Xiaomi Open Sources Its First 7B Inference AI Large Model! Let's Talk About How Xiaomi Innovates Through Architecture and Reward Model Training Strategies to Rival o1-mini
 05/06 2025
05/06 2025
 1022
1022
Full text is about 4200 words, estimated reading time is 12 minutes
Yesterday, Alibaba Tongyi released two MoE models and six Dense models. Even its smaller model, Qwen3-4B, still delivers impressive performance in mathematical reasoning and programming.
However, just this morning, the newly formed "Xiaomi Large Model Core Team" suddenly open sourced four MiMo-7B series models (including the base model, instruction-tuned model, and two reinforcement learning models). With only 7 billion parameters, these "lightweight" models challenge traditional concepts and demonstrate reasoning abilities comparable to or even surpassing larger models.
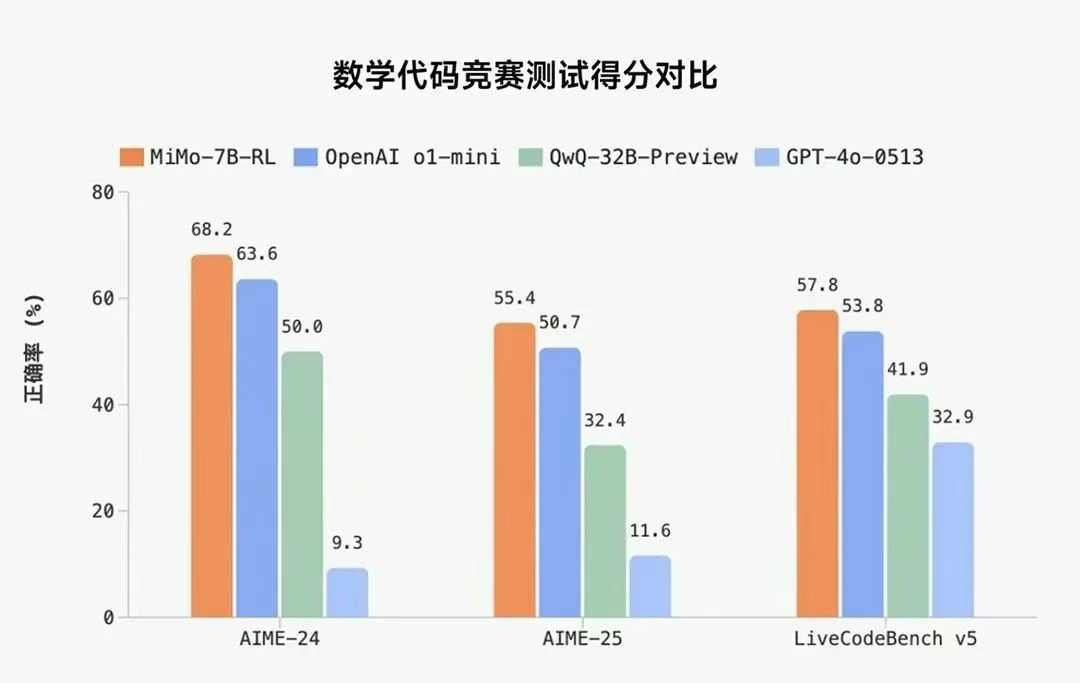
This model not only lays a solid foundation through unique data strategies during the pre-training phase but also unleashes astonishing potential through innovative reinforcement learning (RL) methods during the post-training phase, ultimately outperforming powerful competitors like OpenAI's o1-mini in math, code, and general inference tasks.
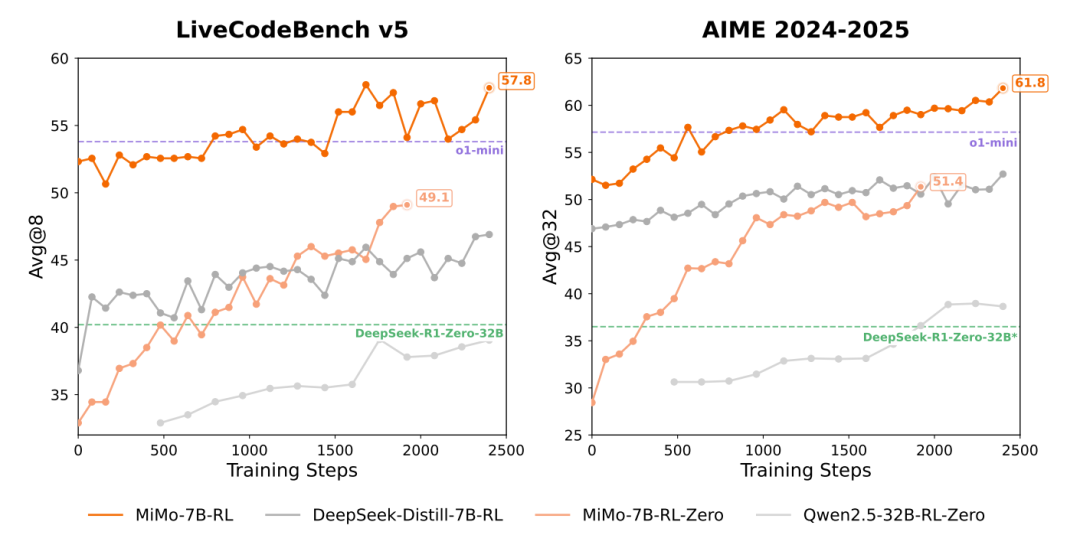
The birth of MiMo-7B not only brings valuable resources to the open source community but also provides a brand new approach for developing efficient inference models. This article will take you deep into the innovations of MiMo-7B, revealing its experimental methods and impressive results, and exploring how this small model achieves "overtaking" speed in the inference race. If you are interested in the reasoning abilities of language models or curious about how to achieve stronger performance with fewer resources, the story of MiMo-7B is definitely worth reading!
Innovations: Comprehensive Optimization from Pre-training to Post-training
The core charm of MiMo-7B lies in its fully optimized design across the entire pipeline, covering both pre-training and post-training phases. Instead of simply stacking parameters or relying on large-scale computing power, the team has delicately designed every aspect from data, architecture to training strategies, striving to maximize the model's reasoning potential at each stage.
Pre-training Phase
During the pre-training phase, the MiMo-7B team deeply recognized that high-quality reasoning data is the key to unlocking the model's potential. To this end, they optimized the data preprocessing pipeline and developed an HTML extraction tool specifically for mathematical content and code snippets from webpages, solving the problem of traditional extractors missing key reasoning patterns. For example, formulas from math blogs and code snippets from programming tutorials are fully preserved, significantly enhancing the reasoning density of the data. They also adopted an enhanced PDF parsing tool to obtain STEM and code-related content from papers and books.
In addition, the team utilized advanced reasoning models to generate diverse synthetic reasoning data, which exhibited strong robustness during high-round training, avoiding the risk of overfitting.
To further optimize the data distribution, MiMo-7B adopted a three-stage data mixing strategy:
The first stage balances various types of data; the second stage significantly increases the proportion of math and code data to about 70%; the third stage introduces 10% of synthetic reasoning data and extends the context length to 32,768 tokens.
Ultimately, the model completed pre-training on a massive dataset of about 25 trillion tokens, laying a solid foundation for subsequent inference tasks.
Another important innovation is the introduction of the Multi-Token Prediction (MTP) module. Traditional autoregressive generation methods are often inefficient in reasoning tasks due to excessively long generated sequences. MiMo-7B, through the MTP module, allows the model to predict multiple tokens at once, thereby significantly accelerating the inference process. During pre-training, the team used a single MTP layer to maintain training efficiency, while during the inference phase, speculative decoding was achieved by replicating and fine-tuning multiple MTP layers. In the AIME24 benchmark test, the acceptance rate of the first MTP layer reached 90%, and the third layer remained above 75%. This design not only improves the reasoning speed but also ensures the generation quality, providing efficient support for complex reasoning tasks.
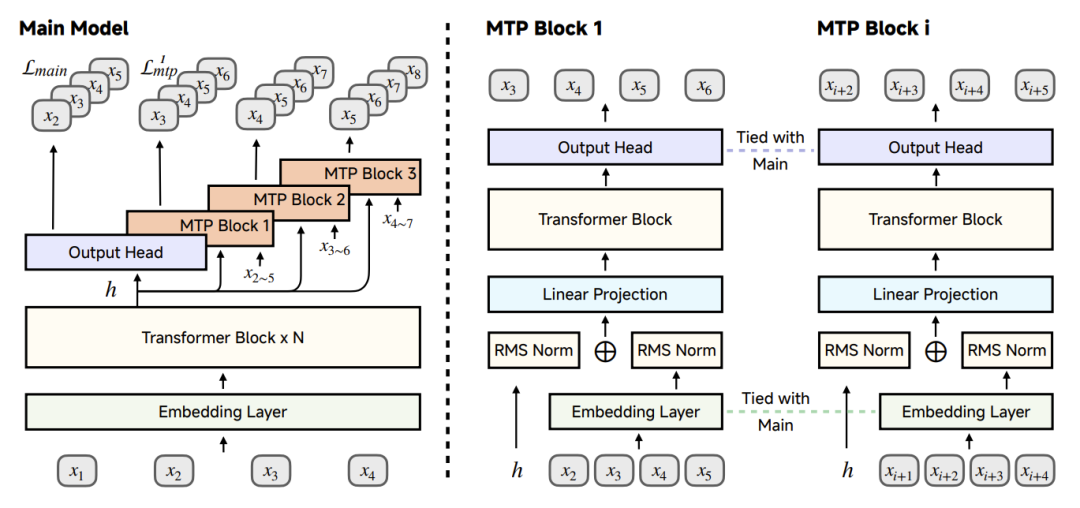
Figure 3: The architecture diagram of the MTP module in MiMo-7B. During pre-training, a single MTP layer is used, while during the inference phase, multiple MTP layers can be used for additional acceleration. Source: Technical Report
Post-training Phase
During the post-training phase, MiMo-7B further unleashed the model's reasoning potential through reinforcement learning.
The team meticulously constructed an RL dataset containing 130,000 verifiable math and code problems and ensured the reliability of rewards through a rule-based validator. To address the issue of sparse rewards in code tasks, they proposed a difficulty-driven code reward mechanism inspired by the scoring rules of the International Olympiad in Informatics (IOI). This mechanism grades test cases by difficulty, allowing the model to obtain rewards by passing partial test cases, thus effectively optimizing training efficiency. Additionally, the team developed a "Seamless Rollout Engine," which utilizes techniques such as continuous rollback, asynchronous reward calculation, and early termination to improve training speed by 2.29 times and validation speed by 1.96 times. These innovations collectively ensure the exceptional performance of MiMo-7B-RL in reasoning tasks.
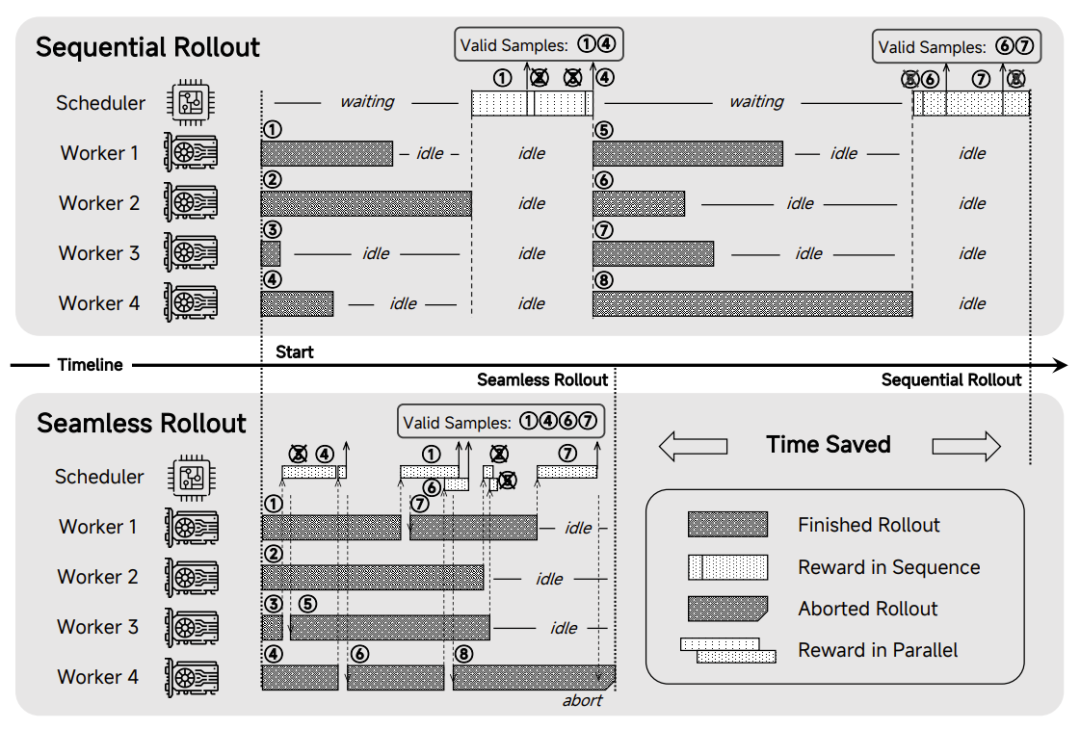
Figure 4: Overview of the "Seamless Rollout Engine". Source: Technical Report
It is worth mentioning that the MiMo-7B series models have been fully open sourced, including the base model, supervised fine-tuning (SFT) model, and two RL models. Open source address:

Experimental Methods
The success of MiMo-7B is inseparable from its scientific and rigorous experimental methods, from data preparation to reward model design to evaluation processes, each step reflecting the team's deep understanding of reasoning tasks.
Dataset and Preprocessing
The pre-training dataset is the cornerstone of MiMo-7B. The team integrated various sources such as webpages, academic papers, books, programming code, and synthetic data, totaling about 25 trillion tokens. To improve data quality, they optimized text extraction tools, especially enhancing them for mathematical formulas and code snippets to ensure that these high-value contents are not missed. At the same time, fast global deduplication techniques and multi-dimensional data filtering were employed to eliminate low-quality content and upsample high-quality data in specialized fields. The introduction of synthetic reasoning data further enriched the dataset, and the team ensured data diversity and reasoning depth by prompting advanced reasoning models to generate in-depth analyses and problem solutions.
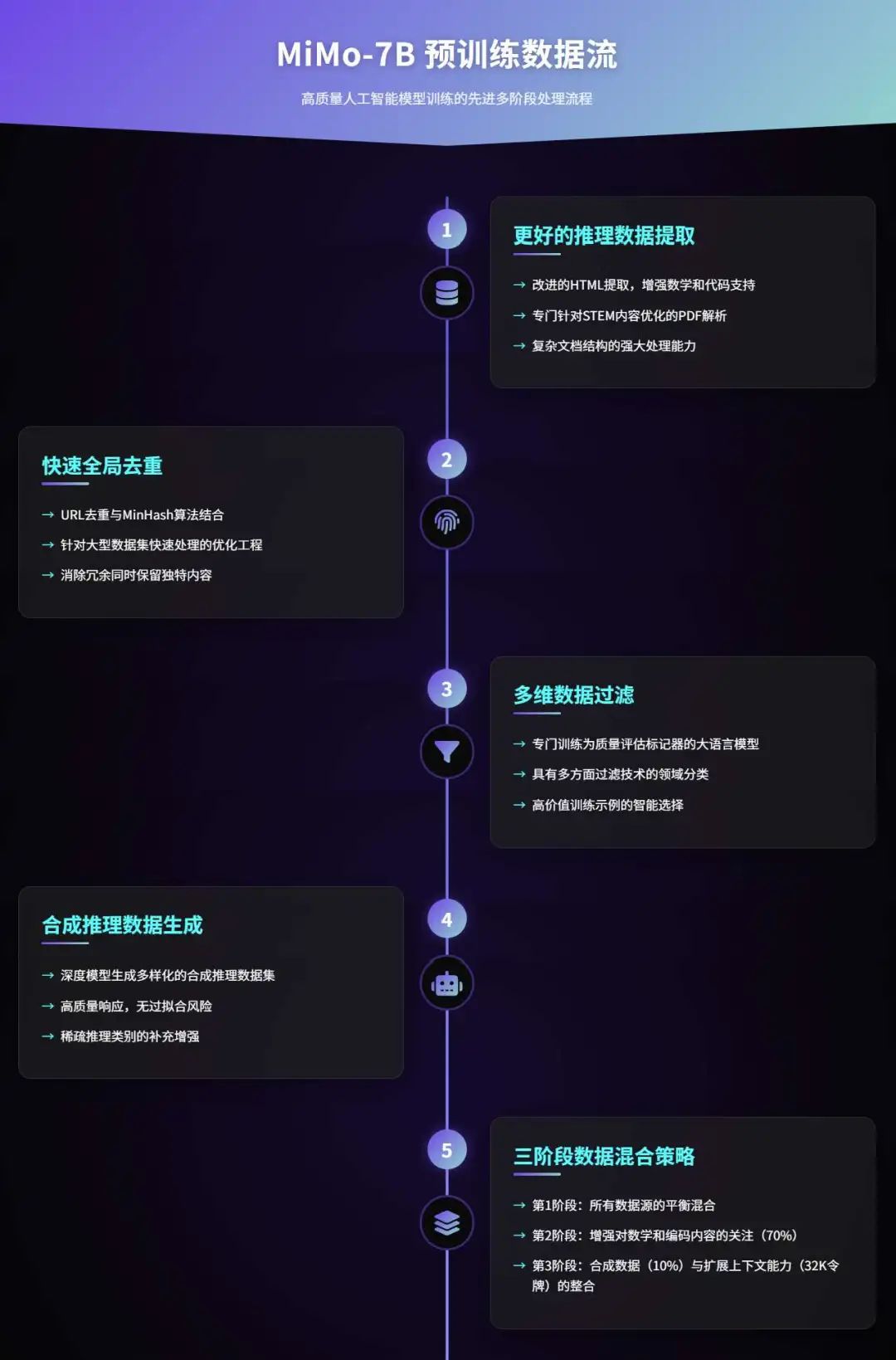
Source: Ji Zhi Liu
During the post-training phase, the RL dataset consisted of 100,000 math problems and 30,000 code problems. Math problems were sourced from open-source datasets and competition-level private collections, rigorously deduplicated and decontaminated, and filtered by model difficulty assessment to remove overly difficult or easy problems. Code problems were similarly rigorously screened to ensure that each problem had reliable test cases. This data selection strategy provided high-quality material for RL training.
Reward Model Settings
MiMo-7B's RL training adopted an improved Group Relative Policy Optimization (GRPO) algorithm and incorporated a series of innovative optimizations.
The design of the reward function was particularly crucial:
Math tasks used the rule-based Math-Verify library for accuracy assessment; while code tasks introduced a difficulty-driven reward mechanism.
Currently, for code generation tasks, existing reinforcement learning work (such as Deepseek-R1) adopts a rule-based reward strategy, where the solution only receives a reward if the generated code passes all test cases for a given problem. However, for difficult algorithm problems, the model may never receive any rewards, preventing it from learning from these challenging cases and reducing the training efficiency of dynamic sampling.
In contrast, the "difficulty-driven reward" mechanism adopted by MiMo-7B grades test cases by pass rate, with strict and soft reward schemes:
The strict reward requires the model to pass all low-difficulty test cases to obtain high-difficulty rewards; while the soft reward distributes the score evenly to each passed test case.
This design effectively alleviates the issue of sparse rewards for complex code tasks and enhances the model's learning efficiency.
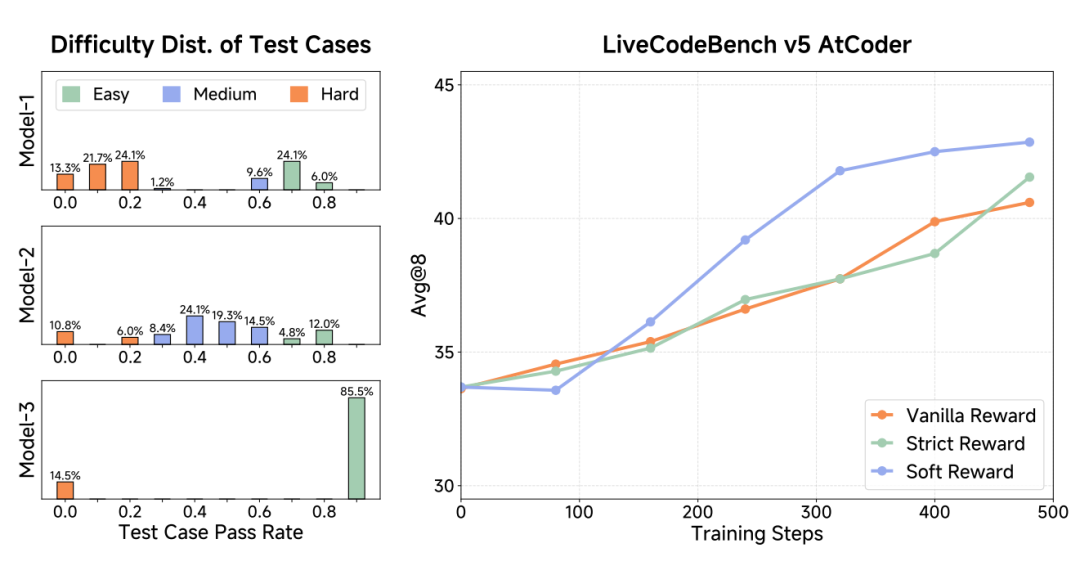
Figure 7: Experiments related to the "difficulty-driven reward mechanism". The left figure shows the pass rate and difficulty grading of test cases. The right figure compares the performance of different reward schemes, where "Vanilla Reward" is the traditional reward mechanism that only gives rewards when the generated code passes all test cases; "Strict Reward" and "Soft Reward" are strict and soft difficulty-driven rewards, respectively; experimental results show that Soft Reward helps the model learn faster on complex problems.
To further optimize the training process, the team proposed dynamic sampling and an easy data resampling strategy. Dynamic sampling maintains effective gradients in the batch by filtering out samples that pass perfectly or fail completely; easy data resampling stabilizes later-stage training strategy updates by maintaining a pool of easy data and sampling from it with a 10% probability. These strategies collectively ensure the efficiency and stability of RL training.
Experimental Scenarios and Evaluation Methods
MiMo-7B's evaluation covers a wide range of reasoning tasks, including language understanding, science question answering, reading comprehension, mathematical reasoning, and code generation. Specific benchmarks include BBH, MMLU, AIME, LiveCodeBench, etc., covering various scenarios from general knowledge to specialized fields. During the evaluation process, the team adopted the pass@k metric to assess the model's reasoning ability boundaries through multiple sampling, ensuring that the results truly reflect the model's potential.
In post-training evaluations, MiMo-7B-RL was compared with multiple strong baseline models, including GPT-4o, Claude-3.5-Sonnet, OpenAI o1-mini, etc. Sampling parameters were set to a temperature of 0.6, top-p of 0.95, and the maximum generation length was set to 8,192 or 32,768 tokens based on task requirements. This setting not only ensures the diversity of generated content but also adapts to the needs of long-sequence reasoning tasks.
Experimental Results: Great Achievements from a Small Model
The experimental results of MiMo-7B are exhilarating, demonstrating far-exceeding performance on both the base model (MiMo-7B-Base) and the RL-optimized model (MiMo-7B-RL).
Reasoning Potential of the Base Model
MiMo-7B-Base exhibited strong reasoning abilities during the pre-training phase. On the BBH benchmark, it achieved a score of 75.2, surpassing Qwen2.5-7B of the same scale by about 5 percentage points. On SuperGPQA, the model performed exceptionally well in handling graduate-level problems, demonstrating its potential in complex reasoning tasks. In long-context understanding tasks, MiMo-7B-Base achieved nearly perfect retrieval performance on the needle-in-a-haystack task of the RULER benchmark, while also significantly outperforming Qwen2.5-7B in tasks requiring long-context reasoning, such as common word extraction and variable tracking.
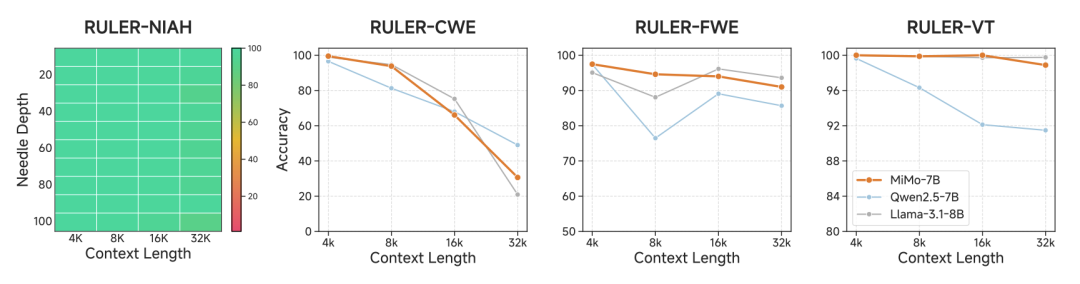
Figure 8: Performance of MiMo-7B-Base in RULER long-context understanding tasks. This figure shows the nearly perfect retrieval performance of MiMo-7B-Base in the needle-in-a-haystack task, as well as its excellent performance in long-context reasoning tasks such as common word extraction (CWE), frequent word extraction (FWE), and variable tracking (VT).
In math and code tasks, MiMo-7B-Base also stood out. On AIME 2024, it achieved a score of 32.9, far surpassing Llama-3.1-8B and Qwen2.5-7B; on LiveCodeBench v5, it again scored 32.9, significantly ahead. These results indicate that MiMo-7B-Base already possessed reasoning potential surpassing models of the same scale during the pre-training phase, providing a high-quality starting point for subsequent RL training.
Stunning performance after RL optimization
Through reinforcement learning, MiMo-7B-RL has pushed reasoning abilities to new heights. On math tasks, MiMo-7B-RL achieved an impressive score of 95.8 on MATH500 and 55.4 on AIME 2025, surpassing OpenAI o1-mini by approximately 4.7 percentage points. On code generation tasks, MiMo-7B-RL's performance was particularly impressive: on LiveCodeBench v5, it significantly led o1-mini with a score of 57.8; on the newer LiveCodeBench v6, it scored 49.3, exceeding QwQ-32B-Preview by over 10 percentage points, demonstrating its robustness and leading edge in algorithmic code generation.
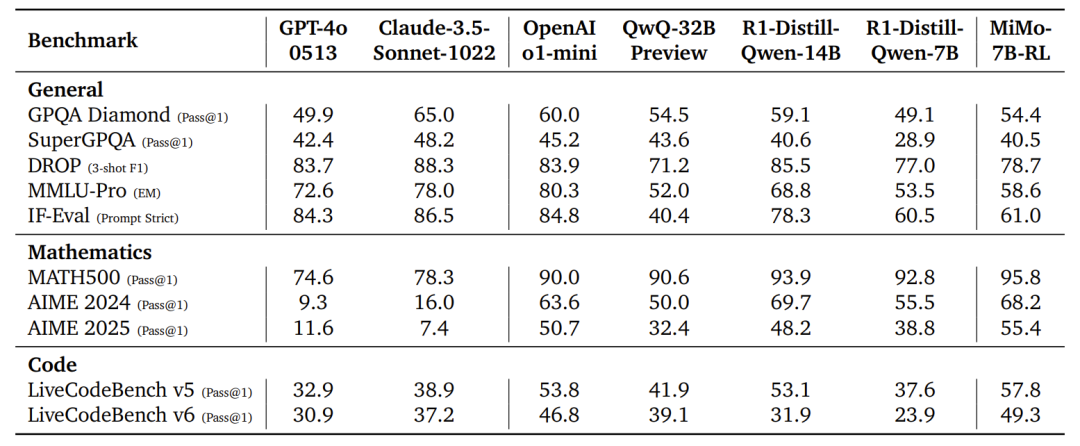
Table 1: Comparison of MiMo-7B and other mainstream models
Notably, MiMo-7B-RL remains competitive on general tasks. Despite RL training being optimized specifically for math and code tasks, the model's performance on general benchmarks such as MMLU-Pro and GPQA Diamond still surpassed QwQ-32B-Preview and DeepSeek-R1-Distill-Qwen-7B. This indicates that MiMo-7B's optimization strategy not only enhances domain-specific reasoning abilities but also preserves the model's generalizability to a certain extent.
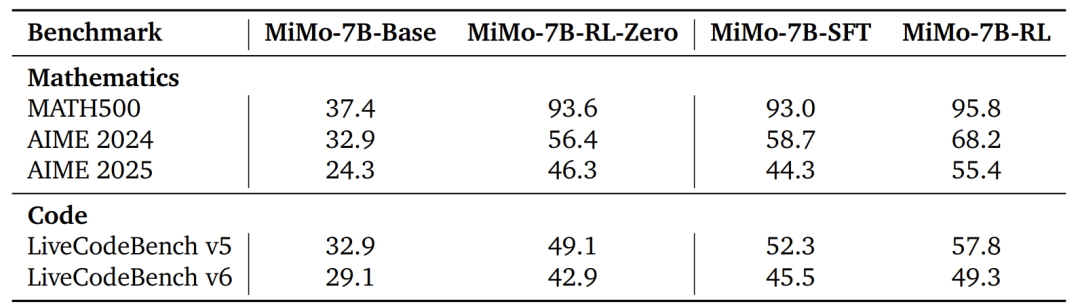
Table 2: Performance of MiMo-7B series models on code and math reasoning benchmarks. This table showcases MiMo-7B's excellent performance on benchmarks like LiveCodeBench and AIME, especially in code generation and math reasoning tasks where MiMo-7B-RL's scores significantly outpace other models, highlighting its powerful reasoning capabilities. Insights from RL training
The team also discovered some interesting phenomena during the RL training process. For example, directly performing RL training from the base model (MiMo-7B-RL-Zero) exhibited a stronger trend of performance growth but slightly underperformed MiMo-7B-RL, which started from the SFT model. This suggests that appropriate SFT can provide a better starting point for RL, but over-reliance on lightweight SFT may limit the model's reasoning potential.
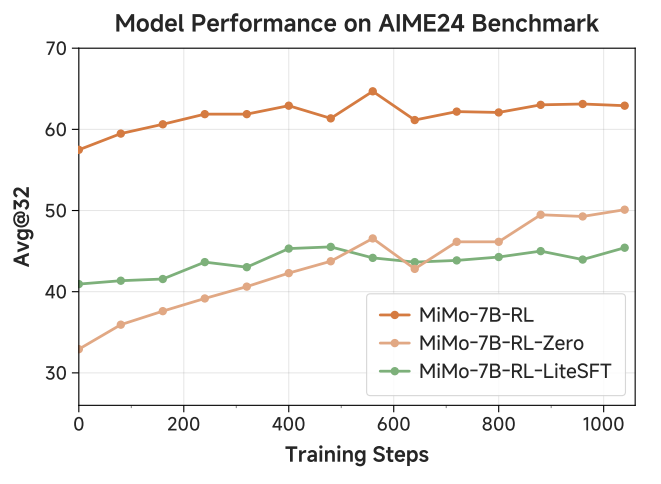
Figure 9: Performance comparison of three MiMo model variants during the RL process.
Furthermore, during the later stages of training, balancing performance between math and code tasks became difficult for the base model. Math tasks were prone to reward hacking issues, while code tasks were more robust due to the strict validation of test cases. This suggests that future RL training needs to pay more attention to the quality of math problem sets.
Why is MiMo-7B worth paying attention to?
MiMo-7B's success lies not only in its outstanding performance but also in pointing a new direction for language model reasoning research. Traditional beliefs held that reasoning abilities require large-scale models, but MiMo-7B, with its "compact" 7 billion parameters, has proven the enormous potential of efficient data strategies and innovative training methods. Its innovations such as three-stage data mixing, MTP modules, and test difficulty-driven rewards provide valuable experience for developing lightweight high-performance models.
More importantly, MiMo-7B's open-source availability has opened a door for researchers and developers. Whether for academic research or industrial applications, MiMo-7B's open-source models and detailed technical reports provide a solid foundation for further exploration. For teams looking to develop powerful reasoning models in resource-constrained environments, MiMo-7B is undoubtedly a model worth emulating.
Conclusion
MiMo-7B's story is an adventure of innovation and efficiency. From pre-training data optimization to post-training RL breakthroughs, Xiaomi's LLM Core team has leveraged scientific methods and clever designs to create a lightweight model that shines in reasoning tasks. Whether it's tackling math problems on AIME or code challenges on LiveCodeBench, MiMo-7B has proven with its surpassing performance that "small models" can achieve "big things".
If you're curious about the future of language models or are looking for an efficient reasoning tool, consider diving deeper into MiMo-7B. Its open-source resources and technical insights may inspire your next project. How do you think MiMo-7B's success will impact future model development? Share your thoughts in the comments!
-- End --
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
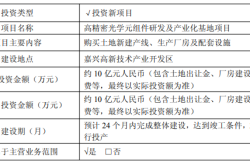
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?