How Can We Effectively Train an End-to-End Model for Autonomous Driving?
 12/08 2025
12/08 2025
 583
583
Recently, a friend posed a question in the comments section: How are end-to-end algorithms trained? Are they divided into categories such as imitation learning, reinforcement learning, and offline reinforcement learning? Indeed, in the realm of autonomous driving and intelligent agent decision-making systems, end-to-end algorithms leverage imitation learning (including behavioral cloning, inverse optimal control/inverse reinforcement learning, etc.), reinforcement learning (RL), and the increasingly popular offline reinforcement learning (OfflineRL/BatchRL) in recent times.
What is 'End-to-End' Training?
The application of end-to-end training in autonomous driving is on the rise. End-to-end refers to a system that directly maps the most fundamental perceptual inputs (such as camera images, sensor data, etc.) to the final control outputs (such as steering, acceleration, deceleration, braking, etc.). Unlike traditional autonomous driving systems, which split the process into several independent modules ('perception → recognition → planning → control'), end-to-end training integrates these steps into a single, unified neural network/model.
The benefits of this approach include a streamlined process, holistic model optimization, and the potential to learn complex mapping logic with sufficient data and appropriate training techniques. However, it demands a large volume of data, advanced training methods, and strong generalization capabilities. Given that a sufficiently intelligent end-to-end system can be trained with enough data, what methods should be employed to teach it? What are the pros and cons of these methods?
Imitation Learning
Imitation learning, also known as learning from demonstration, is one of the most straightforward and widely used methods in end-to-end training. Its core principle is that if you possess a series of 'state-action' demonstrations from an expert (such as a human driver, an experienced control system, or an excellent strategy), the model can learn from these demonstrations.
In imitation learning, a classic approach is behavioral cloning (BC). This method treats expert data as a training set, using the state as input and the corresponding expert action as the 'label/ground truth,' and trains the network through regression or classification.
To enable the model to not just mimic actions but also comprehend 'why' they are performed, techniques like 'inverse optimal control/inverse reinforcement learning' (IRL) are utilized. These methods infer the 'reward function' (i.e., why the expert took these actions and the underlying goals) from expert behavior and then train a policy based on this reward function.
Advantages and Challenges
The primary advantage of imitation learning/behavioral cloning is its simplicity and efficiency in data utilization. It transforms complex strategy learning problems into standard supervised learning tasks, leveraging large amounts of high-quality expert demonstration data to quickly learn a reasonable strategy within the data distribution. In scenarios where expert behavior is well-represented and the environment is relatively stable, this method can yield excellent results.
However, imitation learning/behavioral cloning also presents several challenges. Its generalization ability and robustness are relatively limited. If the model encounters rare, dangerous, or extreme situations (such as emergency braking, unconventional steering, sudden road condition changes, etc.) not present in expert demonstrations, it may struggle to determine the appropriate action due to the lack of similar training scenarios and demonstration actions.
Behavioral cloning overlooks the 'sequentiality/temporal correlation' of the decision-making process. It treats each frame's state and action as independent samples, whereas in reality, actions are highly correlated, and one action influences future states. This can lead to distribution shift problems, where once the system deviates slightly from the expert trajectory, it may drift further away.
Reinforcement Learning
Another widely adopted method in end-to-end training is reinforcement learning (RL). Unlike imitation learning, which relies on expert demonstrations/labeled data, RL formulates a learning strategy (policy) through an agent interacting with the environment, taking actions, observing results, and receiving 'rewards' or 'penalties,' ultimately maximizing long-term cumulative rewards.
When combined with deep neural networks, reinforcement learning evolves into deep reinforcement learning (DeepRL/DRL). DRL can directly map high-dimensional primitive perceptual inputs (such as images, LiDAR point clouds) to actions or control signals, enabling end-to-end learning from perception to decision-making. Its powerful representation and learning capabilities make it highly promising for tasks with complex inputs and continuous decision-making demands, such as autonomous driving and robot control.
Advantages and Challenges
Training end-to-end models with reinforcement learning offers a significant advantage: theoretically, it does not rely on 'expert demonstrations' but explores new, even 'unseen by experts' strategies through 'trial and error + reward mechanisms.' In complex, dynamic environments, it may yield more flexible and robust strategies than pure imitation.
However, implementing reinforcement learning effectively is challenging. For RL, designing a reward function that truly reflects comprehensive goals like safety, efficiency, comfort, and regulations is difficult. If the reward function is poorly designed, RL may learn strange but high-reward strategies.
The RL training process also necessitates extensive interaction and trial and error with the environment, leading to high computational costs and time consumption for data collection, simulation, and training. Deploying training directly on real vehicles can result in dangerous behaviors or accidents due to the highly unstable strategies generated by the agent in the early exploration stages. Even when training in simulators, there is the 'simulation ↔ reality' discrepancy (sim-to-real gap).
The interpretability of end-to-end RL is also poor, as the neural network lacks clear, human-understandable modules (such as 'detect pedestrians → judge priority → plan trajectory → control') and instead functions as a black-box mapping. This makes it difficult to trace specific causes when errors or abnormal behaviors occur.

Offline Reinforcement Learning (OfflineRL/BatchRL)
In recent years, technical proposals have introduced offline reinforcement learning (OfflineRL, also known as BatchRL) to address safety, resource, and practical interaction challenges when applying RL to real-world systems (such as autonomous driving, healthcare, and robotics). The fundamental premise of offline RL is to prevent the model from interacting with the real environment during training. Instead, a batch of historical interaction data, similar to expert demonstration data or logs, is collected and used to train a strategy without further interaction.
Offline RL can be viewed as a hybrid approach combining data-driven and strategy optimization. Like imitation learning, it leverages static historical interaction data for training, avoiding the safety risks and costs of online trial and error. Simultaneously, it retains the core mechanism of traditional reinforcement learning by estimating and optimizing the value of states and actions in the data, enabling the strategy to further enhance performance based on existing data. This approach allows it to attempt learning strategies that are superior and more robust than behavioral cloning while ensuring safety.
Advantages and Challenges
The greatest advantage of offline RL is its safety and ability to utilize existing data while reducing reliance on real-world exploration. This makes it particularly suitable for high-risk fields like autonomous driving, healthcare, finance, and robotics. By combining the potential of RL with real-world constraints, it represents a promising development direction.
However, since offline RL cannot explore new states/actions during training and must rely solely on the existing state/action combinations in the dataset, it faces the issue of 'distribution shift.' This means that when the trained strategy is deployed in reality, it may encounter states/actions not covered in the dataset, leading to unreliable performance. To address this, technical proposals have introduced various mechanisms, such as constraints/regularization/uncertainty penalties/action space restrictions/model-based methods, to constrain model behavior.
Other Learning Methods
1) Self-Supervised Learning
For autonomous driving systems that rely on vast amounts of visual/sensor data, the data volume is enormous, but manual labeling is time-consuming and costly. Therefore, technical proposals have introduced self-supervised learning approaches, allowing the system to first learn meaningful features/representations from large amounts of unlabeled raw data and then apply them to downstream end-to-end control/decision-making tasks. This reduces reliance on manual labeling.
2) Teacher-Student/Privileged Information Distillation
This method, known as the teacher-student framework, adopts a staged training approach. It first utilizes information only available in simulations or data (such as precise maps, object true states, etc.) to train a powerful 'teacher' model, enabling it to master decision-making and planning capabilities. Subsequently, a 'student' model is trained, which can only use sensor input information available to the actual vehicle (such as camera images, radar point clouds). By imitating the decision outputs of the teacher model, the student model indirectly learns the teacher's reasoning capabilities.
This approach combines real-world accessible information with strong model decision-making capabilities, reducing the difficulty of end-to-end strategy learning directly from primitive perceptual signals. It is an important avenue for enhancing system performance and reliability.
3) Hybrid/Staged Training
Training end-to-end models does not have to rely on a single training method; multiple approaches can be combined. For example, imitation learning or self-supervised learning can be used for 'pre-training/initialization' (pre-training/behavior cloning/feature learning), followed by reinforcement learning or offline RL for fine-tuning/optimizing the strategy. In such a 'hybrid training pipeline,' the initial safety/reasonableness of 'imitating expert behavior' can be balanced with the flexibility/robustness of 'exploring and optimizing strategies.'
4) Evolutionary/Evolutionary Learning Methods (such as Neuroevolution)
Besides gradient descent-based backpropagation and reinforcement learning, another noteworthy technical path is the application of evolutionary algorithms in neural network optimization, known as neuroevolution. This method does not rely on gradient calculations but instead iteratively optimizes network structures, parameters, or behavior strategies by simulating natural evolution processes, including population generation, mutation, crossover, and survival of the fittest. This gradient-free optimization approach can handle complex environments with non-differentiable or sparse rewards, offering certain robustness and exploration advantages. Although not currently a mainstream solution in end-to-end autonomous driving systems, it provides a complementary perspective for addressing optimization problems that traditional methods struggle to solve.
Final Thoughts
For end-to-end systems, the choice of training algorithm is undoubtedly crucial. However, enabling a vehicle to learn safe and reliable driving capabilities depends more on data quality, training strategies, scenario coverage, and operational monitoring. These factors can sometimes be more critical than the model architecture itself.
-- END --
-
![]()
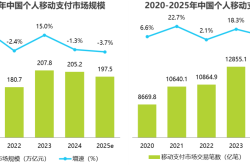
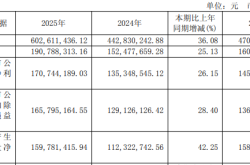
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming