Can Supercomputing Nodes Break the Barriers of AI? A Sneak Peek at the Highlights of WAIC 2025
 07/28 2025
07/28 2025
 678
678

Envisioning the future at WAIC 2025.

Stepping into the venue of the 2025 World Artificial Intelligence Conference (WAIC 2025), the surging crowd and enthusiastic atmosphere immediately envelop you.
As you walk through the exhibition, it is brimming with highlights. For the first time, the exhibition area has surpassed 70,000 square meters, featuring over 800 enterprises showcasing more than 3,000 cutting-edge exhibits, making it the largest in history. With over 80 premieres and 3,000 exhibits, the scale is truly awe-inspiring.
Among these, the intelligent computing super nodes and robotics sections stand out, promising to deliver unprecedented technological experiences and new ideas for industry transformation.
In the evolution of AI, computing power is the cornerstone. With the continuous advancement of large models, the demand for computing power has grown exponentially. Intelligent computing super nodes have emerged as a key solution to address the bottlenecks in computing power.
Huawei: Ascend 384 Super Node Steals the Show

At WAIC, Huawei debuted the Ascend 384 super node, also known as Atlas 900 A3 SuperPoD, offline for the first time. Based on a super node architecture, this product achieves high-bandwidth, low-latency interconnection among 384 NPUs through bus technology, solving communication bottlenecks between various resources such as computing and storage within the cluster. Through system engineering optimization, it achieves efficient resource scheduling, enabling the super node to function like a single computer.
According to on-site information, Huawei's Ascend 384 super node comprehensively optimizes computing, communication, parallelism, and memory, maximizing model training and inference performance. Single-card inference performance is improved by 4 times, decoding throughput exceeds 2300 Tokens, communication latency is reduced to below 50ms, and MFU computing power utilization reaches 50%. Currently, this product is already being utilized by enterprises such as Baidu, Meituan, and ByteDance.
ZTE: Intelligent Computing Super Node with 64 Cards per Server

ZTE showcased its intelligent computing super node server with a leading-edge architecture. With high-density computing power integration and efficient interconnection, it creates a high-efficiency hardware foundation for model training and inference on an ultra-large scale. It is understood that compared to Huawei's 32 cards per server, ZTE can achieve 64 cards per server.
H3C: Global Premiere of UniPod S80000

H3C brought the global premiere of its super node product, the H3C UniPod S80000. Tailored for the training and inference needs of trillion-parameter large models, it is a core device. Also on display were multiple intelligent computing servers, including the 5500 G7 and 5330 G7 Ultra, which can easily handle trillion-parameter large model training and inference scenarios.
It is worth noting that the new-generation lossless network solution based on the DDC (Diverse Dynamic Connection) architecture, as well as the new computing cluster switch H3C S12500AI, were also unveiled at this year's conference.
Ultra Fusion: The World's First Plug-and-Play Super Cluster System for Diverse Intelligent Computing

Ultra Fusion presented the world's first plug-and-play super cluster system for diverse intelligent computing. It realizes comprehensive software and hardware infrastructure technology and a comprehensive computing power ecosystem, compatible with over 10 accelerator cards, providing dual-ecosystem north-south secure heterogeneous computing power. It achieves a super power supply of 240kW per cabinet, equivalent to 32 cabinets; 128 AI accelerator cards per cabinet, with 112G/224G high-speed interconnection; and uses fifth-generation 100% native liquid cooling, achieving energy savings of over 20%.
Intel: Key AI-related Products


At the joint booth of Digital China and Intel, multiple key Intel chip products were showcased. The Intel Gaudi 2E AI accelerator card HL-288, in the form of a standard PCIe card, supports flexible single-card and multi-card configurations, providing multiple performance combinations, aiming to deliver high-performance, high-efficiency generative AI computing. This product is a standard full-height, full-length, double-slot passive cooling accelerator card with 2 MME matrix multiplication engines and 24 fully programmable tensor processor cores (TPC), configured with 96GB HBM2e memory, specifically designed to accelerate various deep learning workloads. The accelerator card chip integrates RDMA (RoCEv2), enabling connection with mature and widely used Ethernet, and can also achieve full connection interconnection of 4 PCIe cards through an additional 4-card full-connection board, meeting the needs of multi-node clusters of various specifications.

The Intel ARC Pro B60 professional graphics card provides powerful assistance for AI inference. Based on the upgraded Xe2-HPG architecture, it offers 20 Xe2 cores and 160 Intel XMX AI acceleration engines, as well as 24GB of high-capacity video memory, capable of delivering up to 197 TOPS int8 computing power. It is ideal for deployment in desktop and data center-level AI computing devices, embracing AI-driven innovation.

The Intel Xeon 6 processor is a data center processor family based on Intel's new microarchitecture design, offering two different CPU microarchitectures: performance cores and efficiency cores. Both the number of cores and IPC performance have been significantly improved compared to the previous generation. Depending on different workload needs, it provides the 6900 series for large data centers with higher performance and memory bandwidth, the 6700 and 6500 series that balance high performance and cost-effectiveness, suitable for complex data center environments, as well as the 6300 series for entry-level servers, among other options. The Intel Xeon 6 processor family is now fully available, providing diverse processor options to meet a wide range of business needs, from high-density computing and horizontally scalable workloads to high-performance multi-core computing accelerated by artificial intelligence.
The Intel Xeon 8558 processor is widely used in AI training servers, featuring 48 cores, supporting a 2.1GHz clock speed and a large 260MB cache, capable of supporting 80 PCIe lanes. With excellent computing performance and powerful scalability, as well as the Intel AMX acceleration engine optimized for AI, this CPU has become an outstanding choice for AI training server processors on the market and is widely used in various large-scale AI training clusters.
Muxi Integration: Xiyun C600 to be Released Tomorrow

The Xiyun C600 general-purpose GPU chip is designed and manufactured based on the domestic supply chain, with a high degree of autonomy and control. It features self-developed GPGPU architecture and instruction set, supporting general-purpose and intelligent computing, as well as self-developed MetaXLink interconnection technology, supporting multiple interconnection topologies. The chip tape-out is scheduled for July 2025.
The Xiyun C600 is set to be officially released tomorrow.
Moore Threads: KUAE2 Intelligent Computing Cluster

Moore Threads showcased its full-stack AI products and solutions built around full-featured GPUs, covering "cloud-edge-terminal" scenarios, comprehensively demonstrating a general-purpose accelerated computing platform based on domestic full-featured GPUs, the KUAE2 intelligent computing cluster solution, and application solutions for various industries.
The Moore Threads KUAE2 intelligent computing cluster solution is designed for large-scale intelligent computing centers, integrating computing, storage, network hardware, and distributed computing software, supporting up to 10,240 full-featured GPUs. KUAE2 caters to both AI and scientific computing, covering full-precision computing from FP64 to FP8, supporting full-scene acceleration for AI, graphics, and scientific computing.
KUAE2 possesses efficient AI large model training capabilities, with outstanding training performance that leads the industry. Relying on its native advantages in FP8 mixed-precision computing, KUAE2 achieves almost lossless precision compared to BF16, with FP8 GEMM utilization reaching industry-leading levels.
The robotics sector was also a highlight at WAIC 2025, with various robots showcasing their unique skills and application potential, depicting a new picture of future intelligent life and production, especially the development of embodied intelligent robots as a major attraction.
Beijing Humanoid: The First Industrial Multi-Agent, Multi-Scenario, Multi-Task Autonomous Collaborative Operation
The Beijing Humanoid Robotics Innovation Center showcased the country's first industrial "multi-agent, multi-scenario, multi-task autonomous collaborative operation" live demonstration, signifying that its "Huisi Kaiwu", released in March this year, has achieved a comprehensive upgrade in the capabilities of its distributed embodied intelligent agent system.

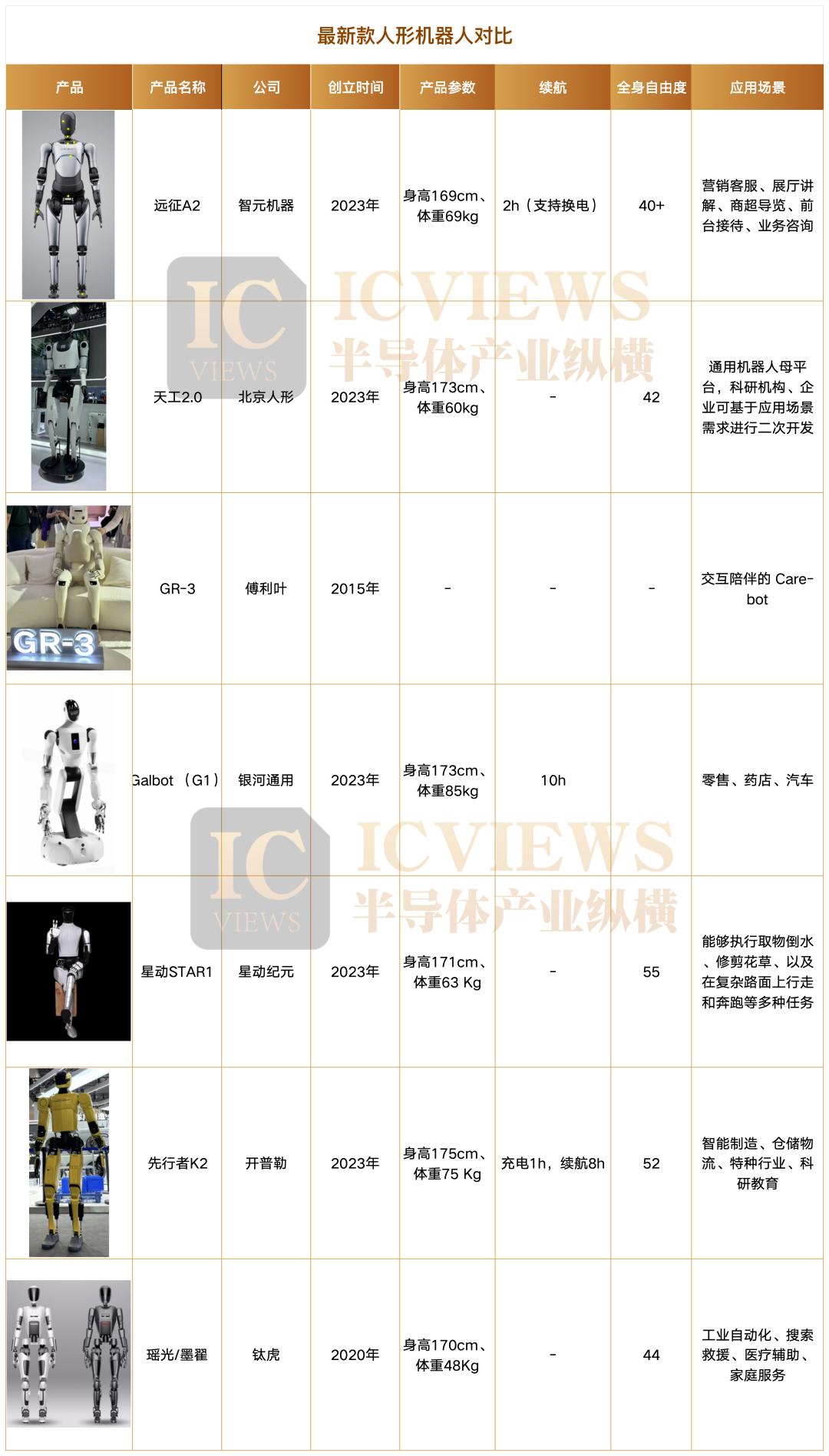
Tiangong 2.0 stands at approximately 173cm and weighs about 73KG. Its greater weight and longer limbs mean greater motion inertia and torque changes, requiring faster and more accurate real-time calculations and stable responses for motion control. Its 42 highly flexible dynamic linkages test the limits of the system's multi-joint coordination, real-time planning, and anti-interference capabilities.
It is worth mentioning that the champion robot "Tiangong Ultra", which set a world record with a time of 2 hours, 40 minutes, and 42 seconds at the Beijing Yizhuang Half Marathon in April this year, also made a surprise appearance, attracting a large number of spectators to take photos with it.
Wisdom Robotics: The World's First End-to-End Embodied Intelligent Robot Logistics Operation

Wisdom Robotics demonstrated the world's first truly data-driven end-to-end embodied intelligent robot logistics operation, reducing the cross-scenario migration time of embodied intelligence from weeks with traditional solutions to hours, and requiring only minor adjustments to the end control layer for cross-agent adaptation. By combining the atomic action library, it can successfully achieve over 80% cross-task expansion.
It is understood that Wisdom Robotics will cooperate deeply with Dematic to establish the world's first "humanoid robot training and data collection factory" based on logistics operation scenarios.
Unitree Robotics: The Birth of the "Boxer"

Unitree Robotics showcased a fighting performance between the G1 robot and a real person. In the image, the G1 robot is fully equipped, wearing professional boxing gloves and a protective helmet, standing heroically on the fighting stage.
Notably, on the eve of WAIC, Unitree Robotics suddenly unveiled its third humanoid robot, the Unitree R1, priced from RMB 39,900.
Unitree defines R1 as an "intelligent companion" and clearly states that it is a platform-level product "born for sports". Structurally, R1 has 26 degrees of freedom, including a complete humanoid structure with bipeds, dual arms, hands, waist, and head, with an overall weight of only about 25kg.
Kepler: Charge for 1 Hour, Work for 8 Hours

Kepler's K2 "Bumblebee" stands at 175cm and weighs 75kg, with 52 degrees of freedom throughout its body. The overall computing power reaches 100 TOPS, enabling efficient decision-making capabilities. The self-developed planetary roller screw actuator features high load, long endurance, and high precision. The self-developed precision rotating actuator ensures the accuracy and high stability of the robot's movements.
It achieves ultra-long endurance of 8 hours of continuous operation with a single 1-hour charge and a load capacity of 30kg. It is understood that K2 has previously been tested in actual scenarios for leading customers in intelligent manufacturing, warehousing logistics, special operations, scientific research and education, among others, for material handling, sample processing, patrol inspections, stamping and receiving, quality inspection, and other scenarios.
Fourier: New Humanoid Robot GR-3

Fourier's new humanoid robot GR-3 is the third generation of its GRx full-size universal humanoid robot series. GR-3 innovatively introduces a soft skin cover design and a full-sense interactive system, further expanding the robot's experience boundaries in the dimensions of companionship and emotional interaction based on functional iteration. GR-3 will be officially released in Beijing on August 6.
Introducing the Newly Enhanced Qinglong V3.0 Humanoid Robot

Qinglong V3.0 stands tall at 185 centimeters and boasts a robust frame weighing 85 kilograms, embodying a full-sized, versatile humanoid robot with 38 active degrees of freedom (including 12 in its hands). Tailored for security patrols, industrial operations, and logistics park duties, this advanced machine excels in high-frequency, repetitive tasks such as autonomous indoor and outdoor security patrols, workstation loading and unloading, and assisting in handling tasks, thereby alleviating labor burdens and operational risks for enterprises.
Equipped with an optional intelligent sensing head, Qinglong V3.0 integrates visual, smoke, and gas detection sensors, coupled with sophisticated visual recognition algorithms, allowing for comprehensive environmental perception. For security patrol applications, it comes standard with a 5-DOF robotic arm, fulfilling basic motion and operational needs. Additionally, an optional 7-DOF robotic arm can be fitted to meet the demands of high-precision, complex tasks in industrial and logistics environments, supporting the integration of end-effector tools like dexterous multi-fingered hands and electric grippers.
The evolution of these robots signifies a shift from mere mechanical executors to intelligent entities capable of perception, cognition, and interaction. Their diverse applications in industries, services, and energy sectors promise to significantly boost production efficiency, enhance quality of life, and propel various industries towards greater intelligence and automation.
*Disclaimer: This article is authored by the original writer, and the content reflects their personal views. Our reproduction aims solely for sharing and discussion purposes and does not imply endorsement or agreement. Should there be any objections, please contact us directly.
-
![]()
Li Bin Claims, 'Denying the Pure EV Trend is Like Ostrichism.' What's Li Xiang's Take?
-
Lenovo: Liu Jun Turns Left, Yang Yuanqing Turns Right
-
Lenovo: Liu Jun Goes Left, Yang Yuanqing Goes Right
-
![]()
MiniMax Shares Unlock: Cornerstone Shareholders Show Long-Term Optimism, Yet Stock Plummets Nearly 30% in Two Days; Zhipu Also Sees Nearly 20% Drop Today
-
![]()
Single-Day Plunge of 40%: The 'First AGI Stock' Faces More Than Just Share Price Concerns
-
![]()
Ricoh and Fuji Hike Prices on Legacy Edge; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Ricoh and Fujifilm Raise Prices in Tandem, Relying on Established Reputations; Insta360 Poised to Disrupt Mirrorless Camera Market
-
![]()
Strategic Shift in Photoelectric Sensing: Maxvision Secures Controlling Stake in CAS Optotech




