The Difficulty of Transitioning from Large Models to Agents is Being Severely Underestimated by the Entire Industry
 04/10 2026
04/10 2026
 523
523

Over the past two years, the coordinate system of AI narratives has nearly lost its accuracy.
Static metrics like MMLU and HumanEval have been repeatedly posted like college entrance exam rankings, with constantly refresh (updated) numbers seemingly declaring that artificial general intelligence (AGI) is nearing the finish line.
However, a new benchmark called APEXAgents has burst this illusion.
What it reveals is not a linear progression in model intelligence but a harsh paradox: as AI attempts to transition from 'answering questions' to 'completing tasks,' capability improvements are falling into severe data hunger.
The shift from LLMs (Large Language Models) to Agents is not a version upgrade but a paradigm shift from static intelligence to dynamic productivity. The difficulty of this transition is being severely underestimated by the entire industry.
01
The Handover of the Evaluation Scepter
Over the past three years, LLMs have been the primary form of AI.
At that time, the focus of model evaluation was on 'intelligence'—how much static knowledge the model could master and whether it could correctly perform logical deductions.
However, as AI's form transitioned from LLMs to Agents in less than half a year, the scepter of evaluation must also change hands.
The core essence of an Agent lies in its need to engage in high-frequency perception and interaction with digital or even real-world physical environments.
The APEX-Agents benchmark test completely abandons the previous 'question-and-answer' style math and programming exams, replacing them with 33 data-rich simulated worlds (Worlds).
Each world represents a unique project scenario, containing an average of 166 files and involving more than nine application tools.
For models, this is vastly different from the 'armchair theorizing' interaction style of large language models.
Instead of facing complex math and programming problems, the model is placed in a digital sandbox and must observe environmental changes, break down complex instructions, call various tools, and deliver final results over hours-long task chains, just like a human employee.
Objectives like code execution, PDF parsing, and spreadsheet tag operations in the early days of the agent era have now become minor but extremely fault-intolerant intermediate steps.
This shift in evaluation standards reflects a substantive change in the threshold for AGI:
It cares not about what the model knows but what it can accomplish in complex environments.
To simulate the 'sense of gravity' that real-world workplaces impose on humans, APEX spared no expense in inviting 256 top experts from McKinsey, Goldman Sachs, Cisco, and other companies, with an average of 12.9 years of industry experience.
These experts not only propose tasks for the models based on their expertise but also provide clear 'process rubrics,' transforming the evaluation from an intellectual game into a productivity challenge.
02
The Performance 'Fig Leaf' Ruthlessly Exposed
Faced with the Pass@1 (first-time pass rate) rankings from APEX-Agents, any claims of 'AGI being imminent' for commercial purposes are immediately disproven.
The data reveals a sobering slump, with low accuracy rates starkly contrasting with high scores, directly bursting the AGI bubble.
This benchmark test's scenarios primarily evaluate three roles: corporate lawyer, management consultant, and investment banking analyst.
The report shows that Gemini 3 Flash from Google, one of the global AI triumvirate, achieved only a 24% score even in highly contemplative mode.
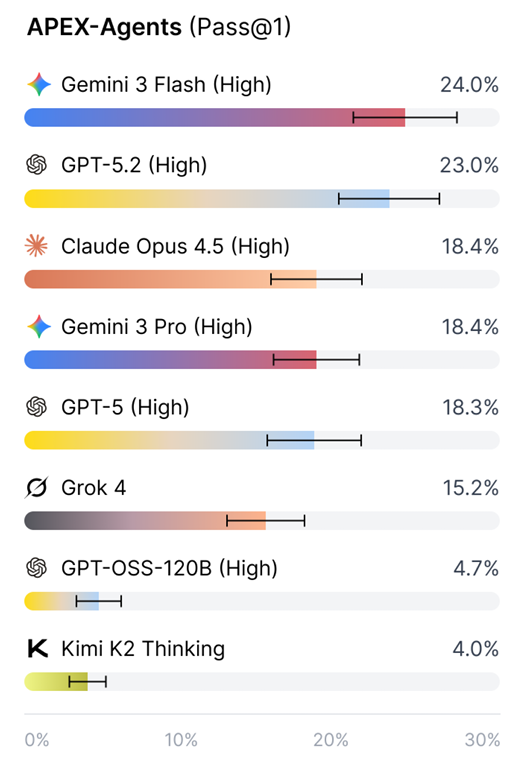
GPT-5.2 (High), also from the triumvirate, fared no better, ranking second with a 23% score.
In specific professional scenarios, scores were also unimpressive, with even the most advanced models struggling to break the 30% threshold.
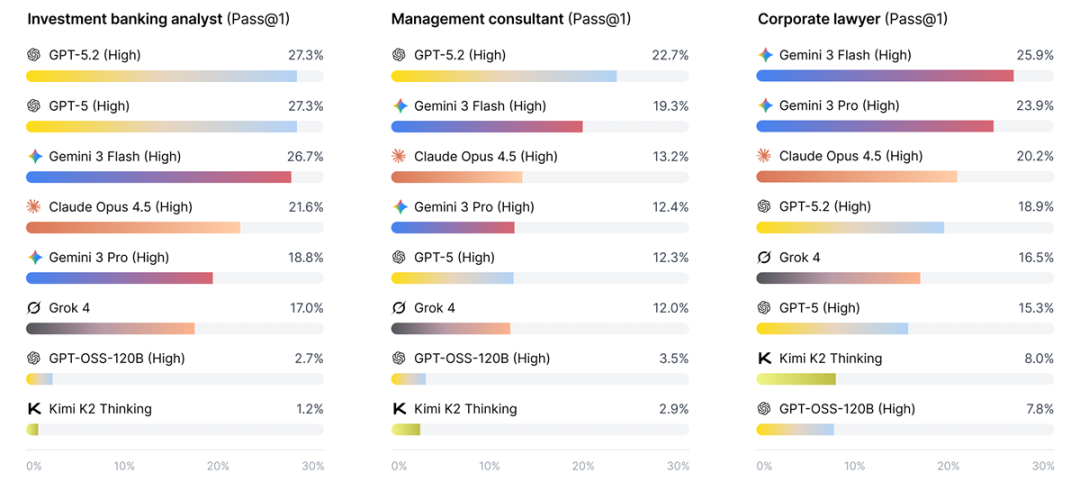
Under these circumstances, discussing which model is more capable becomes largely meaningless.
The key question is why LLMs, which previously offered a good user experience, perform so poorly in practical tasks.
The APEX report points out several critical failure modes, which represent the biggest limitations preventing large models from becoming productivity tools:
Doom Looping: When tool calls fail, the model cannot effectively reflect but repeatedly attempts the same erroneous instructions until it exhausts the preset step limit. Thus, current Agents still lack cognitive abilities.
Rogue Behavior: GPT-5.2 made a major mistake during testing, accidentally deleting 21 critical production files. For rigorous financial and legal fields, such misoperations inevitably lead to catastrophic consequences.
Long-Term Planning Loss: When task steps exceed limits, the model's 'intent drift' phenomenon becomes severe—the most common issue in Vibe Coding, where the model forgets its initial goal halfway through task execution.
If the number of attempts is relaxed to 8 (Pass@8), top models can score close to 40%, but stability metrics drop to a minimum of 6.5%, a typical characteristic of current agents: potential but highly unstable.
In other words, agents can produce fragmented valid information but struggle to complete closed-loop delivery.
These data also reveal a deliberately concealed truth:
At this stage, agents can only be considered the most rudimentary form of AGI.
Claims that AGI progress is mostly complete are purely commercial packaging based on static intelligence tests.
The performance bottleneck of traditional LLMs lies primarily in computing power and parameter count, while the threshold in the Agent era has shifted to task orchestration, state management, error recovery, and long-term planning.
Agents cannot even bridge the gap between 'usable' and 'reliable,' let alone become 'easy to use.' Faced with complex workflows, AI remains extremely immature.
03
The Cost Trap
In existing Agent evaluations, accuracy logically becomes the sole protagonist, but the token consumption costs—which have a decisive impact on commercial adoption—are often overlooked.
As is well known, Agents consume tokens on a completely different scale from LLMs.
Data from the APEX report makes this gap even more concrete:
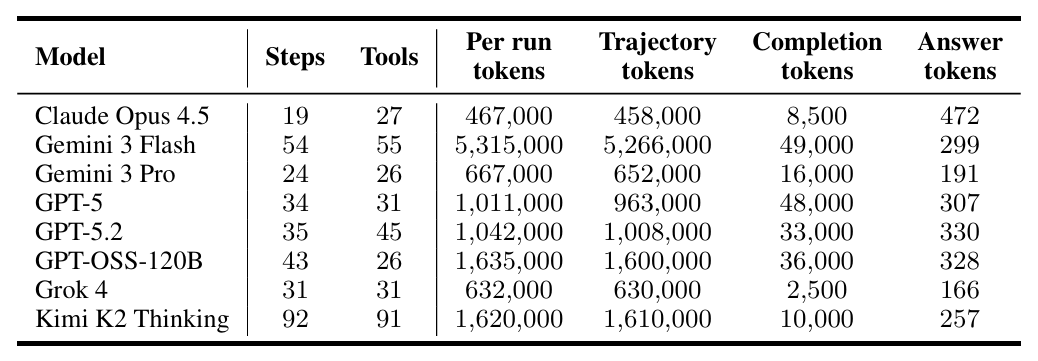
Google's latest model, Gemini 3 Flash, leading with a 24% Pass@1 score, consumes an average of 5.315 million tokens per task—about 5 times that of GPT-5.2 and 8 times that of Gemini 3 Pro.
However, the performance advantage gap is only 1%.
This figure is enough to make any developer pause before making decisions.
At current closed-source model prices, completing a complex investment banking task would inevitably incur computing costs of dozens of dollars.
Even without considering the fixed costs of model deployment, AI's operational costs already approach or exceed the hourly wage of a junior human analyst.
The current low accuracy rates exhibited by agents are essentially achieved through cost-insensitive brute-force reasoning.
Models can trade success rates for massive chains of thought (CoT) and repeated retries, but in commercial contexts, neither approach can be used unlimitedly.
Thus, this 'high-consumption + low-gain' diminishing marginal returns effect directly points to an industry-level proposition:
In the agent era, cost-effectiveness must be equally important as accuracy—or even more decisive.
Future Agent benchmark tests must introduce token-based return on investment.
If Agents cannot achieve low-power, high-precision closed loops, they will never become the universal infrastructure society expects.
04
Ecosystem Differentiation and Commercial Landscape
Another noteworthy phenomenon in the APEX report is the complete failure of open-source models in this benchmark test.
During the LLM era, open-source models, through parameter expansion and high-quality corpus pre-training, had repeatedly approached or even surpassed the previous flagship models of AI giants in multiple static benchmarks.
However, after entering the Agent era, the narrative of 'open-source equality' has nearly collapsed.
Although top models globally also fail to achieve 'reliability,' closed-source models still deliver a dimensionality reduction strike against open-source models, with scores like GPT-OSS-120B and Kimi K2 even below 5%.
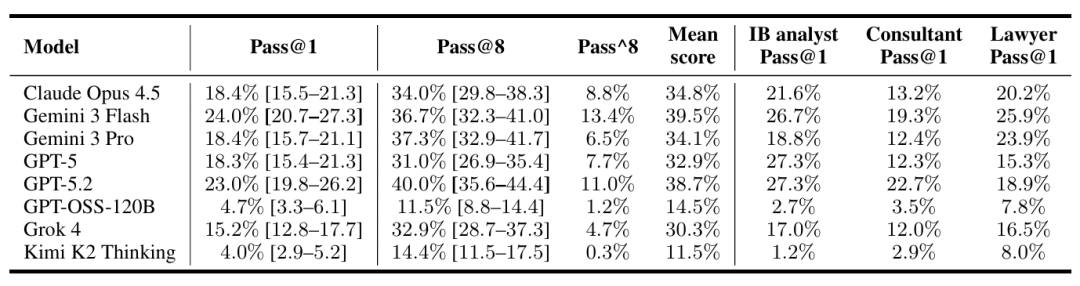
However, facts prove that when faced with practical tasks involving long-term planning, strict instruction adherence, and tool invocation, these open-source models remain unusable.
Of course, attributing this gap solely to insufficient reasoning capabilities of the base models is not objective; the systemic complexity of agent capabilities is also crucial.
An Agent capable of stably executing long-term tasks requires not only a strong language understanding capability from the underlying model but also perfect execution of details easily overlooked in the LLM era, such as trajectory optimization and state consistency.
Closed-loop data, large-scale computing power scheduling, and end-to-end technology stacks are the commercial lifeblood of closed-source vendors in the agent era.
However, open-source models remain in their infancy, lacking high-quality behavioral alignment data.
Controlling an agent's 'working logic' and execution trajectory is equivalent to establishing a solid data barrier.
Thus, while the AI logic of the LLM era is being subvert (subverted), we can also clearly see the present facts and future trends:
Almost none of the models truly 'getting things done' in agents are free.
05
Existing Data Poses a Major Challenge
Whether in the LLM era or the Agent era, the three essential elements of AI remain unchanged: algorithms, computing power, and data.
In our previous article, we discussed how the logic of computing power economics has been completely rewritten in the Agent era, noting that computing power shortages are an objective and unchangeable fact in the short term.
However, as agents replace LLMs as the new AI form, a fundamental challenge has emerged for everyone:
Agent capability improvements are falling into severe data hunger.
ByteDance's astonishing success with Seedance 2.0, powered by TikTok's massive real visual data, has proven that even with inferior computing power compared to Google and OpenAI, it can still surpass Veo and Sora to achieve breakthroughs in multimodal fields.
However, this successful logic cannot be directly applied to agents because text, images, audio, and video are all 'unstructured' existing data from before the AI era.
The logic of agents executing tasks differs from that of multimodal models; it represents an invisible logic of 'how humans use tools to complete tasks.'
Obviously, this logic could not have been massively digitally recorded before the AI era.
How humans open Excel, modify formulas based on errors, or confirm requirements in emails—these most common daily scenarios are extremely complex and difficult to abstract for AI.
While the internet contains massive amounts of high-quality text data, it lacks high-quality 'task execution trajectories.'
In fact, Jensen Huang's 2024 prediction precisely hit this pain point: relying solely on existing data accumulation cannot support the evolution of next-generation AI.
Like embodied AI, to resolve current agent bottlenecks, high-fidelity virtual world environments must be constructed, and high-quality training samples generated through synthetic data technology.
The Archipelago infrastructure built for the APEX benchmark test is essentially an accelerated iteration testbed specifically designed for agents.
In these virtual environments, Agents can experience millions of failures and corrections, simulating extreme scenarios difficult to reproduce in real-world workplaces.
The future AGI threshold will no longer be about how much internet text one has read but how rich one's observed action trajectories are in simulated environments.
The essence of agent training remains reinforcement learning, and without sufficient 'learning materials,' the result can only be severe underfitting.
The APEX benchmark test is not just a technical metric but also a reshaping of industry cognition.
People should see clearly how far we are from a true AI productivity revolution.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?