DeepSeek-V3.1 Chip Ignites Market: Which Domestic Chips Will Join in Achieving 'Autonomy and Controllability' for Large AI Models?
 09/02 2025
09/02 2025
 648
648
DeepSeek has released DeepSeek-V3.1, leveraging the UE8M0 FP8 Scale tailored for the next generation of domestic chips.

On August 21, DeepSeek officially unveiled DeepSeek-V3.1. The key upgrades encompass three main aspects:
1. Hybrid Reasoning Architecture: One model supports both reasoning and non-reasoning modes simultaneously.
2. Higher Reasoning Efficiency: Compared to DeepSeek-R1-0528, DeepSeek-V3.1-Think delivers answers in a shorter timeframe.
3. Enhanced Agent Capabilities: Through Post-Training optimization, the new model significantly improves performance in tool usage and agent tasks.
In an official tweet, DeepSeek highlighted that DeepSeek-V3.1 employs the parameter precision of UE8M0 FP8 Scale, adding in a pinned comment, 'UE8M0 FP8 is designed for the upcoming next generation of domestic chips.'
This news ignited the capital market. According to Eastmoney.com statistics, driven by DeepSeek's new product launch, FP8 concept stocks soared on August 22, with Cambricon, Holtek, and PCI-Suntek all reaching their daily trading limits.

Image source: Eastmoney.com
So, what is FP8 in the realm of large AI models? And what role does the 'UE8M0 FP8' introduced by DeepSeek play? What significance does it hold for domestic AI?
1
What is UE8M0 FP8?
To understand 'UE8M0 FP8', we must first delve into 'FP8'.
'FP' stands for 'Floating-Point'. The core logic of floating-point numbers involves representing numbers using 'binary scientific notation', essentially balancing 'representation range' and 'precision' by 'splitting digits'.
To illustrate this more intuitively, consider the familiar 'decimal scientific notation'. When representing numbers in decimal scientific notation, we fix the format of the 'mantissa' (e.g., retaining 1 integer digit and 3 decimal digits) and adjust the size of the number using an 'exponent', such as:
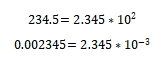
This method splits numbers into two parts:
1. Mantissa: Corresponding to 2.345, this part determines the 'precision' of the number (e.g., the number of decimal places).
2. Exponent: Corresponding to the '2' and '-3' in 10^2 and 10^-3, this part determines the 'range' of the number (how large or small it can be).
The advantage of scientific notation is that with a limited number of digits, it can represent both 'very large numbers' and 'very small numbers', while retaining key precision through the mantissa.
Now, let's look at the '8' in FP8. Here, '8' generally refers to 8 bits, or 8 binary digits (total digits). Similar to FP8, there are also FP64, FP32, FP16, etc. Fewer total digits mean less storage occupancy and faster calculation speed (explored further in the next section).
Combining the above, FP8 essentially uses 8 bits (8 binary digits) to split into 'sign + exponent + mantissa' to balance 'range' and 'precision'.
These 8 bits are divided into three parts:
1. Sign bit (S, 1 bit, optional): Indicates whether the number is positive or negative (0=positive, 1=negative).
2. Exponent bit (E): Determines the 'range' of the number.
3. Mantissa bit (M): Determines the 'precision' of the number.
Therefore, understanding 'UE8M0 FP8' introduced by DeepSeek is now intuitive. Here, 'U' stands for unsigned, meaning no sign bit, possibly limiting the data range to non-negative numbers; 'E8' means the exponent bit is 8; 'M0' means the mantissa bit is 0; 'FP8' means 8-bit floating-point number.
Essentially, UE8M0 FP8 trades 'precision' for an extremely large dynamic 'range'. Simultaneously, subsequent algorithms and hardware designs are necessary to compensate for precision issues.
This is closely tied to DeepSeek's official tweet, suggesting that the next generation of domestic chips may have targeted hardware designs.

Image source: DeepSeek WeChat official account
2
Why Do We Need FP8?
Before supporting FP8, domestic chips commonly used formats such as FP16, BF16, and INT8 (8-bit integer). Here's a brief explanation of why various vendors are turning to FP8.
The differences between formats mainly lie in the allocation of 'total digits', 'exponent bit width', and 'mantissa bit width'. Based on application scenarios, they can be categorized as general-purpose standard formats, AI-specific low-precision formats, and special-scenario formats.
IEEE 754 is a globally standardized floating-point number standard covering most scenarios from consumer electronics to high-performance computing. It balances 'range' and 'precision' through fixed digit allocation, primarily including single-precision, double-precision, and half-precision.

These formats offer excellent standardization compatibility: all mainstream chips support them natively, and the software ecosystem (such as C/C++, Python, CUDA) does not require additional adaptation.
FP32 (single-precision floating-point number, 32 bits) was the default choice for early AI development. Its design of 1 sign bit, 8 exponent bits, and 23 mantissa bits struck a balance between precision (about 7 significant digits) and computational efficiency, supporting the training of classic models like AlexNet and ResNet.
Early GPUs (such as NVIDIA's Kepler architecture) were not optimized for low precision, making FP32 the only viable option. The training of AlexNet in 2012 relied entirely on FP32, consuming about 1.5TB of video memory. This highlights FP32's limitations: high storage and computational costs. As model sizes expand, video memory occupancy and computational power demand increase exponentially.
Fewer total digits mean less storage occupancy, faster calculation speed, and lower precision. For example, FP64 boasts extremely high precision but consumes 2-4 times the computational power of FP32 (NVIDIA A100's FP64 computational power is only 1/4 of FP32).
Against this backdrop, researchers began experimenting with lower-precision formats and mixed-precision training.
FP16 (half-precision floating-point number) halves storage requirements and doubles calculation speed. However, due to its smaller exponent range, gradient overflow is prone to occur, necessitating techniques like dynamic loss scaling (e.g., NVIDIA's AMP).
BF16 (Brain Floating Point 16-bit) is also 16 bits but features an expanded 8-bit exponent and a compressed 7-bit mantissa, providing a dynamic range comparable to FP32. BF16 avoids gradient overflow while maintaining high precision, making it the preferred choice for training large models like GPT-3. NVIDIA's A100, introduced in 2020, natively supported BF16 for the first time, tripling computational power.
Researchers also tried mixed-precision training - retaining FP32 for critical computations (like gradient updates) and using FP16/BF16 for operations like matrix multiplication, balancing efficiency and stability through dynamic precision allocation. INT8 (8-bit integer) has also been explored for inference optimization - compressing weights and activation values to 8-bit integers, increasing calculation speed by 4-8 times and reducing power consumption by over 50%. However, the precision loss caused by uniform quantization needs to be compensated through quantization-aware training (QAT).
In 2022, precision was further explored as NVIDIA's Hopper architecture (H100 GPU) natively supported FP8 for the first time. Its official blog noted that FP8 can double throughput and halve video memory occupancy without significantly sacrificing model performance, a highly attractive advantage for training GPT-level large models. The test chart in the blog more intuitively shows that with the same H100, FP8 is much faster than FP16.
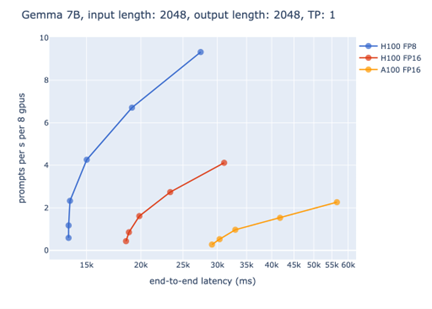
Image source: NVIDIA official blog
This explains why after DeepSeek's tweet, domestic chip manufacturers have followed up to express native support for FP8, triggering market enthusiasm.
3
UE8M0 FP8: Collaboration Between Domestic Model Developers and Chip Manufacturers
As explained in Section 1, the prefix of FP8 represents different 'splitting' methods. So what is special about DeepSeek's introduction of UE8M0 FP8 this time?
Currently, 'mainstream' FP8 typically follows the MXFP8 rules on NVIDIA's Hopper/Blackwell architecture. In practice, 'E4M3' and 'E5M2' are commonly used. Among them, E4M3 is typically applied to forward propagation and activation value calculation (higher precision, smaller range); E5M2 is typically applied to backward propagation and gradient calculation (larger range).
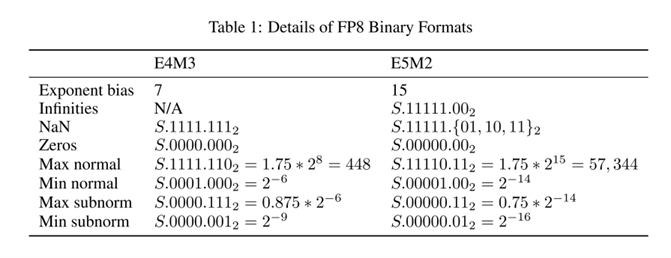
Image source: NVIDIA technical blog - FP8 binary format
Of course, NVIDIA itself also supports UE8M0. DeepSeek's previously open-sourced DeepGEMM used UE8M0 and was optimized for NVIDIA GPUs.

Image source: deepseek-ai/DeepGEMM Github
For DeepSeek's emphasis that 'UE8M0 FP8 is designed for the upcoming next generation of domestic chips', some analysts believe that domestic GPUs cannot fully compatible with NVIDIA's FP8 solution in terms of underlying circuit and instruction set design. NVIDIA has its own 'optimizations', which domestic GPUs do not possess. If directly copied, the result is often numerical instability, gradient explosion, and uncontrollable training.
Using the 'range-priority' format of UE8M0 to adapt to the hardware logic of domestic chips ensures a compromise solution that allows domestic chips to run smoothly. This is a 'mutual achievement' between software and hardware. Model vendors are willing to sacrifice some detailed precision in exchange for the stable operation of domestic chips; chip vendors, through such cooperation, gradually establish their own FP8 ecosystem.
In a Medium report, UE8M0 is described as a 'range-priority' variant that prioritizes dynamic range (exponent) while significantly compressing or even eliminating mantissa precision - this helps stabilize training on non-NVIDIA FP8 implementations, whose numerical behavior differs from NVIDIA's Blackwell/Hopper pipelines. The report emphasizes that this shift is more about compatibility with domestic chips.
The Register, a renowned UK tech media outlet, also pointed out that DeepSeek is already familiar with FP8 and positions UE8M0 as a compatibility fulcrum - reducing memory and increasing throughput, with the key benefit being numerical stability on non-NVIDIA instruction sets.
As the United States continues to escalate export restrictions on Chinese AI chips and related technologies, industry analysts point out that UE8M0 FP8 is evidence of enhanced co-design between model developers and chip manufacturers. This is crucial for achieving AI self-sufficiency amid restrictions on the export of NVIDIA's high-end GPUs. Hardware and software co-design reduces the resistance to migration on non-NVIDIA architectures and accelerates time-to-market - important conditions for expanding national AI infrastructure under supply constraints.
4
Final Thoughts
Since February this year, the China Academy of Information and Communications Technology (CAICT) has actively conducted DeepSeek adaptation testing. As of July 2025, over 30 enterprises in key links of the AI hardware and software industry chain, including chips, servers, all-in-one machines, framework software, and cloud service providers, have participated in the evaluation. The first batch of adaptation test pass list announced in July included 8 enterprises.
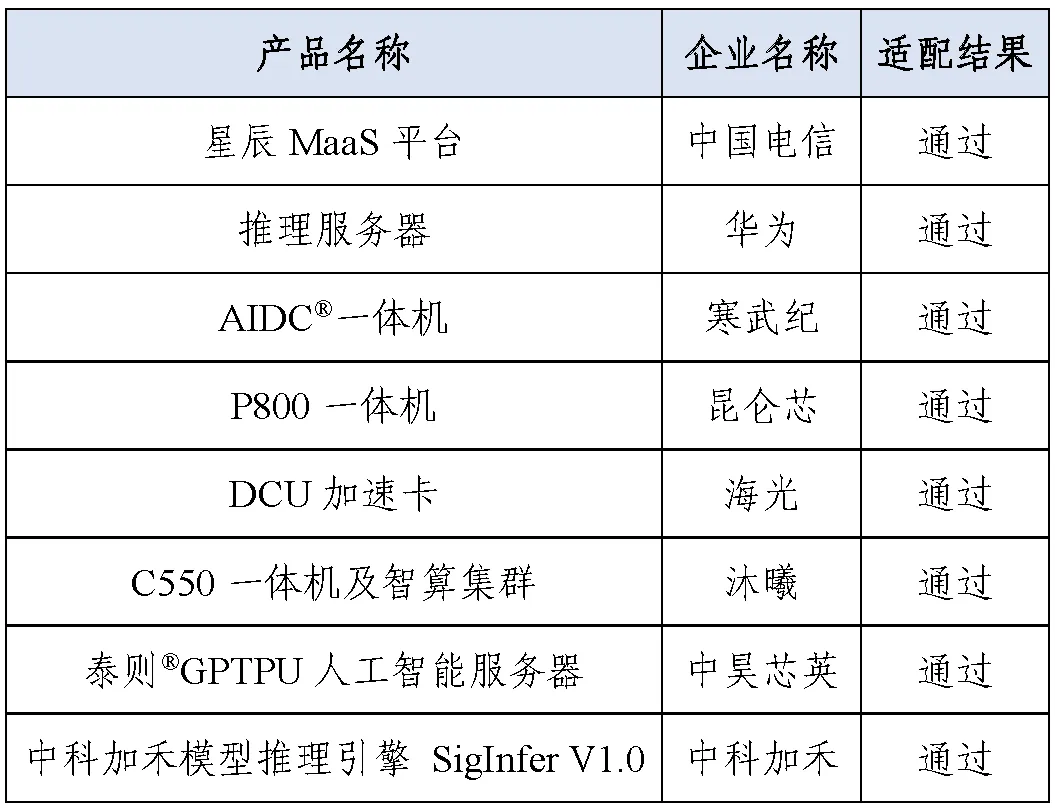
Image source: CAICT WeChat official account
According to the test results of CAICT:
1. In terms of adaptation support, through hardware and software co-optimization, the accuracy of DeepSeek models deployed on tested products in typical tasks like language understanding and logical reasoning is comparable to foreign systems (comparing official technical reports).
2. In terms of deployment environment, China has systems capable of performing single-machine 8-card inference of the full-blooded DeepSeek 671B model (INT8/FP8 precision), on par with the hardware scale required by NVIDIA. Most domestic devices require two machines with 16 cards or four machines with 32 cards to deploy models with the same number of parameters.
3. In terms of product form, key entities in the industrial chain, such as hardware chips, framework platforms, and cloud services, are actively promoting adaptation work. Domestic vendors can complete basic adaptation without errors on hardware and software systems in a short period. Currently, the focus of adaptation is mainly on product functionality and performance optimization for business scenarios.
However, on June 24th of this year, NVIDIA officially launched NVFP4 on its official blog. On August 25th, it posted another article stating that NVFP4 can achieve 16-bit training accuracy while maintaining 4-bit training speed and efficiency. As an industry leader, NVIDIA has taken another significant step forward.
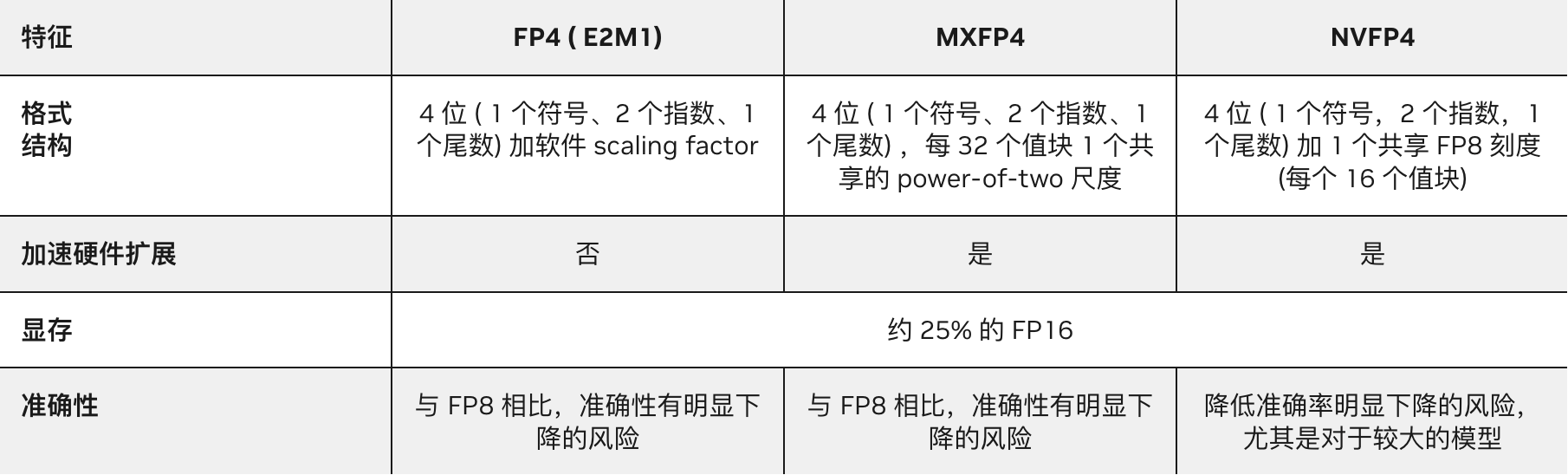
Source: NVIDIA Official Blog
Domestic model and chip manufacturers still have a long way to go in catching up. But at least, they are already on the right path.
-
![]()
OFILM Reports Colossal 460 Million Yuan Loss: Founder Quietly Shifts Focus to Optical Modules!
-
![]()
Yutong Optics and Zeiss Forge Partnership to Develop Quality Measurement System and Launch "Optical Communication Joint Measurement Class"
-
![]()
AutoNavi Revises Splash Screen Ads with Precision Amid Controversy
-
![]()
Unlicensed Vehicle Disputes: AutoNavi Ensnared in the Aggregation Model
-
![]()
Agent: The 'Hard Requirement' for Entering Core Enterprise Systems for the First Time
-
![]()
Global Auto Market Outlook: Sales Decline in China, US, and Europe, Chinese Exports Approach 10 Million
-
![]()
AI Pioneer Breaks Free from the 'Doldrums'
-
![]()
Valuation Exceeds $26 Billion! Three Chinese "Gold Medalists" Shake Up the AI Industry