Technical Analysis | Performance of Arm C1 Cluster: AI Processing Capability of Smart Devices Significantly Enhanced!
 09/17 2025
09/17 2025
 631
631
Produced by Zhineng Zhixin
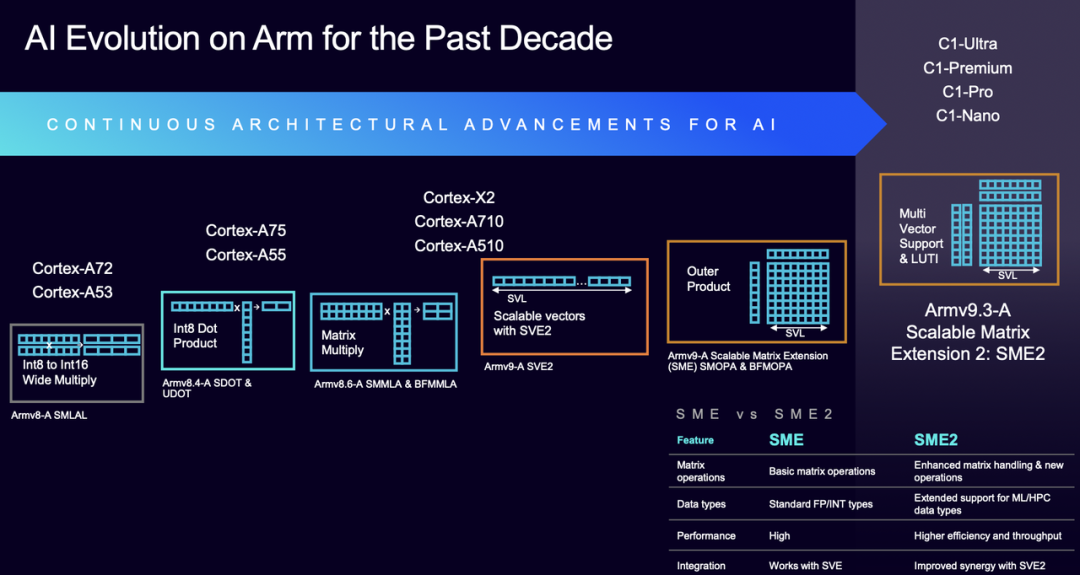
A New Computing Engine for the AI Era: As smartphones, tablets, and wearable devices become increasingly 'intelligent,' the evolution of CPU architecture has become a focal point in the industry. At Arm's technology day, detailed insights into the Arm C1 CPU were shared.
In 2025, Arm launched the C1 CPU cluster based on the latest Armv9.3 architecture, delivering significant improvements in single-thread performance. With the new matrix expansion (SME2), AI task processing capabilities have soared, covering a wide range of devices from flagship smartphones to smartwatches.
The C1 cluster consists of four core types—Ultra, Premium, Pro, and Nano—plus a shared unit (DSU), offering flexible adaptation to various scenarios.

Part 1
Core Design: A Versatile Player from Flagship to Entry-Level
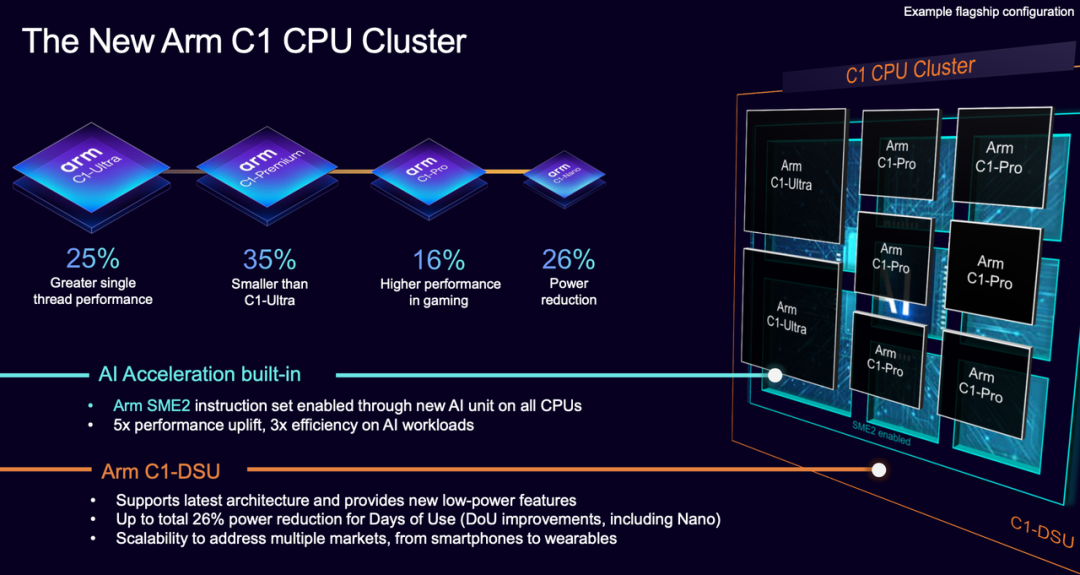
The charm of the C1 cluster lies in its 'modular' design—not a single processor but a flexible combination of four core types and a shared unit. This design allows chip manufacturers to freely mix and match according to device needs, finding optimal solutions from high-end flagships to low-power smartwatches.
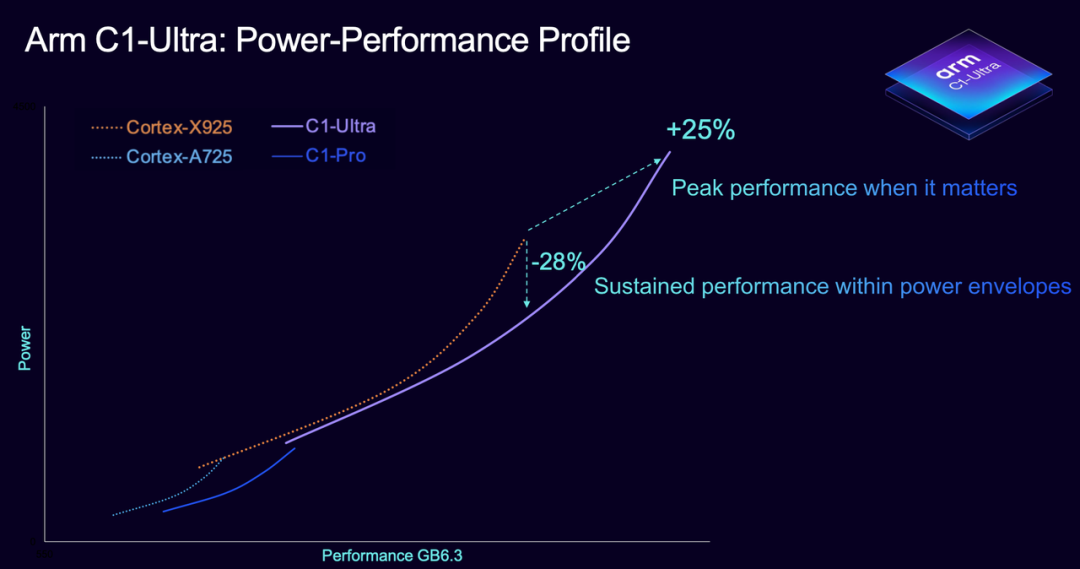
C1-Ultra: The Performance Champion
The C1-Ultra is designed for flagship devices. Compared to the previous generation Cortex-X925, single-thread performance has increased by 25%, thanks to a wider instruction pipeline, smarter out-of-order execution, and upgraded prefetching technology. Whether running large games or processing complex AI models, the Ultra maintains smooth performance without slowing down.
It also fully supports the SME2 matrix instruction set for the first time, significantly boosting AI inference speeds. For example, tasks like speech recognition and image processing are nearly five times faster.
However, the Ultra prioritizes extreme performance, with a larger chip area and higher power consumption, making it ideal for the 'performance leader' in flagship smartphones.
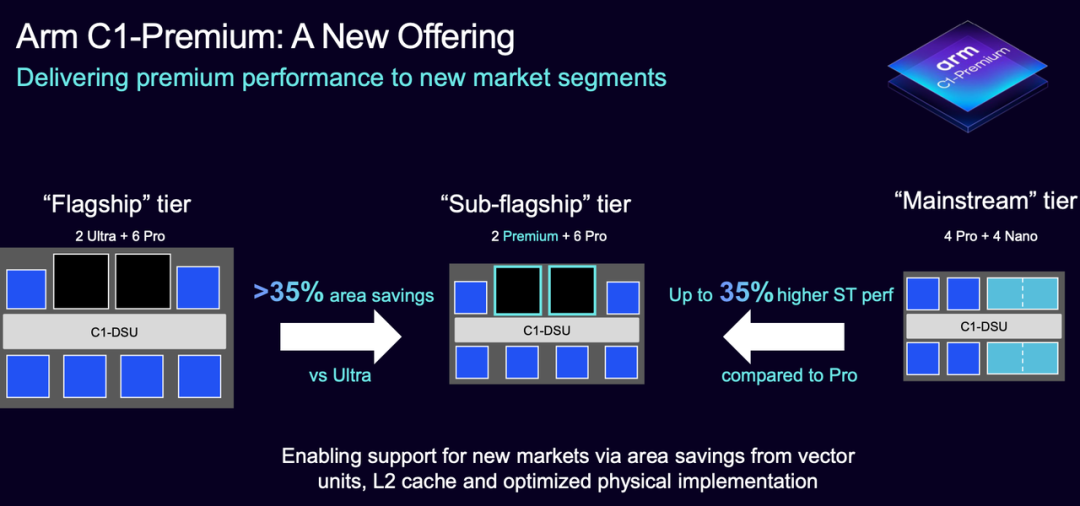
C1-Premium: The Cost-Effective Flagship Choice
The Premium core is positioned slightly lower but offers performance close to the Ultra while reducing the chip area by 35% through streamlined cache and vector units for cost control.
This makes it an ideal choice for near-flagship devices, such as configurations with '2 Premium + 6 Pro,' which excel in AI tasks and multimedia processing while lowering chip manufacturing costs and power consumption.
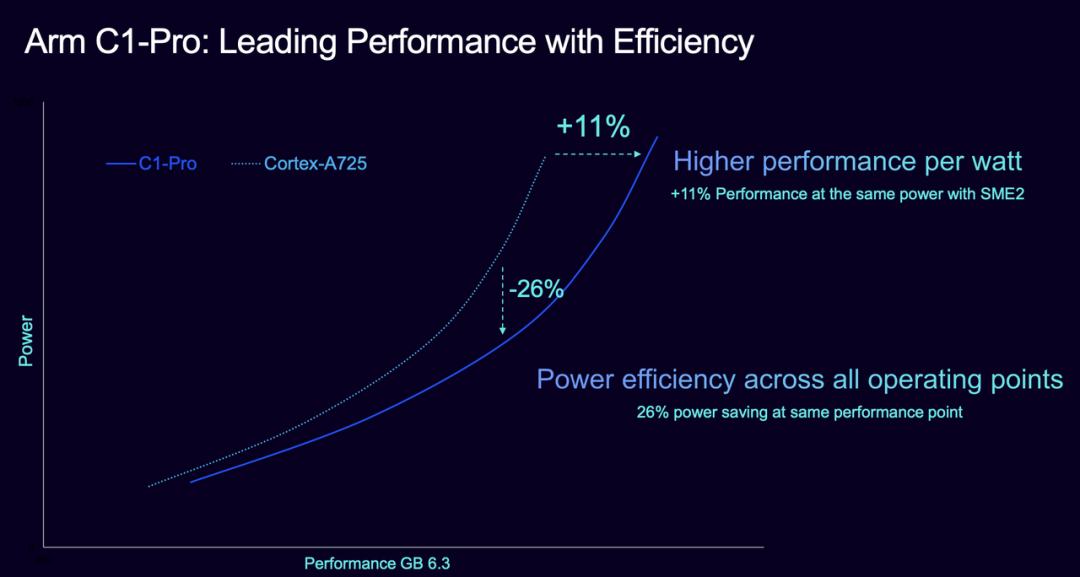
C1-Pro: The Mid-Range All-Rounder
The C1-Pro is the mainstay for mid-to-high-end devices. Compared to the Cortex-A725, it offers a 16% performance boost at the same frequency while reducing power consumption by 12%, thanks to more accurate branch prediction and higher memory bandwidth efficiency.
It also supports Area Optimization (AO) options, allowing chip manufacturers to pack more computing power into limited space. For example, in mid-range phone configurations like '4 Pro + 4 Nano,' the Pro cores handle daily tasks while accelerating AI inference, offering excellent cost-effectiveness.
C1-Nano: The Low-Power Battery Expert
The Nano core is designed for smartwatches or entry-level phones, offering a 26% improvement in energy efficiency and a 5.5% performance increase compared to the Cortex-A520, while reducing the chip area by 2%.
By optimizing instruction binding and cache access, it reduces memory dependency, enabling device battery life to last several days or even a week, making it ideal for low-power scenarios.
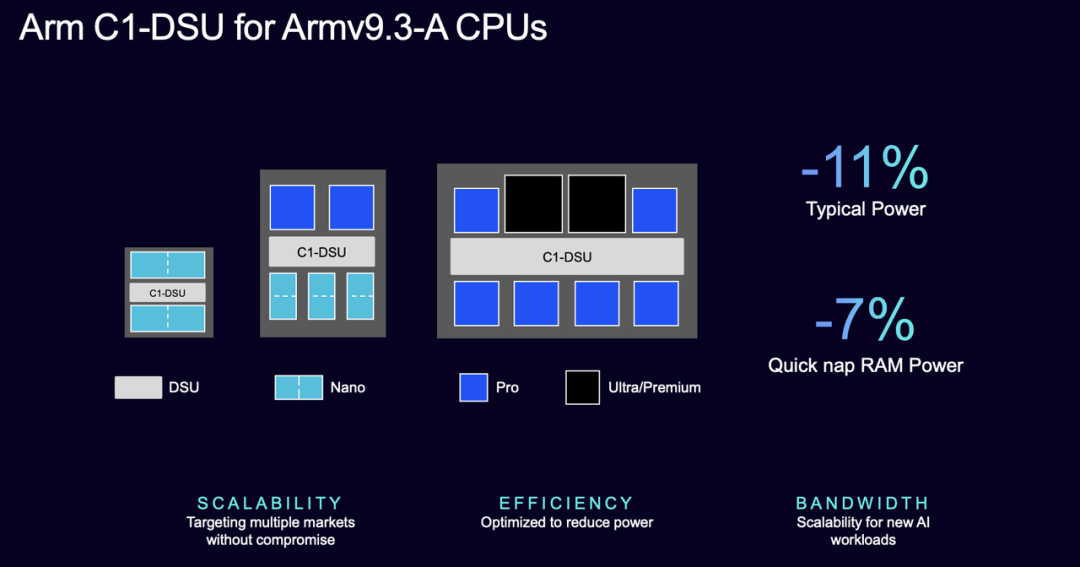
Shared Unit (DSU): The C1's DynamIQ shared unit (DSU) acts as a 'traffic hub' between cores, managing cache coherence and memory scheduling.
The new DSU reduces power consumption by 11%, cuts memory energy in sleep mode by 7%, and significantly boosts bandwidth, supporting multi-core simultaneous processing of AI inference or video rendering.
Chip manufacturers can thus expand performance while controlling overall power consumption.
The C1 cluster covers a wide range of needs from flagship to entry-level through the division of labor among its four core types. The Ultra focuses on performance, the Premium optimizes cost, the Pro balances computing power, and the Nano specializes in battery life, while the DSU enables seamless collaboration. This flexible design not only enhances performance and efficiency but also leaves room for future heterogeneous computing.
Part 2
AI Acceleration: Making Every Device 'Smart'
The standout feature of the C1 cluster is undoubtedly the addition of SME2 (Scalable Matrix Extension 2), which embeds a matrix computing engine directly into the CPU instruction set, enabling AI tasks to run faster and more efficiently without relying on external chips.
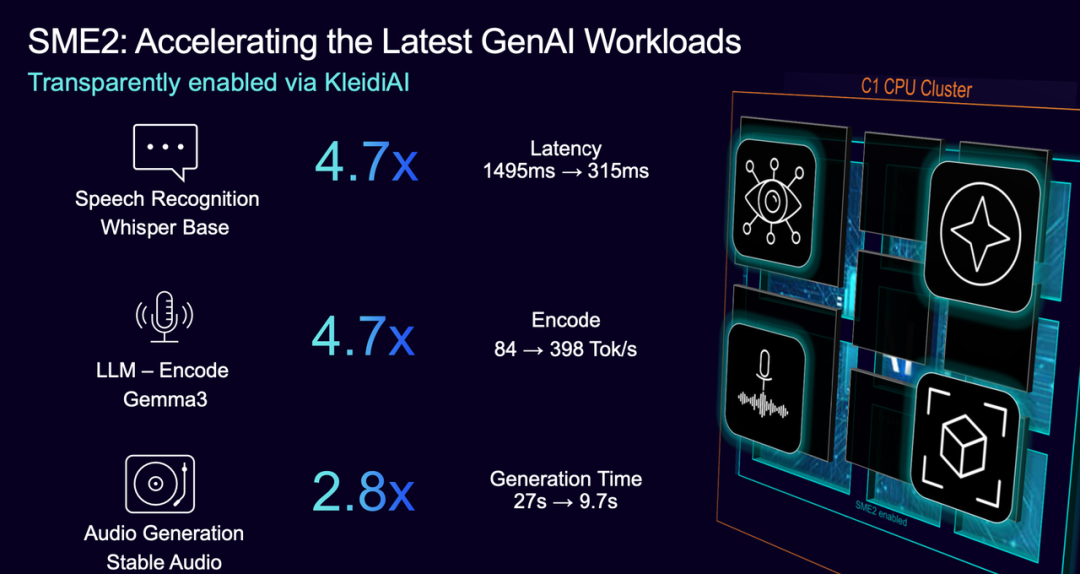
Compared to the previous generation, SME2 offers comprehensive upgrades in functionality, efficiency, and compatibility, supporting more complex data types and operations across various scenarios, from machine learning to high-performance computing.
Test data shows that speech recognition latency drops from 1.5 seconds to 0.3 seconds, a nearly fivefold speed increase. On the large language model Gemma3, inference speed surges from 84 Tok/s to 398 Tok/s.
In terms of energy efficiency, SME2 reduces AI task power consumption by about one-third. For example, audio generation time shortens from 27 seconds to 9.7 seconds, with a significant reduction in battery usage. More importantly, SME2 makes AI accessible beyond flagship devices.
Mid-range phones and entry-level devices can now run AI features like voice assistants and real-time filters through C1-Pro or Nano cores. Combined with SVE2 vector extensions and the KleidiAI software framework, developers can achieve acceleration on mainstream AI tools without additional adaptation, greatly lowering the development barrier.
The C1 also incorporates memory safety mechanisms (MTE) to protect sensitive data like voice assistants and personalized recommendations.
This is particularly crucial for AR glasses and real-time video processing, which require low latency and high security. Compared to traditional NPU or DSP solutions, SME2's direct integration into the CPU core eliminates data transmission overhead, enabling smoother real-time interactions.
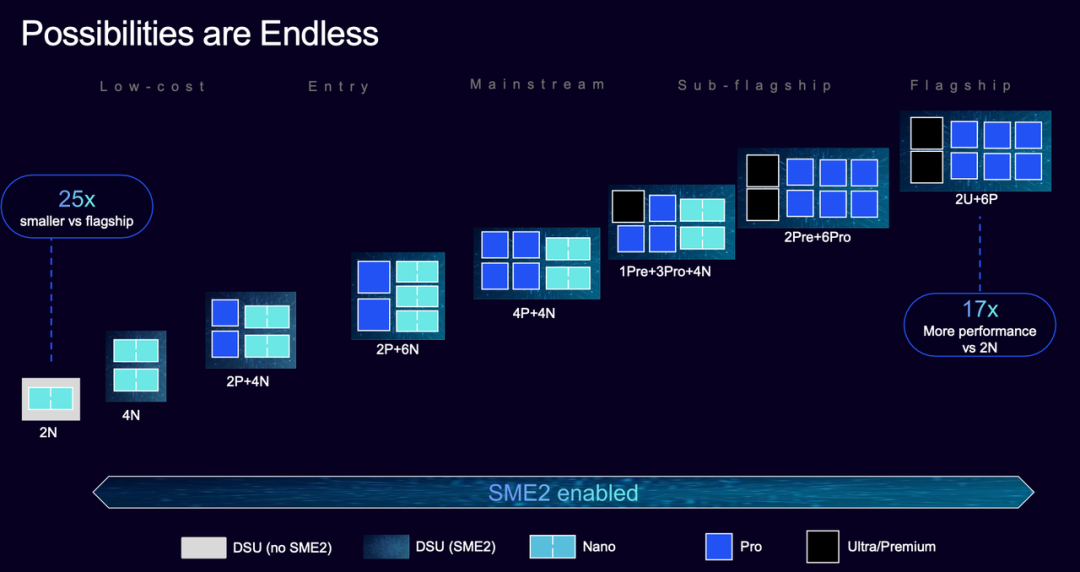
From a market perspective, the C1's flexible configurations make AI popularize (AI popularization) possible.
◎ Flagship devices use '2 Ultra + 6 Pro' for ultimate performance;
◎ Mid-range Chromebooks adopt '4 Pro + 4 Nano' for cost-effectiveness;
◎ Wearable devices employ '2 Pro + 4 Nano' for balanced performance and battery life.
This tiered design not only enhances user experience but also provides chip manufacturers with more options.

Conclusion
The Arm C1 cluster represents a design for mobile computing in the AI era, using four core types—Ultra, Premium, Pro, and Nano—paired with an upgraded DSU to achieve a clever balance of performance, energy efficiency, and cost. The addition of SME2 significantly boosts AI inference speeds and efficiency, enabling 'smart' experiences across devices from flagship smartphones to smartwatches.
-
![]()
Lei Jun Reveals Another Move: Xiaomi Auto Unveils Its Second Brand
-
![]()
The Declining Sales of Li Auto: A Strategic Shift
-
![]()
From a Second-Tier Luxury Leader to a Channel Outcast: Jaguar Land Rover Loses a Decade in China
-
![]()
Global Automotive Supply Chain Dynamics: China Surpasses U.S. to Secure Third Place
-
![]()
Three Generations of 'Kings of Online Ride-Hailing': BAIC, Aion, and BYD All Want to Move On | MIRROR Pro
-
![]()
Why Is OpenAI Considering Postponing Its IPO?
-
![]()
UBTECH Bionic Robots: A Fad or a Real Need?
-
![]()
BMW Group: Three Years of Performance Guideline Downgrades Amidst a Shrinking Chinese Market Share