Liang Wenfeng: Marching to His Own Beat
 05/12 2026
05/12 2026
 526
526

Written by Dou Wenxue
Edited by Ziye
In a book penned by Zhang Jinjian, founding partner of Oasis Capital, a tale unfolds about the inaugural encounter between Yan Junjie, the visionary behind MiniMax, and Liang Wenfeng, the mastermind of DeepSeek.
At that fateful meeting, Liang, clad in a simple T-shirt, dove straight into a barrage of technical queries without so much as an introduction.
"I mistook him for an assistant; a rather knowledgeable one at that," Yan recounted. It wasn't until a half-hour later, when Yan inquired, "When will Mr. Liang arrive?" that the revelation dawned—Liang was, in fact, his interlocutor.
Dressed casually, eschewing any semblance of bossly pretense, and deeply engrossed in technology, this is the impression Liang Wenfeng has imprinted upon the world. His persona is largely constructed through the accounts of those around him. From media narratives, a portrait emerges of a low-key, enigmatic figure who shuns company team-building exercises, focusing solely on programming—a stark departure from the traditional mold of a "star company founder."
With such a founder at the helm, DeepSeek stands out as one of the most distinctive entities within the AI large model landscape.
Image source: DeepSeek official website
In May 2024, DeepSeek made waves in the crowded AI large model arena by offering pricing and costs significantly lower than those of traditional large models, achieving top-tier international performance, and providing open-source technical reports and model weights. This move also ignited a price war within the industry.
The company eschews product launch events, is unhurried in iterating its products, refrains from jumping on emerging sector bandwagons, and avoids excessive product hype. Yet, it remains at the epicenter of industry attention.
It refrains from spinning commercialization yarns. Despite operating in a sector like AI large models, which demands substantial R&D investment, DeepSeek is financially robust. Consequently, it has long shunned financing, believing that capital interference could sway its technological direction and impede the company's autonomous development.
Thus, when rumors surfaced recently that DeepSeek would embark on equity financing, it once again became the focal point of AI circle discussions.
Public sentiment has struggled to keep pace with DeepSeek's meteoric valuation rise. Since mid-April this year, when rumors emerged that DeepSeek would release around 3% of its equity for financing at a $10 billion valuation, DeepSeek's valuation has undergone multiple revisions. Recently, reports have claimed that DeepSeek's valuation could soar to $50 billion, marking a fivefold increase in just three weeks.
As things stand, it may seem that DeepSeek is succumbing to the allure of substantial financing. However, this is far from the truth. DeepSeek maintains stringent requirements for investors and rejects excessive capital interference in the company. According to a report by The Information, Liang Wenfeng still holds sway over this round of financing, with personal contributions of up to RMB 20 billion, accounting for 40% of the total fundraising.
It is challenging to assess DeepSeek based on industry norms or trends because its leader, Liang Wenfeng, has always followed his own rhythm.
1. Liang Wenfeng, Financially Secure, Exercises Caution in Financing
In the narratives of many startups, the financing trajectory often follows a familiar path: establishment - financing - team building - product launch - further financing, culminating in a sprint towards listing with the support of a lavish capital network.
In this process, a tacit understanding usually exists between the company and capital: capital provides funds and makes demands; the company cedes a portion of control but gains the confidence to forge ahead.
However, DeepSeek has deviated from this template since its inception. A widely circulated story recounts the "three nos" rules that Liang Wenfeng allegedly set for DeepSeek: no external financing, no equity dilution, and no being held hostage by anyone's commercialization timeline.
This somewhat stringent rule has been rigorously adhered to by DeepSeek until the recent financing rumors. Even now, although the first "no" has been breached, DeepSeek is still upholding the latter two "nos" in its investor search.

Recently, besides DeepSeek's financing maneuvers and valuation fluctuations, there have been numerous market rumors about capital being rebuffed by Liang Wenfeng.
Among them, the negotiations between DeepSeek and Alibaba and Tencent have been widely discussed.
Rumors about these two internet giants discussing investments in DeepSeek began to surface in large numbers around April 23. According to a report by Caijing, a person close to the deal at the time revealed that Tencent and Alibaba were expected to invest a total of $1.8 billion, with DeepSeek's valuation exceeding $20 billion.
However, by May, both companies were reported to have failed in the negotiations, not due to insufficient funds, but because they both sought to gain more influence over DeepSeek, which touched Liang Wenfeng's底线 (bottom line).
According to a report by Baijing Lab, negotiations between Alibaba and DeepSeek have broken down, with the core disagreement being Alibaba's desire to construct a closed-loop ecosystem for its AI strategy, while DeepSeek insisted on technological independence and rejected the conditions for ecosystem binding.
However, there is another perspective in the market regarding this news: according to a report by National Business Daily on May 9, market sources revealed that Alibaba may not have engaged in negotiations at all.
Additionally, Bloomberg reported that a person familiar with the matter said Tencent proposed to subscribe for up to 20% of DeepSeek's shares in this round of financing. However, this was also not accepted by Liang Wenfeng.
Subsequently, a report by The Information stated that Liang Wenfeng would personally contribute up to RMB 20 billion, accounting for 40% of the total planned financing for this round. This news further cemented Liang Wenfeng's resolute stance of not ceding control in this round of financing.
The report also disclosed that Tencent had altered its investment approach. A person familiar with the matter said, "Tencent will contribute RMB 6 billion, accounting for about 2% equity."
By rejecting the olive branches extended by internet giants and leveraging his own funds to dominate the financing, Liang Wenfeng's financing logic has consistently remained unrelated to monetary gains.
DeepSeek is not financially strained; behind it stands High-Flyer Quant, a quantitative trading company founded by Liang Wenfeng.
According to data from Simuwang, in 2025, High-Flyer Quant's average return rate soared to as high as 56.6%, with a management scale surpassing RMB 70 billion. Industry insiders estimate that High-Flyer Quant alone brought Liang Wenfeng over $700 million in income in 2025, which virtually constitutes the "arsenal" for DeepSeek's independent operation.
The reason Liang Wenfeng chose to "loosen up" on financing this time is that DeepSeek's technological foundation—its talent pool—has recently undergone significant upheaval.
From the end of 2025 to the beginning of 2026, key contributors to the DeepSeek-V2 architecture, such as Luo Fuli, the first-generation core author of large language models Wang Bingxuan, and R1 core author Guo Daya, departed from DeepSeek to join other companies.
What preoccupies Liang Wenfeng the most is not securing more financing, forging collaborations with internet giants, or attracting more powerful capital... but how to retain his core technical personnel amid the competitive high-salary "poaching" tactics of rivals.

Therefore, his current financing endeavors may be aimed at providing a relatively fair valuation for the company through external capital, making the stock options held by DeepSeek employees more enticing in terms of pricing.
In the technical report for DeepSeek's latest product, DeepSeek-V4, there is an extensive list of author acknowledgments. Out of approximately 270 individuals in the research and engineering team, only 10 left during the development period. Correspondingly, the turnover rate of technical R&D personnel is less than 4%, meaning Liang Wenfeng has successfully retained 97% of his employees.
These individuals will continue to follow Liang Wenfeng's vision and embark on a unique path.
2. Observing Liang Wenfeng's "Counter-Trend" Thinking Through DeepSeek-V4
Despite the overwhelming details about DeepSeek's financing, neither Liang Wenfeng nor DeepSeek has publicly responded to them. Instead, on April 24 during this period, the company quietly unveiled the industry's long-awaited new product, the DeepSeek-V4 preview version, without any pre-heating.
According to DeepSeek's introduction, DeepSeek-V4 boasts an ultra-long context of one million characters, achieving domestic and open-source leadership in Agent capabilities, world knowledge, and reasoning performance.
What sparked even more market discussion was the pricing of this product.
Less than 48 hours after the product launch, DeepSeek announced an API price adjustment. The announcement revealed that the input cache hit price for all DeepSeek-V4 APIs was slashed to one-tenth of the initial launch price, with V4-Pro additionally offering a limited-time 2.5% discount, bringing the input cache hit price for one million Tokens down to RMB 0.025, setting a new global low for large model prices.
This pricing strategy has drawn attention because the core advantage of DeepSeek-V4—its ultra-long context—is extremely computationally intensive. It is understood that standard Transformer attention requires each token to be computed once with all previous tokens. Expanding the context from 8K to 1M results in a square-level increase in computation.
However, DeepSeek can still maintain a low-price strategy under such circumstances, which is no small feat.
If we compare it to the latest product released by OpenAI around the same time, GPT-5.5, the affordability of DeepSeek's pricing becomes even more apparent.
Taking API prices as an example, GPT-5.5's standard quoted price is $5 per million Tokens for input and $30 per million Tokens for output; DeepSeek-V4-Pro's price during the 2.5% discount promotion is RMB 0.025 per million Tokens for cache hit input, RMB 3 per million Tokens for cache miss input, and RMB 6 per million Tokens for output.
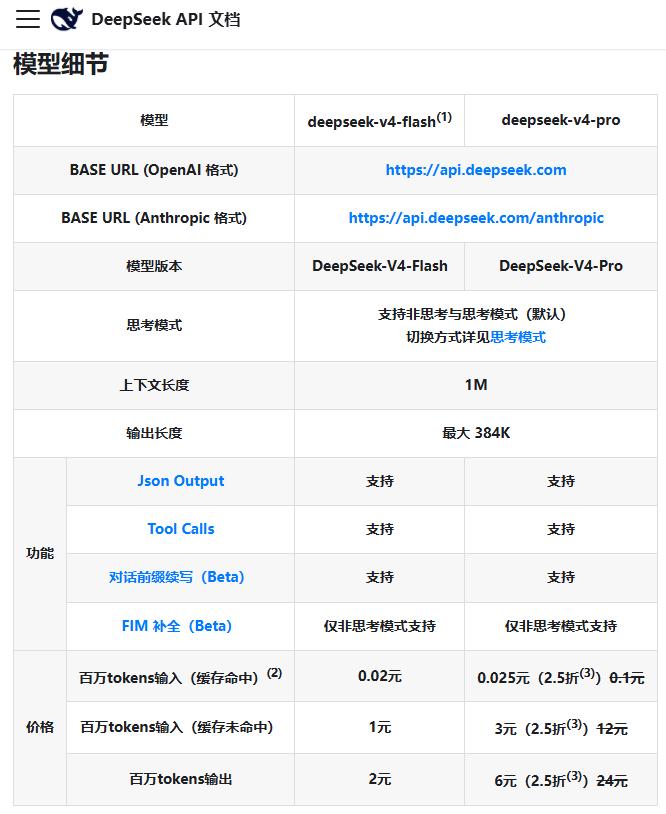
Image source: DeepSeek official website
If we roughly convert using an exchange rate of $1 ≈ RMB 7.2, GPT-5.5's output price is approximately RMB 216 per million Tokens, more than 30 times the promotional price of DeepSeek-V4-Pro.
On the other hand, as computing costs gradually escalate, price hikes and fees have become realistic choices that large model companies have to make.
For example, GPT-5.5's price is twice as expensive as GPT-5.4 overall; Zhipu AI announced its third price increase plan since the beginning of the year in early April, raising prices by 10% while releasing its new flagship model, GLM-5.1; Kimi increased its API input price from $0.60 to $0.95 per million Tokens when releasing K2.6 in late April, a 58% increase.
On one side is the overall industry trend of price hikes, and on the other side is Liang Wenfeng and DeepSeek's counter-trend price reductions. The scene seems strikingly similar to two years ago when the highly cost-effective DeepSeek unexpectedly sparked a price war in the large model industry.
The reason for saying "unexpectedly" is that Liang Wenfeng did not intend to spark a price war. He once said in an interview with 36Kr that he was very surprised by the industry price war, "We were just doing things at our own pace and then setting prices based on costs."
However, just like two years ago, this time DeepSeek-V4 also did not intend to spark a price war. Its ability to reduce prices against the trend and control costs well is achieved through technological innovation.
Among them, the core breakthrough in cost reduction for DeepSeek-V4 lies in the improvement of compressed attention mechanisms.
It designed two compressed attention mechanisms: Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). The former is responsible for accurately locating key details, while the latter is responsible for grasping the overall context.
DeepSeek alternates between the two attention mechanisms in each layer during forward propagation, reducing the attention computation complexity in the Prefill stage from O(N^2) to approximately linear O(N*k) and linearly compressing the KV Cache in both the Prefill and Decode stages, reducing the pressure on video memory and bandwidth during inference.
After these layer-by-layer reductions, the cache size has been compressed by over 90%.

Besides this, DeepSeek has many other ways to reduce costs.
For example, it relies on a dynamic sparsity selection mechanism to forcibly truncate complexity to constant-level operations. With a 1M-long context, the single-token inference FLOPs of V4 Pro have dropped to 27% of those of the previous generation V3.2; its self-developed TileLang language enables parallel GPU computation and network transmission, pushing hardware utilization to the limit; for agent tasks, it uses special markers to replace additional small models, directly reusing the main model's KV Cache to perform some auxiliary tasks in parallel, minimizing inference costs.
"Our principle is not to lose money or make excessive profits. This price also includes a slight profit above cost," Liang Wenfeng responded to the media after DeepSeek-V2 sparked a price war, which also applies to DeepSeek-V4.
For Liang Wenfeng, the pricing strategies of other companies do not serve as a reference point. He only focuses on his own technological logic and sets prices suitable for DeepSeek.
3. Liang Wenfeng: Unhurried in Product Iteration and Commercialization
Is Liang Wenfeng in a hurry for product iteration and commercialization?
If you've endured the seemingly endless five-month wait from DeepSeek-V3.2 to DeepSeek-V4, the answer might be crystal clear.
During these five months of DeepSeek's hiatus, mainstream model companies in the US market, such as OpenAI, Anthropic, and Google Gemini, along with their Chinese counterparts, Alibaba's Tongyi Qianwen, ByteDance's Doubao, Tencent's Hunyuan, and Xiaomi's MiMo, have all rolled out or updated multiple models. On average, a new model or update was released every 2.8 days.
For AI large model companies, commercialization is a topic that's inextricably linked with product iteration. Companies are constantly worried that their technology will be overtaken, causing them to lose their commercial edge and, consequently, their appeal in the capital markets.

DeepSeek, which took its time to iterate, found itself being surpassed during this period. In benchmark tests conducted by the international market research firm Artificial Analysis, DeepSeek-V3.2's performance once lagged behind that of flagship models from OpenAI, Anthropic, Google Gemini, Alibaba Tongyi Qianwen, Yuezhi's Kimi, Zhipu GLM, and MiniMax.
More critically, after the "lobster craze" swept through the industry, the demand for Agents surged, with coding capabilities becoming the focal point for various companies. However, DeepSeek-V3.2 appeared relatively outdated in both Agent and coding capabilities.
But regardless of how other companies' models iterate or how high the market's disappointment with DeepSeek runs, these factors seem to have little bearing on Liang Wenfeng's and DeepSeek's development pace.
Liang Wenfeng holds his own steadfast beliefs. In his rare interviews, he repeatedly emphasizes the goals of "achieving Artificial General Intelligence (AGI)" and "not pursuing short-term commercialization."
Pushing the underlying technology of large models to new heights is Liang Wenfeng's unwavering pursuit.
Upon its release, DeepSeek-V4 significantly narrowed the gap in Agent capabilities compared to its predecessors.
In its announcement, DeepSeek stated that DeepSeek-V4-Pro has reached the current pinnacle among open-source models in Agentic Coding evaluations and performed exceptionally well in other Agent-related assessments. It outperforms other open-source models by a wide margin in world knowledge evaluations. In mathematics, STEM, and competitive coding evaluations, it surpasses all currently publicly evaluated open-source models and achieves results on par with the world's top closed-source models.
One of the core capabilities upgraded in DeepSeek-V4—context—is vital for Agent tools to comprehend and remember vast amounts of text. Both models released by DeepSeek this time can support a context length of 1 million tokens, significantly enhancing the Agent's ability to read text and retain more details.
According to tests conducted by Dianping, when a random excerpt from "The Three-Body Problem" was inserted into "A Dream of Red Mansions" and sent to DeepSeek-V4 to identify anomalies, it pinpointed them in just a few seconds.
Another detail that underscores Liang Wenfeng's and DeepSeek's attitude of not chasing global leadership but instead pushing underlying technology to its limits is their acknowledgment of gaps with competitors in product announcements.
It stated that currently, DeepSeek-V4 has become the Agentic Coding model used by the company's internal employees. According to evaluation feedback, the user experience is superior to that of Sonnet 4.5, and the delivery quality is close to that of Opus 4.6's non-thinking mode. However, there is still a certain gap compared to Opus 4.6's thinking mode.
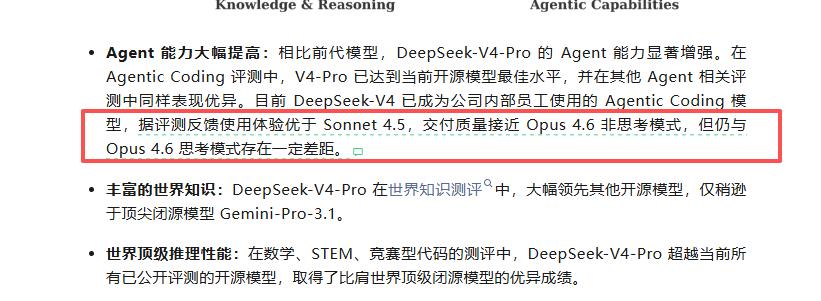
Image source: DeepSeek's official WeChat public account.
Regarding the long-discussed multimodal capabilities in the AI industry, DeepSeek is also taking a measured approach.
Today's DeepSeek-V4 still lacks native multimodal capabilities. Market news only reveals that its iterative version, V4.1, set to be released in June this year, will incorporate image and audio understanding and processing capabilities, but output will still be confined to text generation.
Various signs indicate that unless the technical level of the product is pushed to its limits, external market dynamics and opinions will not sway Liang Wenfeng's research and development pace and objectives.
In a 2024 interview with 36Kr, Liang Wenfeng expressed the following viewpoint: "For the past thirty years, we have solely focused on making money and neglected innovation. Innovation is not solely driven by commerce; it also requires curiosity and a desire to create."
Two years have passed, and Liang Wenfeng rarely makes public statements anymore. However, it is evident that his stance against letting commerce drive innovation remains unchanged to this day.
(The header image of this article is sourced from DeepSeek's official WeChat public account.)
-
![]()
Is Momenta’s “Physical AI” Premium Justified?
-
![]()
Memory Prices Soar, Budget Phones No Longer Just Watered-Down Flagships
-
Who Defines the Value of 'Office Environment' in the AI Era?
-
Why Did Insta360’s Market Cap Spike and Then Retreat After Taking on DJI as a Benchmark?
-
![]()
DeepSeek Interview Shatters the 'White Moonlight' Illusion of Former Huawei 'Genius Teen'
-
Four-Week Net Sales Reach $38 Billion: Institutions Flee En Masse as Retail Investors Continue Buying Spree
-
![]()
Dissecting 25 AI Startups with Over $50 Million in Series A Funding: The Top Three Areas Where Smart Money is Betting
-
![]()
Dissecting 25 Series A Financings Exceeding $50 Million: AI's Smart Money is Betting on These Three Directions