What Are the Specific Requirements for the Training Data of Large Autonomous Driving Models?
 12/26 2025
12/26 2025
 638
638
Training a deployable large autonomous driving model is far from a simple task of merely providing a few images and rules. Rather, it necessitates a substantial volume of diverse and real-world driving data. This data empowers the model to genuinely comprehend the changes in roads, traffic participants, and the surrounding environment.
The crux of whether a large model can understand roads, assess situations, and make correct decisions in real traffic environments hinges on the diversity, realism, and accuracy of the data it encounters during training. If the training data is flawed, for instance, being of a single type, having a uniform environment, inaccurate labeling, or sensor misalignment, the trained large model may easily malfunction or make incorrect judgments when confronted with complex, extreme, or variable scenarios in real traffic.
Multi-sensor + Multimodal: Rich Sources of Perception Data
For autonomous driving, relying solely on the images from a single camera is inadequate for stable and comprehensive road condition judgment. Visual images excel at providing semantic information such as color, texture, signs, and light signals. However, they can falter in complex environments like low-light conditions, nighttime, strong backlight, occlusion, as well as rain, snow, or fog. Hence, utilizing sensors like LiDAR, Radar, and IMU/GNSS/GPS for positioning, attitude, and speed information proves highly effective in filling these visual blind spots. By fusing data from these sensors, multimodal perception can be achieved, enabling autonomous vehicles to understand their surroundings more reliably.
For autonomous driving models capable of “end-to-end” perception, decision-making, and even control, multimodal data is indispensable. These models need to integrate multiple “sensory” inputs, similar to how humans do. They should not only “see” objects and signs with cameras but also “measure” distance, depth, and speed with LiDAR and other sensors. In adverse weather or limited visibility, multiple data sources can complement each other, maintaining system perception stability.
Therefore, the data for training such models must encompass information from different sensors. This includes not only camera images but also LiDAR point clouds, Radar data, positioning, and Inertial Measurement Unit (IMU) information. These diverse data sources must be strictly synchronized in time and precisely aligned in space. They need to be calibrated before effective use in model training to ensure the effectiveness of multimodal fusion.
Environments and Scenarios Need to Be More Diverse
Real-world road environments are intricate and varied, ranging from urban streets, highways, rural paths, bridges, and tunnels to traffic facilities and driving habits in different countries and regions. Weather and lighting conditions also constantly change, with scenarios such as sunny, cloudy, rainy, snowy, foggy, nighttime, and backlight being possible.
Traffic participants are even more diverse, including not only cars, trucks, motorcycles, bicycles, and pedestrians but also pets, animals, temporary roadblocks, construction signs, and other irregular obstacles, as well as some human-caused abnormal obstacles.
If the data used to train the model only encompasses ideal scenarios with good weather, well-maintained roads, and orderly traffic, the driving experience learned by the model will be extremely limited. Once faced with complex, chaotic, or uncommon road conditions, the autonomous driving system may easily misjudge or even fail.
Therefore, to train a high-quality large autonomous driving model, it is essential to have high-quality training data that covers a wide range of diverse real-world scenarios and replicates various situations encountered in reality. This is also the foundation for enabling the autonomous driving model to generalize and safely adapt to different environments.
Labeling and Alignment: Data Must Be Clean, Accurate, and Meaningful
No matter how excellent the sensors, multimodal data, and complex scenarios are, if the data itself is not accurately labeled, strictly synchronized, and precisely aligned, it may not meet the requirements for training large models. Autonomous driving training data requires not only images and point clouds but also, more critically, for the large model to know what each object in the images and point clouds is, where it is located, which category it belongs to, and its possible motion state.
To enable the model to learn to recognize elements like lane lines, pedestrians, obstacles, distant vehicles, pedestrians approaching from the left, traffic lights, traffic signs, and roadside pillars, the training data must be precisely and detailedly labeled. The labeling content includes 3D bounding boxes of objects, categories (e.g., vehicles, pedestrians, bicycles, traffic signs, signal lights, obstacles), and sometimes motion trajectories across frames, occlusion status, and motion direction and speed (if required for prediction tasks).
Since the data comes from multimodal sensors (e.g., cameras, LiDAR, Radar), these sensors must be calibrated and synchronized in time to ensure complete correspondence between image frames, LiDAR point clouds, and other sensor data at the same moment. Otherwise, errors due to time deviations or spatial misalignment may occur when the model fuses multimodal information, affecting perception accuracy and even endangering driving safety.
When labeling, attention must be paid to labeling quality. Issues like incorrect labeling, missed objects, category confusion, inaccurate position, size, or angle of bounding boxes, inconsistency, or discontinuity across frames can lead the model to learn incorrect patterns, resulting in misjudgments during actual deployment.
Data Must Adapt to the Dynamic, Distant, and Long-term Characteristics of Real Driving
Perception and decision-making in autonomous driving must adapt to the dynamic, long-distance, and continuous nature of real traffic environments. Traffic environments are not static but continuously changing over time, with objects possibly in motion (e.g., pedestrians, vehicles), accelerating, decelerating, turning, or being occluded, entering, or leaving the field of view. A well-developed autonomous driving model must not only recognize the current instantaneous scene but also understand dynamic processes over time, predict future states and trajectories of objects, and handle occlusions, path planning, and decision-making.
Therefore, relying solely on static images or single-frame point cloud labeling data for training autonomous driving large models is insufficient. Training data should ideally include multi-frame continuous temporal information, enabling the model to learn motion patterns, trajectory prediction, speed and acceleration estimation, occlusion and reappearance phenomena, and interactive behaviors between objects. Many current multimodal datasets and research have taken temporal dynamic modeling into consideration.
Additionally, for long-distance perception in high-speed scenarios (e.g., distant vehicles or obstacles) and edge cases like complex weather, low light, and occlusion, training data must cover sufficiently distant, complex, and imperfect scenarios. Only then can the model remain stable and reliable in various real-world environments.
Therefore, scenarios like long-distance perception, nighttime, rainy conditions, mixed lighting, occlusion, and complex backgrounds should be adequately represented in the training data. Currently, many public datasets aim to fuse LiDAR, camera, and Radar data for 360-degree coverage, including various composite scenarios like nighttime, rainy conditions, urban, highway, and suburban areas, to enhance model adaptability and robustness.
Final Words
To train a large model deployable on real roads, the data must be “diverse, accurate, broad, and continuous.” This means having synchronized data from multiple sensors like cameras, LiDAR, Radar, and IMU, covering day/night, various weather conditions, and different road scenarios, including continuous frames and numerous edge cases. Labeling must be precise with 3D bounding boxes, tracking IDs, speed/direction, and occlusion information, while ensuring privacy compliance. Only with such high-quality, multimodal, temporal, and rigorously labeled data can the model transform massive samples into reliable perception, prediction, and decision-making capabilities, accelerating the deployment of autonomous driving.
-- END --
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
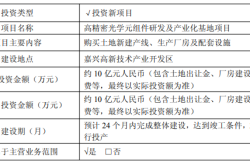
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?