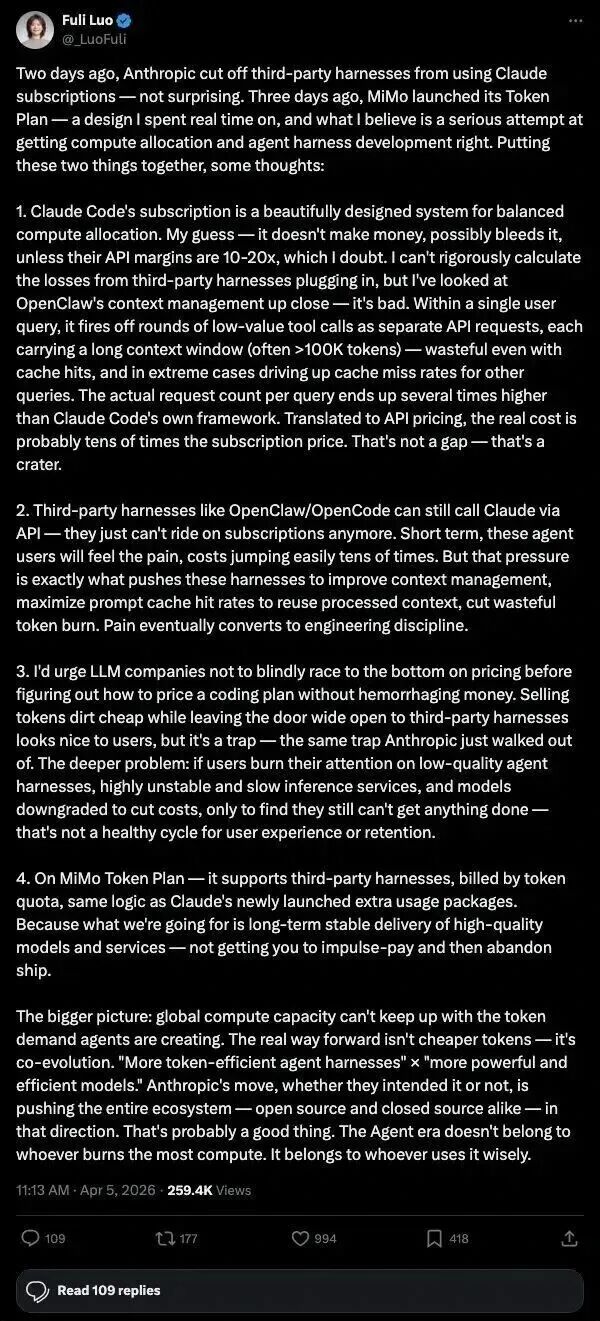
Swipe to view more
If the price-cutting faction seeks cheaper water sources, the consumption-reducing faction is developing more drought-resistant crops.
This route's rise is fundamentally determined by hardware vendors' DNA and the rigid demand for end-device deployment. For tech manufacturing giants like Xiaomi, the future battleground lies not in distant data centers but in billions of end devices like smartphones, cars, and AIoT products. In the cloud, you can stack GPUs indefinitely to force breakthroughs; but on end devices, smartphone battery capacity has physical limits, memory bandwidth is precious, and chip cooling space is at a premium.
Under these harsh physical constraints, end devices cannot sustain massive, unrestrained token consumption. Even if cloud tokens drop to zero, reliance on cloud computing still faces network latency, privacy leaks, and device power consumption issues. Thus, the consumption-reducing faction must solve the problem at its root: drastically reduce computational resource consumption while maintaining or even improving response quality.
In technical implementation, this is an extremely challenging architectural optimization battle. The consumption-reducing faction doesn't just compress or distill models but reconstructs AI's underlying operational framework. For example, by improving attention mechanisms, introducing linear-complexity state space models like Mamba, or optimizing key-value cache management strategies, models no longer consume memory exponentially when processing long texts. More efficient Tokenizer designs also enable models to express greater information density with fewer tokens.
For hardware giants like Xiaomi, reducing token consumption directly determines their core business model's success. An AI smartphone with an end-device large model that drains battery or occupies too much RAM, causing system lag, would be catastrophic for user experience. Thus, the consumption-reducing faction's ultimate goal is to transform large models into low-power, high-efficiency foundational components seamlessly integrated into the operating system's bottom layer. They care less about the cost of a single cloud API call and more about minimizing AI inference power consumption per use, enabling even mid-to-low-end hardware to run powerful intelligence smoothly. This is a classic product manager-meets-hardware-engineer mindset, using extreme engineering optimization to combat the computing power black hole.
03
Converging Commercial Strategies
As the price-cutting and consumption-reducing factions race ahead on their respective tracks, we must recognize that this is not a zero-sum game but an inevitable division of labor and commercial differentiation as the AI supply chain matures. The clash between these two routes is essentially a collision of two distinct business models in the AI era.
The price-cutting faction represents the utilities logic. Whether it's the AI Six Little Dragons continuously probing API price floors or Taalas attempting to reshape computing costs through disruptive chips, they aim to turn AI computing power into social infrastructure. In their vision, computing power should be like electricity—users needn't care how generators work, just plug in and pay as needed. This logic's moat lies in network effects and extremely high switching costs. Once massive enterprise applications and consumer apps are built on their cheap, efficient APIs, ecological inertia will make it extremely difficult for latecomers to disrupt. But the risks are equally enormous: before true oligopoly monopolization, prolonged bloodletting and price wars could bankrupt any star company with even slightly fragile capital chains.
The consumption-reducing faction represents the consumer electronics and experience logic. Led by end-device giants like Xiaomi, they don't need to profit by selling APIs. They make money by selling more smartphones, cars, and smart home devices with superior AI experiences. In their business closed loop, excellent, low-consumption AI models are high-end added value for hardware products. The consumption-reducing faction's moat lies in closed-loop experiences integrating software and hardware and closer user-scene occupation. When computing power is efficiently compressed locally on devices, they control users' most private data and direct interaction gateways—barriers cloud-based large models cannot easily penetrate.
Projecting the endgame, these two routes will likely converge into cloud-end collaboration. In future AI application scenarios, general complex tasks requiring heavy computation and massive knowledge retrieval will be handled by the cheap cloud supercomputing centers built by the price-cutting faction, devouring cheap tokens. Meanwhile, personalized tasks involving personal privacy, requiring ultra-low-latency responses, and combining environmental perception will be processed by the ultimately optimized low-power end-device models of the consumption-reducing faction.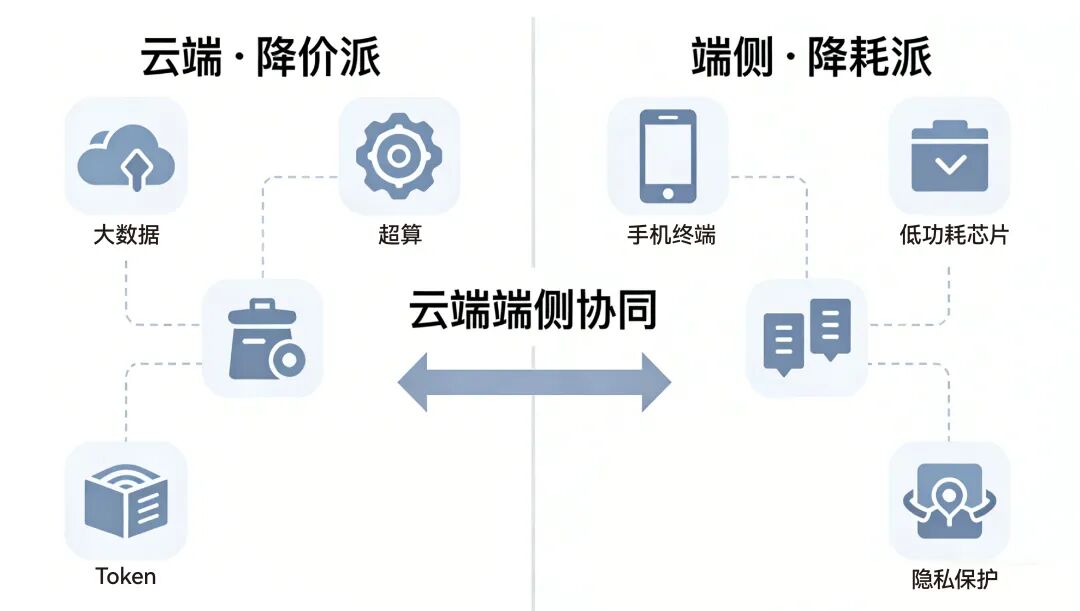
Figure/AI-generated
However, before this convergence arrives, the strategic dispute will remain fierce because resources are limited, and capital is picky. Should one bet on superplatforms that can burn their way to a future through crazy price cuts, or favor ecological giants that steadily improve hardware margins through technical consumption reduction? This is not just a question for investors but a strategic choice all AI practitioners must face.
History repeats itself in surprising ways. Today's divide in the large model field resembles the cloud server vs. local chip efficiency battle during the PC era and the traffic subsidy vs. hardware experience dispute in smartphones' early days.
Some exchange losses for tomorrow, using price-cutting blades to carve out markets; others refine foundations with technology, building barriers through consumption-reducing internal skills. "Bringing token prices down" and "reducing token consumption" ultimately aim to make AI truly accessible to the masses.
But the business world is cruel. When capital recedes and large models' computing power dividends are exhausted, which route will build deeper, more solid moats? The cake-expanding price-cutting faction or the architecture-refining consumption-reducing faction?
References: Luo Fuli X, 11:13 Apr 5, 2026, TMTPost APP, "How Legitimate is 'Heretical' AI Chipmaker Taalas?" 21st Century Business Herald, "2025: Are 'Large Model Price Wars' No Longer Afraid of Losses?" National Business Daily, "Doubao Drives Traffic to Douyin, Kimi Connects with JD and Taobao: Large Models Ignite Smart Entry Point Battles"
- The end -
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?