What on earth is a 'World Model'? OpenWorldLib settles it once and for all: Perception + Interaction + Memory—that's what defines an AI capable of understanding the world!
 04/09 2026
04/09 2026
 674
674
Interpretation: The Future of AI-Generated Content
Key Highlights
Standardized Definition: Addressing the ambiguity in the academic definition of 'world models,' this paper proposes a clear definition: a model or framework centered on perception, equipped with interaction and long-term memory capabilities, designed to understand and predict complex worlds.
Unified Reasoning Framework: Developed OpenWorldLib, integrating various tasks such as interactive video generation, 3D generation, multimodal reasoning, and Visual-Language-Action (VLA) under a unified engineering implementation.
Systematic Classification of Capabilities: Systematically comb, sort out, organize, arrange, streamline (Note: ' comb, sort out, organize, arrange, streamline ' is translated as 'organized' in context) the core capabilities that world models should possess and clearly delineates which tasks (such as pure text-to-video) should not be classified as genuine world model research.
Problems Addressed
Currently, despite the fervor in world model research, two core pain points persist:
Inconsistent Definitions: Researchers lack consensus on the boundaries of world models, leading to many generative tasks (such as Sora) being mistakenly regarded as complete world simulators.
Fragmented Engineering: Different types of world model tasks (perception, prediction, action) often employ entirely distinct underlying architectures and reasoning processes, making collaborative work difficult.
Proposed Solution and Applied Technologies
This work proposes the OpenWorldLib framework, whose core design includes the following five functional modules and a scheduling center:
Operator (Operator Module): Responsible for standardized preprocessing and validation of multimodal inputs.
Synthesis (Synthesis Module): Covers the generation of visual (video/image), audio, and physical signals (such as VLA control instructions), enabling implicit representation of the model.
Reasoning (Reasoning Module): Includes general multimodal reasoning, spatial reasoning, and audio reasoning, allowing the model to understand complex physical laws.
Representation (Representation Module): Supports 3D reconstruction and simulation environment interfaces, providing explicit structural information about the physical world.
Memory (Memory Module): Manages long-term interaction history, supporting context retrieval, compression, and state updates.
Pipeline: Acts as the top-level scheduling entry, coordinating modules to complete single or multi-round streaming interaction tasks.
Achieved Results
OpenWorldLib successfully standardizes the invocation of various cutting-edge models, including Cosmos, Hunyuan, VGGT, and others, achieving efficient collaborative reasoning in tasks such as interactive video generation, 3D scene reconstruction, complex spatial reasoning, and embodied intelligence (VLA).

Background and Related Work
World models are typically defined by three core conditional probability distributions:
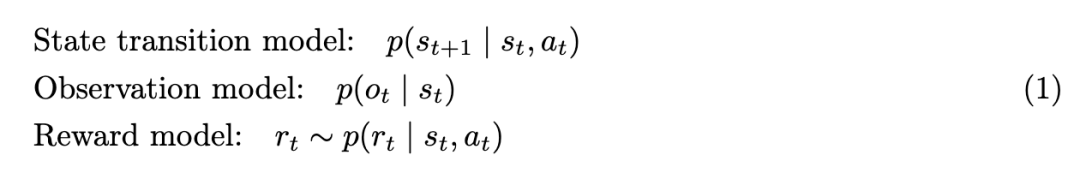
Here, represents the latent state, which essentially integrates memory storage to manage long-range dependencies in complex tasks; represents the action at time , drawn from an action space that has been broadened to encompass diverse operations and task-specific outputs (such as generation and manipulation); is the perceptual observation (e.g., visual, audio, or proprioceptive); and is the reward obtained through interaction with the environment via actions.
Although these formulas are widely used, many tasks formally satisfy such conditional probability distributions yet do not truly serve the core purpose of world models. These tasks are often conflated with world model research or loosely labeled as such. Therefore, in this section, this work, combining definitions proposed by predecessors with the perspectives advocated herein, clearly delineates which tasks fall within the scope of genuine world model research and which do not.
Tasks Related to World Models
Interactive Video Generation. Next-frame prediction is regarded by world model researchers as the most recognized paradigm, establishing interactive video generation as the primary focus of research in this field. Early methods primarily relied on regression-based models to predict subsequent frames. Recently, the field has shifted toward utilizing diffusion models to achieve higher-quality interactive video generation, with unified multimodal approaches further enhancing the fidelity and controllability of generation. With the accelerated inference speed of diffusion models, game video generation and camera-controlled video generation have become particularly notable areas. Additionally, the video prediction paradigm has been successfully integrated into Visual-Language-Action (VLA) models and autonomous driving systems. By introducing next-frame prediction estimation, the stability and robustness of these models' predictive capabilities have been significantly enhanced. However, while interactive video generation remains the cornerstone of current world model research, it is worth noting that next-frame prediction is not the only viable paradigm. Considering the ultimate goal of world models is to facilitate long-term interaction in complex environments, exploring alternative or complementary representation paradigms is equally crucial.
Multimodal Reasoning. The key capability of world models lies in their profound understanding of the complex physical world; therefore, multimodal reasoning is a critical manifestation of world model capabilities. Multimodal reasoning tasks closely related to world models encompass not only spatial reasoning and all-around reasoning but also temporal reasoning and causal reasoning. Recently, in addition to traditional explicit reasoning methods, utilizing implicit reasoning to analyze complex dynamics in the real world has become a significant research hotspot. By breaking away from the traditional text-centric pretraining paradigm of Large Language Models (LLMs), implicit reasoning mechanisms enable models to more effectively ingest and process the complex, high-dimensional, and continuous information inherent in the real world.
Visual-Language-Action. The ultimate goal of world models is to enable agents to interact with the physical world, with embodied devices serving as the primary representatives for interaction with complex environments. Therefore, Visual-Language-Action (VLA) has become a key capability that world models must support. In the field of robotic arm manipulation, recent research mainly follows two paths: utilizing Multimodal Large Language Models (MLLMs) to directly predict actions or combining action prediction with video generation to aid action planning through future frame prediction. Furthermore, this VLA paradigm is being widely applied to more complex embodied scenarios, including mobile robots with extremely complex and difficult-to-control dynamics, as well as autonomous driving systems operating in vast environments, thereby advancing the models' closed-loop interaction capabilities in the real world.
The Role of 3D and Simulators in World Models
Beyond tasks directly reliant on observable perception, a crucial part of world models involves handling virtual environments. To ensure consistency in physical space over long-term interactions, researchers often use simulators to enable models to learn in a structured manner. While interactive video generation creates visual guesses about the future, 3D representations provide a verifiable environment that strictly adheres to physical rules.
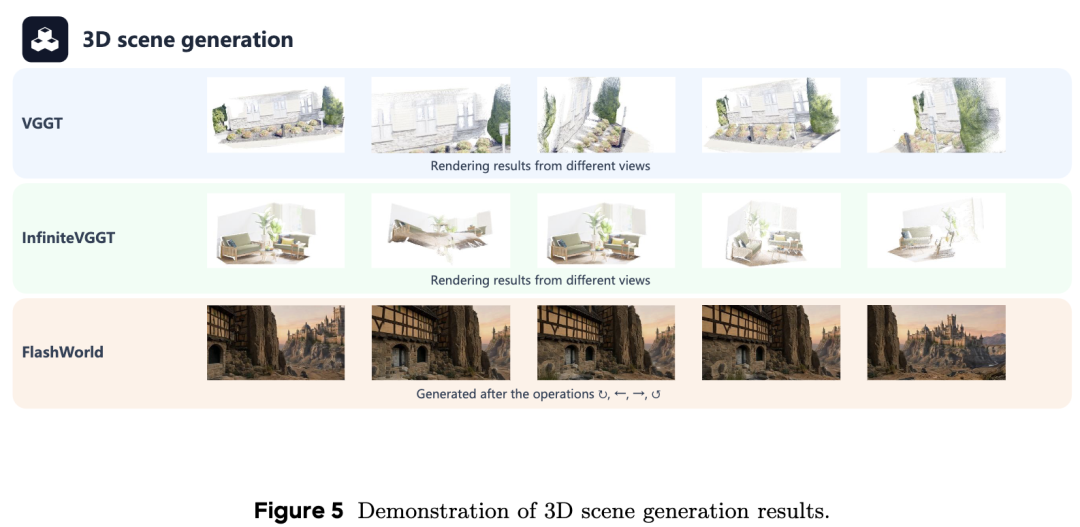
In this context, 3D generation and reconstruction are vital for maintaining a stable world state. Recent works such as VGGT, InfiniteVGGT, and OmniVGGT use vision-geometry-guided Transformers to link image inputs with real geometric structures. To handle continuous data from the real world, some models now maintain persistent 3D states or utilize hybrid memory for long-context reconstruction, ensuring the environment remains consistent even as the agent moves. Additionally, new approaches in metric 3D reconstruction, depth estimation, and wide-angle view synthesis allow world models to recover accurate physical spaces from any camera angle. By learning permutation-equivariant visual geometry, these models can better function in different types of physical settings.
Furthermore, simulators act as 'sandboxes' for world models, helping them transition from abstract thinking to real physical actions. To enable these simulators to work in real time, rapid scene generation is necessary. For example, FlashWorld and the Hunyuan series can create high-quality 3D scenes or assets in extremely short times, providing world models with an immediate venue to test their ideas. Recent investigations have also explored the potential for reinforcement learning during these 3D generation processes. By using these explicit 3D representations and simulation tools, world models can transcend merely predicting pixels and truly understand the physical laws of the real world.
Approaches Not Considered World Models
Apart from tasks related to world models, certain applications, while not truly reflecting world model capabilities, frequently appear in similar discussions. Based on this paper's formulas and specific definitions of world models, this section clarifies which tasks do not fall into this category.
A prominent example of misconception is text-to-video generation. When Sora was released, many labeled it as a 'world simulator.' However, some argue that Sora does not constitute a complete world simulator. Although next-frame prediction is often associated with world models, this paper's definition emphasizes that the key lies not in the output format but in whether the model utilizes multimodal inputs to analyze and identify the environment. Next-frame prediction is merely a format. What truly matters is whether the model accurately understands complex physical laws and interacts with the world. Text-to-video generation lacks such complex perceptual inputs. Although generated videos demonstrate a certain understanding of physics, they remain outside the core tasks of world models.
Similarly, some tasks, such as code generation or web search, borrow the long-term interaction structure of world models for other domains. However, these tasks typically lack multimodal inputs and do not involve understanding the physical world. While applying this structure to new domains presents interesting opportunities, these tasks do not meet the genuine world model criteria.
Even some applications that actually involve multimodality and long-term interaction, such as avatar video generation, may not necessarily fit the definition. These tasks primarily focus on entertainment and, as they have little to do with exploring or understanding the complex physical world, do not represent the main concerns of world models.
OpenWorldLib Framework Design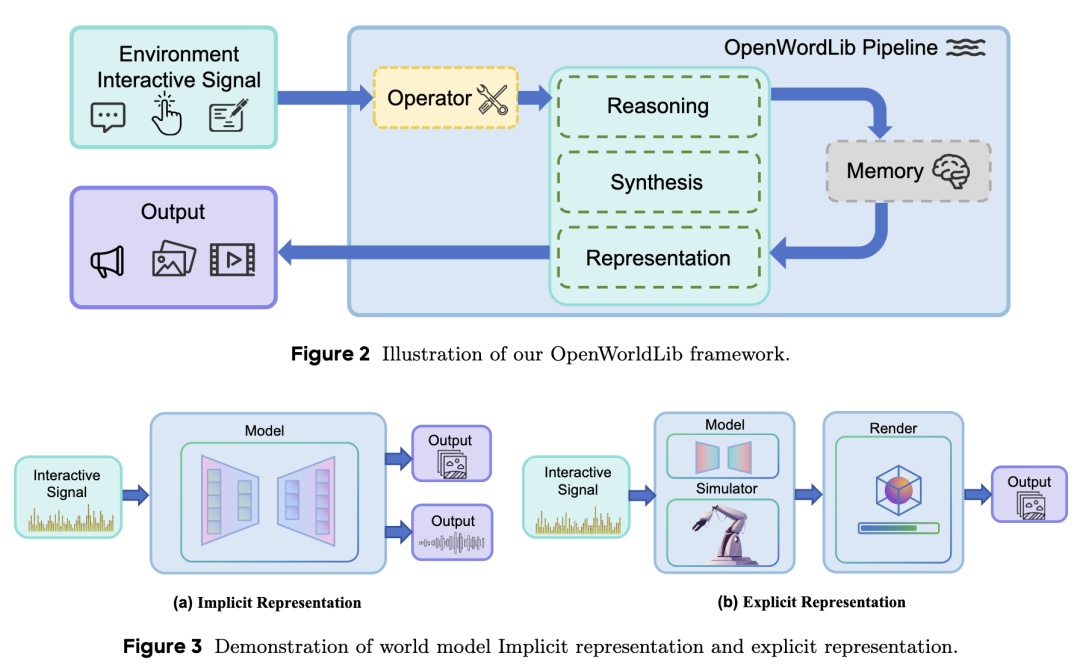
Based on the aforementioned, world models need to possess the following capabilities: receiving inputs from the complex physical world, understanding the physical world, maintaining long-term memory during interactions, and supporting multimodal outputs. Although previous research has proposed designs for unified world model frameworks, they lack concrete engineering implementations or even unified standards. This section details the specific design of the OpenWorldLib framework, as shown in Figure 2.
Operator (Operator Module)
In the OpenWorldLib framework, the Operator module serves as a critical bridge between raw user inputs (or environmental signals) and the core execution modules (Synthesis, Reasoning, and Representation). Since world models must handle complex, multimodal inputs from the physical world—such as text prompts, images, continuous control actions, and audio signals—the Operator aims to standardize these diverse input streams.
Specifically, when the Pipeline is invoked, it routes the raw inputs through the Operator's process() method. The Operator is responsible for two main functions:
Validation: Ensuring that the format, shape, and type of the input data meet the requirements of downstream models.
Preprocessing: Converting raw signals into standardized tensor representations or structured formats (e.g., resizing images, tokenizing text, or normalizing action spaces).
To facilitate the integration of new world model methods, this paper defines a unified Operator template. All task-specific operators inherit from this base class, ensuring a unified API across the entire codebase. The Operator's definition is shown in Listing 1.

Synthesis Module
As shown in the implicit representation section of Figure 3, a core capability of world models is to generate visual, auditory, and other sensory outcomes through environmental feedback, utilizing internally learned dynamics. This paper defines such implicit generation processes as the model's implicit representations. In the OpenWorldLib framework, the Synthesis module serves as a generative bridge between the standardized conditions of the upstream pipeline and the multimodal outputs (visual, auditory, and embodied actions) actually consumed by users, simulators, or robotic stacks. Since world models must realize predictions not only as internal states but also as observable media and executable instructions, the Synthesis module hosts heterogeneous generative backends while maintaining a consistent integration pattern across modalities.
Specifically, when the Pipeline runs a generation path, it passes operator-aligned inputs to the corresponding synthesis backend, which performs reasoning under the control of a specific modality and returns structured artifacts along with concise metadata for export, evaluation, or memory. The following subsections elaborate on the visual, audio, and other physical signal synthesis branches of this module.
Visual Synthesis
The visual synthesis layer covers image and video generation within OpenWorldLib: it transforms structured conditions (such as text prompts, reference images, or scene-level specifications) into raster outputs (frame tensors, decoded clips, or API-returned assets), accompanied by metadata. In this way, the framework can provide intuitive predictions of how scenes evolve over time, which is crucial for interactive simulations, qualitative inspections, and side-by-side comparisons of alternative futures or camera paths.
In practice, the visual synthesis layer is organized around the following responsibilities:
Generation Stack Composition: Combining text encoders, implicit decoders, and cores based on diffusion or flow matching with schedulers or solvers suitable for each task, and exposing adjustment knobs for spatial resolution, time range (frame budget), and guidance-type parameters. Integrated Interface: Supporting checkpoint-driven pipelines (built uniformly from pretrained resources and gradient-free inference) as well as hosted service wrappers authenticated via endpoints and credentials, enabling local and remote generators to share the same conceptual calling pattern. Audio Synthesis
Audio Synthesis Layer
focuses on generating continuous waveforms under structured conditions. Its role is to provide the auditory side of multimodal outputs, enabling scenarios not limited to silent videos or text-only feedback. This is crucial for perceiving rich environments and judging alignment between sound and vision.
Specifically, the Audio Synthesis Layer fulfills the following roles:
Resource Assembly: Instantiates neural audio generators and any auxiliary modules through a single factory-style entry point, with explicit device and reproducibility settings.
Conditional Waveform Synthesis: Maps operator-prepared tensors and prompts to audio outputs via a unified inference entry point.
Other Signal Synthesis
Beyond visual and audio modalities, comprehensive interaction with the environment requires the world model to generate diverse physical signals. Among these, action control proves extremely critical. OpenWorldLib thus emphasizes visual-language-action (VLA) signal generation within this module. Tailored for embodied tasks, this synthesis layer achieves the following functions:
Policy Initialization and Spatial Alignment: Loads specialized physical policies from pre-trained weights, mapping diverse action representations into a unified interface compatible with target simulators or robotic hardware.
Context-Conditioned Action Synthesis: Transforms rich multimodal contexts (e.g., real-time visual streams, textual goals, and proprioceptive history) into grounded physical instructions.


Reasoning Module
As seen in the implicit representation section of Figure 3, world models must transcend mere perception to understand the physical world: inferring spatial relationships, integrating multimodal contexts, and generating grounded semantic interpretations before any downstream generation or action occurs. To this end, OpenWorldLib introduces a dedicated Reasoning module. Specifically, the Reasoning module is organized into three subclasses:
General Reasoning: Multimodal large language models (MLLMs) capable of processing text, images, audio, and video in a unified manner.
Spatial Reasoning: Models specialized in 3D spatial understanding and object localization from visual observations.
Audio Reasoning: Models that interpret and reason over auditory signals.
To facilitate the integration of new reasoning-oriented world model approaches, a unified BaseReasoning template is defined. All task-specific reasoning classes inherit from this base class, ensuring API consistency across the codebase. The definition of BaseReasoning is shown in Listing 3.

Representation Module
Beyond models leveraging internal capabilities to understand the world, some approaches aim to construct artificially defined simulators, such as 3D meshes. These simulators provide a testable environment for world model frameworks. Since these structured representations differ from perceptual data directly collectable from the world, this paper separately designs a Representation module to handle these explicit representations. Its main functions include:
3D Reconstruction: Transforms input data into explicit 3D outputs, such as point clouds, depth maps, and camera poses.
Simulation Support: Creates a manual environment where world models can test their reasoning and verify whether their predicted actions are correct in the coordinate system.
Service Integration: Supports local inference and cloud-based APIs to help export these explicit representations to external physics engines.
To standardize the usage of these models, we provide a unified BaseRepresentation template. All task-specific representation classes inherit from this base class to ensure consistent APIs. The definition of BaseRepresentation is shown in Listing 4.

Memory Module
Long-term contextual memory is essential for interactive world models to maintain historical observations, reasoning chains, and interaction states. OpenWorldLib designs a unified Memory module to manage multimodal interaction histories. It fulfills the following functions:
Historical Storage: Stores text, visual features, action trajectories, and scene states across interactions.
Contextual Retrieval: Selects relevant history to support consistent reasoning and generation.
State Updating: Records new interaction results after each pipeline execution.
Session Management: Supports independent memory for different tasks and sessions.
To unify memory management, a unified BaseMemory template is defined. All task-specific memory classes inherit from this base class. The definition of BaseMemory is shown in Listing 5.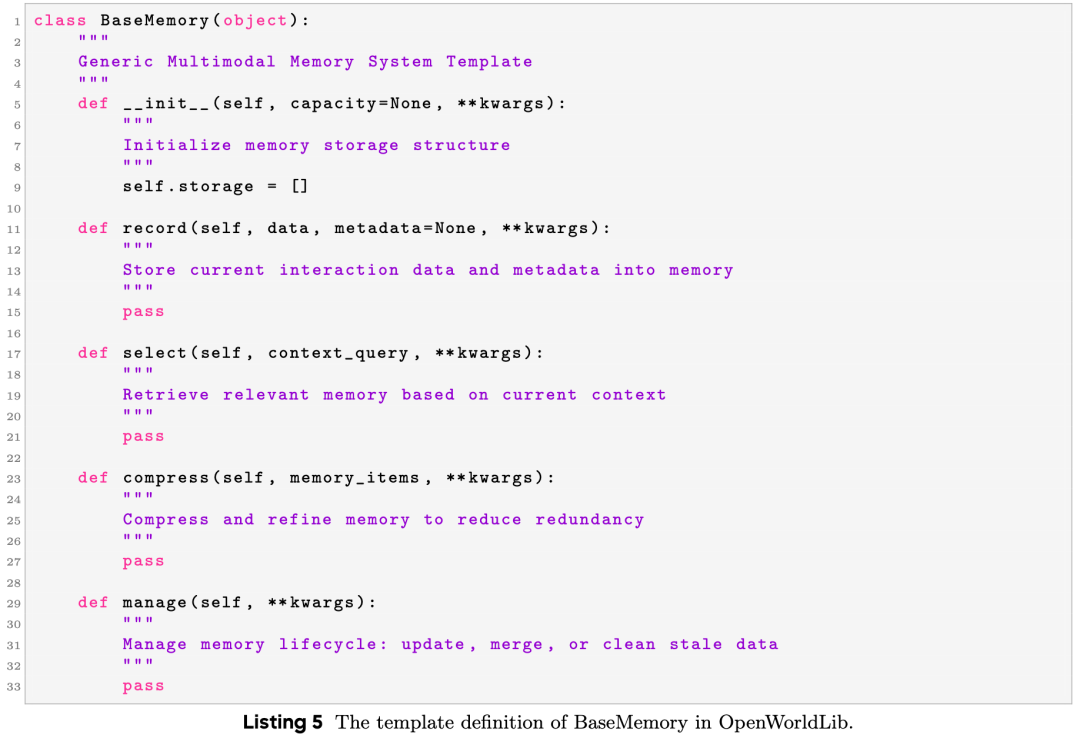
Pipeline
To integrate the aforementioned modules into a cohesive and usable system, OpenWorldLib provides a unified Pipeline module as the top-level scheduling and execution entry point. The Pipeline encapsulates model initialization, data flow, module invocation, memory interaction, and result post-processing, enabling end-to-end world model inference through a simple and consistent API.
The Pipeline follows a standard forward execution flow: it receives raw inputs, routes them to the Operator for validation and preprocessing, queries historical context from Memory, coordinates Reasoning, Synthesis, and Representation for core computations, and finally returns structured outputs while updating memory. The core responsibilities of the Pipeline include:
Unified Model Initialization: Loads all submodules through a single interface.
End-to-End Inference: Implements one-click forward inference for single-round world model tasks.
Multi-Round Interactive Execution: Supports stateful continuous interactions via a stream() method with automatic memory read/write.
Modular Orchestration: Dynamically invokes modules based on task types without modifying internal logic.
Result Structuring: Organizes outputs into standardized formats for visualization, evaluation, logging, or downstream control systems.
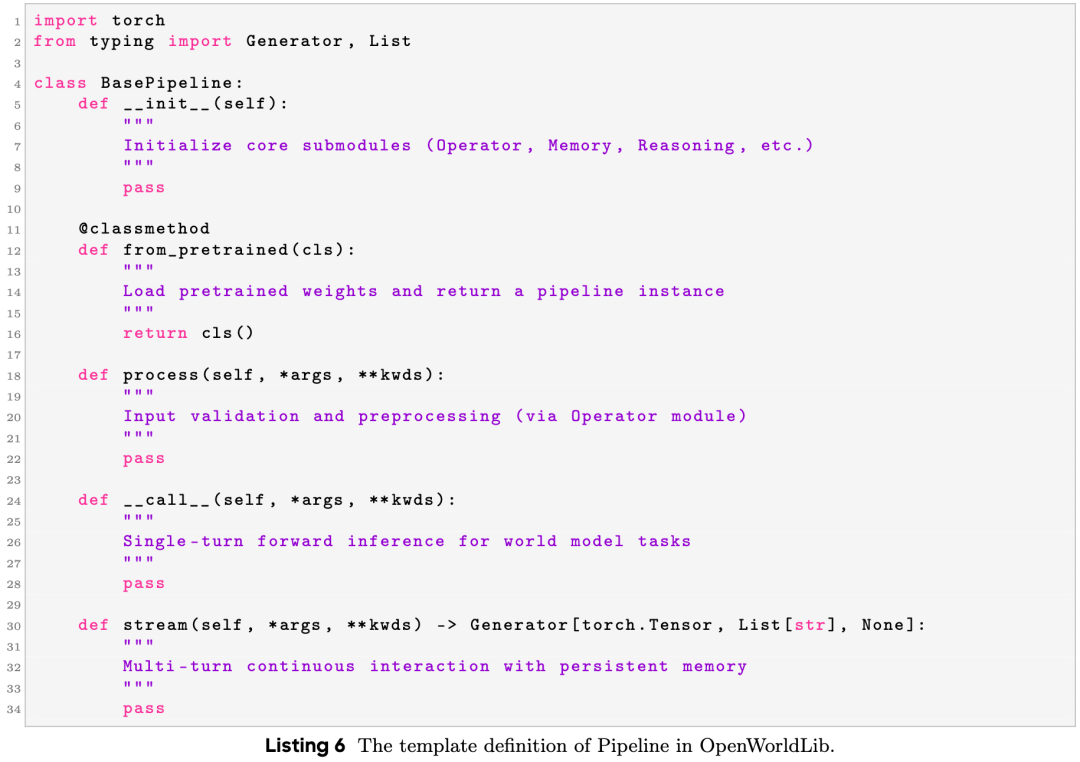
To maintain consistency across the framework, all task-specific pipelines inherit from a unified BasePipeline template. Its definition is shown in Listing 6.
Discussion
OpenWorldLib aims to provide a clearer and more standardized definition and framework for world models. Its goal is to facilitate the development of world models, enabling AI to better assist humans in complex environments. In this section, this paper discusses future development directions for world models.
Many current world model architectures focus on next-frame prediction. This approach aligns with how humans process high-density sensory inputs, as humans are essentially "pre-trained" in the physical world, while large models are pre-trained on massive internet text corpora. However, based on existing architectures, visual language models (VLMs) may offer a tangible solution. For example, Bagel successfully leveraged the Qwen architecture to achieve multimodal reasoning and multimodal generation. This demonstrates that large language models (LLMs) pre-trained on internet data can possess all the capabilities required by world models, showcasing their potential as foundational backbones. Therefore, before fully focusing on the specific structural design of world models, we should first consider how to achieve all their necessary functionalities for real and effective interaction with complex worlds. Additionally, since LLMs serve as the foundational pillars of world models, data-centric methodologies—including multimodal data synthesis, domain-specific data augmentation, dynamic training, and training data quality assessment—will play an increasingly important role in reinforcing the backbone models that support world model capabilities.
In real-world interactions, next-frame prediction retains more information compared to next-token prediction, but its efficiency needs significant improvement. This efficiency enhancement must begin at the hardware level. Current computer byte organization is inherently conducive to next-token prediction. Even when models attempt next-frame prediction, data is still processed as tokens during actual computation. To achieve ideal world models, we need hardware iterations, changes in backbone model structures (token-based Transformers may need to evolve), and comprehensive implementation of complex physical world interaction tasks.
Experimental Summary
This paper conducted extensive testing on NVIDIA A800 and H200 GPUs:
Interactive Video Generation: Compared models such as Matrix-Game-2, Hunyuan, and Cosmos. Experiments demonstrated that Cosmos has significant advantages in physical realism and complex interaction operations.
Multimodal Reasoning: Evaluated models' ability to process image, video, and audio evidence and generate reliable conclusions.
3D Generation: Tested models like VGGT for reconstruction effects from different viewpoints, noting that maintaining geometric consistency during large-scale camera movements remains a challenge.
VLA Evaluation: Verified embodied agents' action planning capabilities using AI2-THOR and LIBERO simulation environments.

Conclusion
OpenWorldLib provides a standardized workflow and evaluation pipeline for world models. By offering unified interfaces, it successfully integrates multimodal perceptual inputs and diverse interaction controls. This work hopes that the framework can serve as a practical reference for the research community, promoting fair comparisons and future explorations in the field of world models.
References
[1] OpenWorldLib: A Unified Codebase and Definition of Advanced World Models.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?