Designing AI Mobile Phones: SoC Architecture, Energy Efficiency, and Communication
 06/09 2025
06/09 2025
 681
681
Produced by Zhineng Zhixin
With the relentless advancement of generative AI, multimodal models, and edge intelligence, smartphones are compelled to bear increasingly heavier computational loads.
To support complex AI models, evolving communication protocols, and enriched human-computer interactions while maintaining low power consumption, chip design faces unprecedented challenges. Heterogeneous computing, dedicated AI processing units, DRAM and storage interface optimizations, and architectures tailored for future flexibility are gradually becoming key features of high-end SoCs.
From the evolution path and technical trends of SoC architecture, we delve into the bottlenecks and breakthroughs faced by mobile AI at the hardware level.

Part 1
AI Reconstruction under Heterogeneous Architecture:
Division of Labor and Collaboration between CPU, GPU, and NPU

In recent years, high-end smartphone SoCs have widely adopted heterogeneous computing architectures. This design philosophy involves not merely stacking processing units but rather precisely allocating various dedicated cores based on the characteristics of each computational task.
In a typical mobile SoC, Arm cores handle system control and basic tasks, GPUs manage graphics and some general-purpose computing, while NPUs (Neural Processing Units) focus on AI inference.
Generative AI, particularly models based on the Transformer architecture, poses significantly higher demands on matrix operation density, memory access patterns, and bandwidth requirements compared to traditional algorithms. For instance, lightweight models like TinyLlama, despite having smaller parameter volumes, necessitate efficient tensor processing capabilities, where NPUs excel.
When confronted with large language models or multimodal models, the complexity of their required activation functions, attention mechanisms, and vector operations far surpasses the original design intent of traditional AI chips, prompting NPUs to continuously scale up and incorporate more programmable features.
GPUs are also evolving towards AI adaptability. Some vendors have introduced more dedicated data type processing units into GPUs, such as FP8 and INT4 for low-bit operations, to enhance energy efficiency.
To further optimize the utilization of graphics units, some architectures have integrated NPU technology into GPU pipelines, realizing a unified vector computing framework.
This trend of "AI-GPU fusion" not only amplifies the dynamic scheduling efficiency of computing resources but also mitigates costs and thermal design pressures stemming from repeated chip area stacking.
The crux lies in the energy efficiency of parallel architectures. At the ALU (Arithmetic Logic Unit) level, various vendors are compressing the energy consumption of each AI inference through finely tuned design of computation engines, dynamic voltage adjustment, and multi-threaded pipeline optimization.
At the application scenario level, tasks such as always-on speech recognition, camera detection, and background object recognition necessitate NPUs to exhibit "milliwatt-level" real-time response capabilities, making energy efficiency indicators not merely a supplement to performance metrics but rather the guiding principle determining the direction of architecture evolution.
Part 2
Memory, Connectivity, and Communication:
The Next Bottleneck for SoCs
As model sizes expand, SoC chips are no longer solely the primary computational arena; memory access paths, data loading latencies, and connection bandwidth have also emerged as crucial bottlenecks constraining AI experiences.
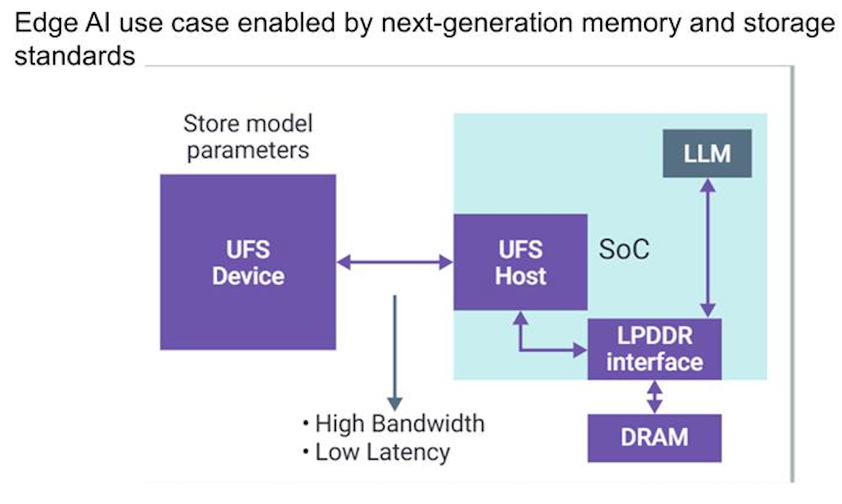
Generative AI heavily relies on large models swiftly retrieving complete contexts from DRAM for reasoning and inference. For example, when deploying LLMs on mobile phones, it is impractical to load all parameters simultaneously; instead, segments are typically read from UFS storage, loaded into DRAM, processed, and then returned to the user. Poorly managed data movement delays can lead to a less seamless experience, even with outstanding AI model performance.
This underscores the importance of UFS controllers and SoC connection paths. The ongoing UFS 4.x specification not only emphasizes throughput speed but also prioritizes fast wake-up mechanisms for low-power read-write states.
In AI model invocations, frequent and intermittent data reads can easily cause storage controllers to frequently wake up, leading to energy wastage. Thus, control strategies lean towards "in-situ computing" and "minimal wake-ups," i.e., caching frequently used model parts in DRAM and accessing flash storage only when necessary, while leveraging local SRAM resources within AI inference engines to avoid full-link activation.
The continuous evolution of communication protocols also presents significant SoC adaptation challenges. Mobile phones integrate communication modules ranging from 5G to Wi-Fi 6E, Bluetooth 5.x, UWB, and Near Field Communication (NFC), each requiring independent RF transceiver links and antenna configurations.
Today, high-end phones house over six built-in antennas, and interference between RF paths, noise coupling, and power management coordination have become system engineering issues that cannot be overlooked in SoC design.
These wireless connections are no longer limited to traditional data transmission functions but are integral to AI decision-making systems. For instance, some multimodal AI systems rely on input from Bluetooth headphones, real-time 5G video streams, and camera images for fused analysis.
Such coordination renders the QoS (Quality of Service) of communication modules directly impactful on AI performance, compelling SoCs to possess the capability to perceive dynamic network conditions and schedule AI processing priorities.
At the interface standard level, organizations like the MIPI Alliance are also driving protocol evolution to cater to AI data transmission scenarios.
The new generation of MIPI interfaces must not only support higher bandwidth but also facilitate direct access to on-chip accelerators, reducing data movement links. For example, the ability to directly feed camera images to NPUs via MIPI interfaces, rather than relaying through CPUs, becomes a pivotal point in evaluating system architecture efficiency.
SoC Evolution Roadmap for the Future of AI
The path towards AI integration in smartphones is no longer a question of "whether to deploy" but rather a challenge of "how to deploy efficiently." SoC vendors confront not only the demand for faster computation but also the design challenge of more flexible, programmable, and self-adaptive system architectures for emerging models.
Future mobile SoCs must embody the following three core characteristics:
◎ Heterogeneous Computing: Clear division of labor among CPU, GPU, and NPU, with collaborative operation through a unified tensor programming interface to accommodate a wide spectrum of tasks, from traditional image AI to multimodal GenAI;
◎ Memory Connection Optimization: Comprehensive adjustments from UFS controllers, DRAM scheduling, to on-chip cache architectures to address the problem of power consumption spikes under high-frequency, low-latency access;
◎ Standard Ecosystem Collaboration: From MIPI to UFS, from AI model standards to compilation toolchains, integrated software and hardware capabilities have become the secondary battlefield for SoC competition.
With the support of software and hardware collaboration, AI is no longer merely a hallmark of high-end flagship devices but is poised to become a standard feature permeating mid-range and even entry-level phones. Achieving maximum performance with minimal power consumption and seamlessly integrating AI into the user experience are pivotal in determining the technological trajectory of the next generation of mobile devices.
Summary
With the maturation of chip design tools, model compilation technologies, and AI inference frameworks, the flexibility and scalability of SoC design will become pivotal drivers of AI evolution. Future chip architectures will not only be tailored for "hardcoded AI" but also for "supporting AI that has yet to be conceived," marking the dawn of a new era of intelligent mobile computing.
-
![]()
OFILM Reports Colossal 460 Million Yuan Loss: Founder Quietly Shifts Focus to Optical Modules!
-
![]()
Yutong Optics and Zeiss Forge Partnership to Develop Quality Measurement System and Launch "Optical Communication Joint Measurement Class"
-
![]()
AutoNavi Revises Splash Screen Ads with Precision Amid Controversy
-
![]()
Unlicensed Vehicle Disputes: AutoNavi Ensnared in the Aggregation Model
-
![]()
Agent: The 'Hard Requirement' for Entering Core Enterprise Systems for the First Time
-
![]()
Global Auto Market Outlook: Sales Decline in China, US, and Europe, Chinese Exports Approach 10 Million
-
![]()
AI Pioneer Breaks Free from the 'Doldrums'
-
![]()
Valuation Exceeds $26 Billion! Three Chinese "Gold Medalists" Shake Up the AI Industry