Wu Xinzhou Pioneers NVIDIA's Advancement Towards L4 Autonomous Driving with VLA Large Model Algorithm
 11/17 2025
11/17 2025
 554
554
In August 2023, amidst the fierce competition in China's L2+ intelligent assisted driving sector, which was intensifying with the expansion of assisted driving technologies into urban environments, Wu Xinzhou made a pivotal move. He left XPENG Motors to join NVIDIA. By January 2024, Tesla had launched its FSD V12 Beta end-to-end version, marking a significant milestone as intelligent assisted driving algorithms entered the 'end-to-end' era. Subsequently, China fully embraced end-to-end solutions, positioning itself as a leader in the global assisted driving market.
However, during this period, NVIDIA Autonomous Driving, under Wu Xinzhou's leadership, seemed to be overshadowed amidst the frenzy of end-to-end autonomous driving solutions coupled with self-developed high-end chips. Even at NVIDIA's GTC event in April, only a fleeting minute was dedicated to revisiting the well-trodden topics of vehicle-end solutions and cloud training hardware. Wu Xinzhou's dedicated GTC speech, while featuring VLM, lacked the novelty and forward-looking vision in its product roadmap that the industry had come to expect. 
At this year's October GTC, as highlighted in our previous article, 'NVIDIA GTC 2025: Three Pioneering Product Technologies in 6G Communications, Quantum Computing, and L4 Autonomous Driving,' Jensen Huang surprised the audience by dedicating five minutes to showcasing the key points and achievements of NVIDIA's L4 Robotaxi.
In a groundbreaking collaboration with Uber, NVIDIA announced plans to deploy 100,000 autonomous vehicles equipped with its solutions starting from 2027. Leading OEMs such as Lucid, Mercedes, and Stellantis, along with a dozen autonomous driving development companies, have already adopted NVIDIA's L4 software and hardware solutions.
Thus, it appears that Wu Xinzhou has successfully steered NVIDIA towards a new frontier in its quest for L4 autonomous driving dominance. Behind this renewed push lies not only NVIDIA's cutting-edge AI hardware but also a revolutionary new VLA software.
Many might wonder, why not opt for a world model? While world models represent the pinnacle of technological advancement, the two leading figures in this field, Li Feifei, are still in the demonstration phase, and Yann LeCun has recently departed from Meta. So, how can a fully realized world model be readily implemented?
The so-called world models currently under discussion are essentially models that attempt to linguify and graphitize the physical world through Large Language Models (LLMs), placing them in the same category as VLA. The truly sought-after world model, which implicitly represents the 3D world plus time, is still a work in progress in laboratories.
Recently, NVIDIA unveiled some insights and thoughts behind its VLA model named Alpamayo-R1. This model represents NVIDIA's innovative approach and practices for advancing L4 deployment, marking it as one of the most advanced directions in current technological productization.
Therefore, this article will delve into and share the intricacies of this VLA algorithm from three perspectives: the current structure and challenges of VLA, NVIDIA's L4 VLA algorithm architecture, and NVIDIA's L4 VLA data annotation and training methods.
Challenges of Current VLA Structures
Those familiar with our previous articles on VLA will undoubtedly recognize that VLA can comprehend and reason about the human world through language models, offering several advantages over purely end-to-end intelligent assisted driving:
- Enhanced safety through explicit counterfactual reasoning and runtime safety cross-checks and monitoring.
- Improved interpretability by providing human-readable decision rationales.
- Richer training signals by serving as verifiable rewards to enhance long-tail performance.
Several leading companies have applied VLM/VLA to autonomous driving. However, despite being labeled as VLA, many current implementations may essentially still be VAs:
- They predominantly operate reactively without explicit reasoning, making it difficult to generalize to ambiguous or long-time-domain scenarios that require counterfactual reasoning.
- Treating autonomous driving reasoning as a pure natural language processing (NLP) problem overlooks the fact that driving necessitates a deep understanding of 3D and physical space knowledge, including lane geometry, traffic rules, agent interactions, and dynamic constraints.
Therefore, NVIDIA's autonomous driving VLA model, Alpamayo-R1, adopts the following innovative methods:
- Developed a structured Chain of Causality (CoC) annotation framework that generates decision-based, causally linked reasoning traces. This framework supports scalable high-quality data generation through a hybrid process of human participation and automatic annotation.
- Adopted a diffusion-based action expert trajectory decoder using flow matching to efficiently generate continuous, multimodal trajectory plans that align with language reasoning outputs and meet real-time inference requirements.
- Employed a multi-stage training strategy based on the Cosmos-Reason VLM backbone. This strategy involves injecting action modalities for trajectory prediction, eliciting reasoning capabilities through supervised fine-tuning (SFT) on CoC data, and employing reinforcement learning (RL) to enhance reasoning quality, reasoning-action consistency, and trajectory quality.
Through these methods, the true potential of VLA is realized, enabling genuine reasoning and a true understanding of some 3D spatial knowledge for driving.
NVIDIA's L4 VLA Model Architecture
In essence, all VLAs are a form of end-to-end architecture, and NVIDIA's AR1 is no exception. The system processes multi-camera, multi-time-step observations as visual inputs, optionally enhancing them with speech-text inputs such as user commands and high-level navigation instructions. All inputs are tokenized into a unified multimodal token sequence, which is then processed by the Cosmos-Reason VLM backbone. 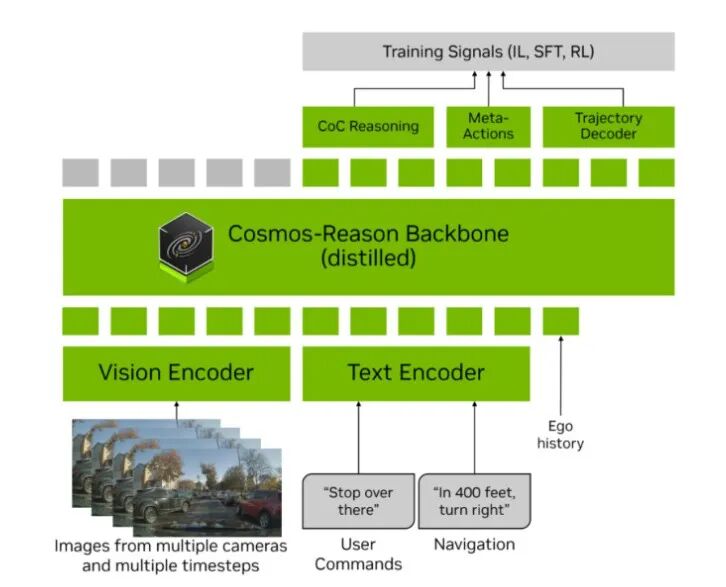
VLM Backbone: Cosmos-Reason is NVIDIA's proprietary VLM. In the AR1 VLA model, this VLM model has undergone fine-tuning through training on 24,700 video Visual Question Answering (VQA) samples focused on driving scenarios, transforming it into a driving Physical AI VLM.
Currently, VLM models are relatively accessible, but high-quality data remains scarce. NVIDIA's AR1 ensures that every action and behavior has explicit reasoning and explanation, necessitating such elements in the fine-tuning training data.
Therefore, NVIDIA AR1 organized and annotated 24,700 driving videos along with question-answering reasoning to fine-tune this VLM. The 24,700 videos include descriptions and question-answering reasoning, representing a massive workload, which we will delve deeper into later when discussing NVIDIA's data annotation methods. 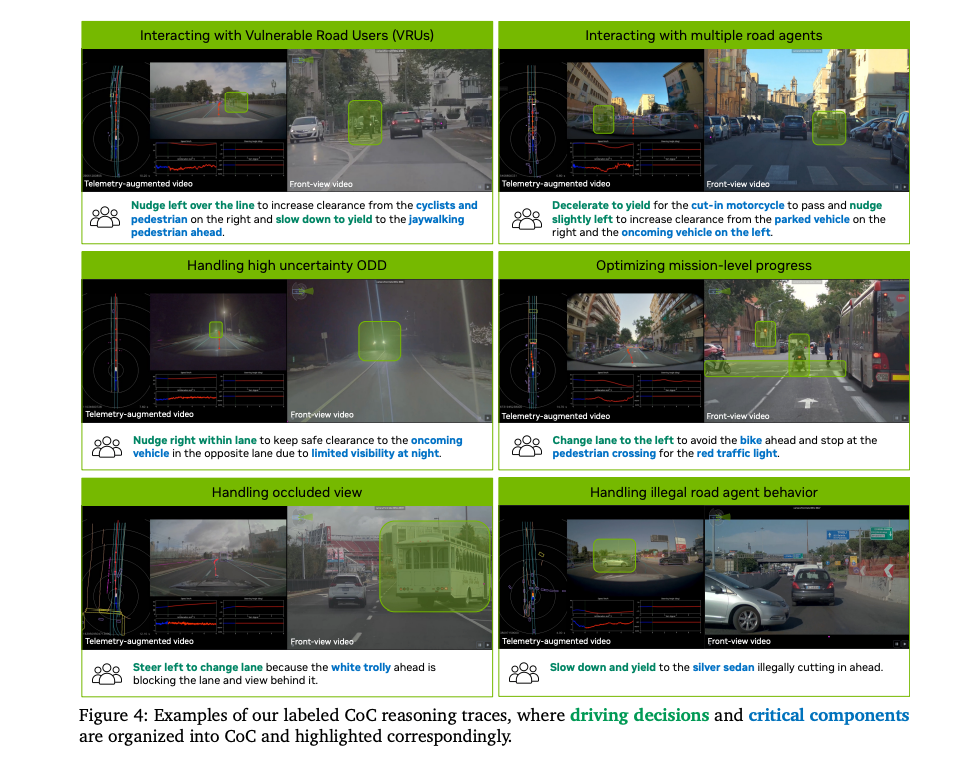
With this specially tuned VLM, the other two critical tasks for VLA are encoding the input visuals and language into the VLM and decoding the VLM's output into motion trajectories.
Input Visual Encoding: For autonomous driving, computational costs are a significant constraint. Therefore, the visual encoder in the VLM must produce as few tokens as possible while retaining relevant semantic information for onboard deployment. NVIDIA AR1 has researched and adopted the following methods:
- Single-camera single-frame encoding: For example, for a 448x280-pixel image, this process generates 160 tokens per image. Since autonomous vehicles typically use 6 to 10 cameras, the number of tokens generated by single-image tokenization increases linearly with the number of cameras, hindering real-time inference.
- Multi-camera single-frame synchronous encoding: A 3D inductive bias method can be employed to decouple the number of tokens from the number of cameras and resolution. For instance, with a 7-camera setup, only 288 tokens are needed to represent observations at a single time step.
- Multi-camera video encoding: Directly encoding camera observation sequences from multiple time steps achieves a compression rate of up to 20 times (compared to single-image tokenization) while maintaining or even improving downstream driving metrics.
Obviously, NVIDIA AR1 should have applied multi-camera synchronous encoding to save computational requirements. After all, onboard deployment makes computational power and real-time performance the biggest constraints. Being able to compute quickly and accurately is an AI requirement.
Of course, there is also the speech-text modality, which is easily handled by the VLM since it is native to LLMs.
Output Trajectory Decoding: NVIDIA AR1 combines discrete trajectory tokens (learned internally within the VLM) with an action expert's strategy.
Generally, the VLM within a VLA outputs position trajectories based on the vehicle. However, training models in this raw position (x, y) waypoint space are susceptible to sensor noise, requiring subsequent smoothing and potentially introducing more inaccuracies.
Therefore, NVIDIA AR1 proposes an action representation based on unicycle dynamics control. x and y represent positional waypoints in the bird's-eye view (BEV) plane, θ represents the yaw angle, v represents speed, k represents curvature, and a represents acceleration. These parameters are mapped into the VLM, sharing a common set of tokens.
Finally, the action expert uses the Flow Matching framework, similar to the Diffusion model shared in our previous article. Both aim to transform noise into structured data, ultimately outputting vehicle control information for autonomous driving. 
This approach enables reasoning and trajectory to share a common token space, allowing the VLM to tightly couple causal explanations with vehicle behavior through standard next-token prediction.
Meanwhile, Flow Matching provides computational efficiency, generating continuous trajectories much faster than autoregressive sampling of 128 discrete tokens, thus achieving real-time inference.
NVIDIA's L4 VLA Data Annotation and Training Methods
Therefore, NVIDIA's AR1 VLA model integrates the VLA components more tightly, resembling a pipeline from raw materials to packaging and shipping on a single production line.
With this pipeline, how to train and organize the raw materials (data) becomes the most crucial factor for the model's success.
The shared token space for reasoning and trajectory in NVIDIA AR1 necessitates changes in the data structure used for previous training. Reasoning data must be closely related to self-trajectory to enable the reasoning VLA model to explain the reasons for driving actions and improve its trajectory performance.
Data generation involves annotation. 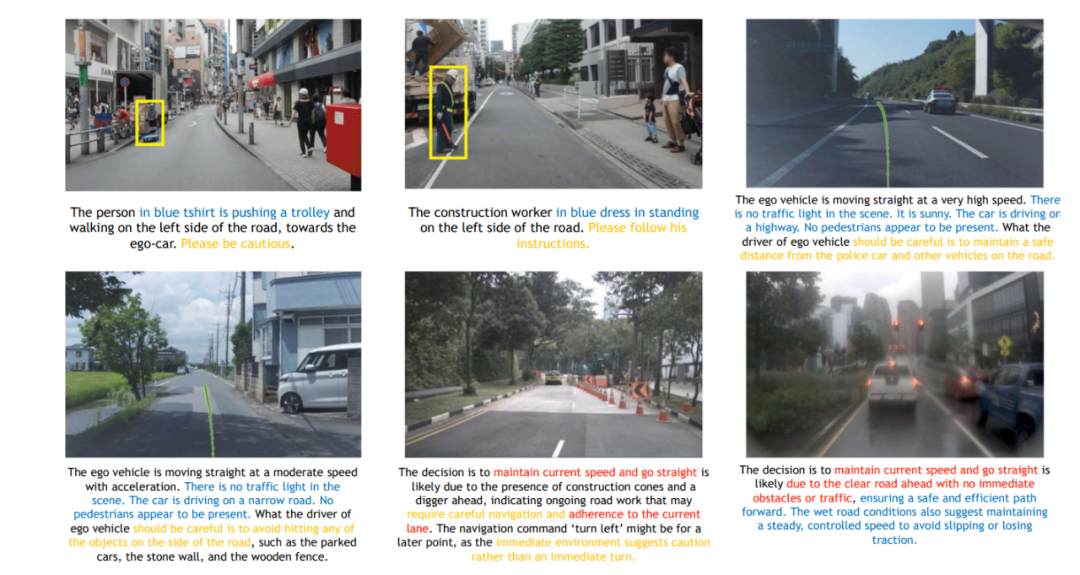
The annotation framework for Alpamayo-R1 model training decomposes each data sample into three structured components: driving decisions, causal factors (key components), and combined reasoning traces.
- A classification table for autonomous driving decisions defines the various longitudinal and lateral driving actions that the model must learn, along with their specific meanings.

- Key components are the 'evidence' that the model must reference when generating causally grounded explanations (CoC reasoning).

- Finally, the output combined reasoning traces emphasize how to linguify and organize driving decisions and key scenario components into coherent, causally logical explanations after they have been identified.
With these rules in place, and to ensure the high quality and practicality of the training data during annotation, the following considerations must be made:
- Causal coverage and causal correctness: This is to achieve annotation economy by focusing on the most critical and direct factors. For example, if a car stops, it is because the preceding vehicle braked (proximate cause), not because there is a red light ahead (background condition).
- Decision minimization: Ensure that new reasoning trajectories are generated only when decisions change, thereby improving data efficiency and the model's attention focus.
With these three structured component rules and methodologies for annotation, the next step is annotation itself.
However, before annotation, it must be determined when to mark these reasoning data. Not every video clip is worth annotating; annotation is triggered only at moments when a clear causal link can be established between observable factors and the vehicle's subsequent decisions. Therefore, data management is a critical aspect of the data annotation framework, involving the identification of these key reasoning moments.
Each raw data clip in NVIDIA AR1 contains 20 seconds of data and can generate multiple training samples (since 2 seconds of history are used to predict 6 seconds of the future in both training and evaluation). 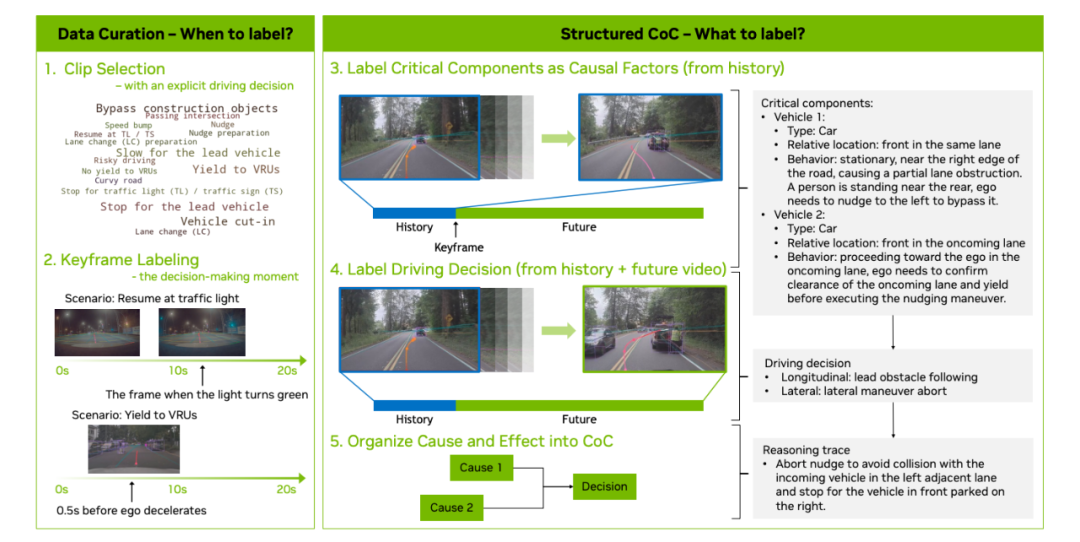
After obtaining the video data, NVIDIA AR1 employs both manual and automatic annotation.
Manual annotation follows a two-stage process:
- Stage I (0-2 s): Identify key components within the observable historical window to prevent causal confusion.
- Phase II (0-8 s): Make the first driving decision after selecting key frames and write CoC reasoning traces, citing only the causal factors identified in Phase I. We have implemented a rigorous QA process to maximize annotation quality.
Automatic Annotation: Utilize state-of-the-art VLMs (such as GPT-5 (OpenAI, 2025)) for offline automatic annotation. This process distills world knowledge into structured CoC annotations. The automatic annotation VLM is prompted to use 2 seconds of historical video to identify key components.
This forms the most critical data for training. Only with data can we feed it into model training.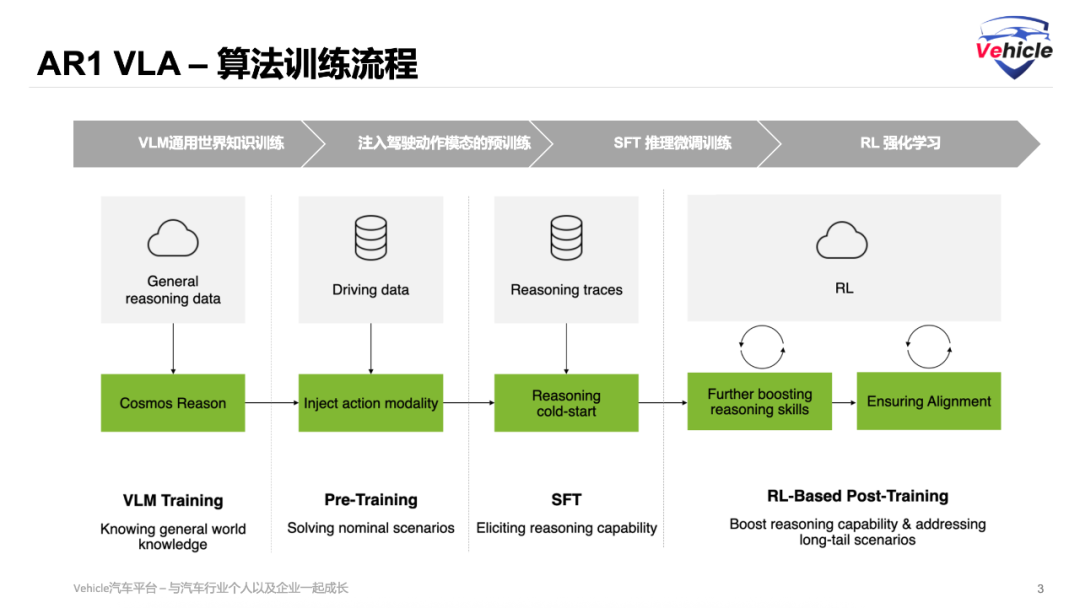
The training of current VLA models can be considered a unified standard, as a similar training process was shared in the previous article 'Revealing XPENG's Autonomous Driving 'Foundation Model' and 'VLA Large Model'.
VLM training is similar to general-purpose VLMs and current multimodal large models, so it will not be discussed here.
First, there's Pre-Training with Injected Action Modality. This phase corresponds to the initial pre-training stage, where the Visual Language Model (VLM) is trained to predict vehicle control outputs. To achieve this, it's essential to pair the model with an action expert, leveraging the flow matching technique mentioned earlier. By doing so, we construct an initial Visual Language Action (VLA) model capable of executing and predicting driving trajectories.
Next, we have SFT for Enhanced Reasoning Capability. This step aligns with Supervised Fine-Tuning (SFT), aiming to bolster the model's reasoning prowess. The goal is to enable the model to generate causally grounded explanations that justify driving decisions. For this purpose, we utilize the previously mentioned 24,700-instance CoC dataset for supervised fine-tuning.
As a result, the VLA can now produce causally sound explanations, allowing it to make interpretable and improved driving decisions.
Finally, we employ RL Post-Training with Reinforcement Learning. In this phase, a reward model is constructed to reinforce behaviors that align with human preferences. NVIDIA AR1 harnesses feedback from large reasoning models to refine the quality of reasoning, ensuring that reasoning trajectories are in harmony with the actions actually executed. The ultimate VLA model thus exhibits interpretable and safe driving behaviors while optimizing the overall quality of driving trajectories.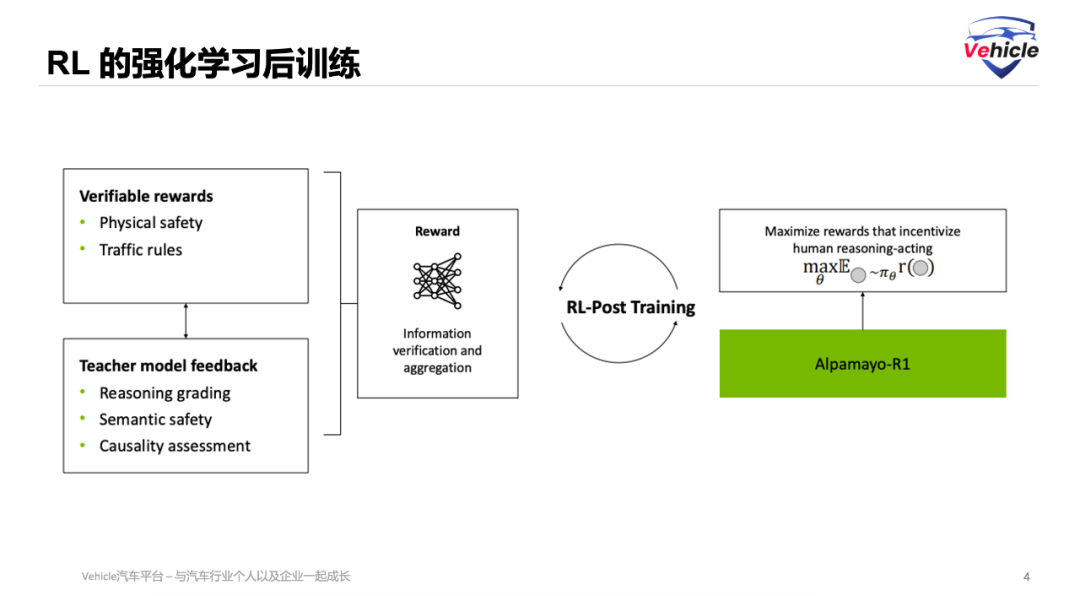
To evaluate reasoning quality, we leverage large reasoning models for scoring. DeepSeek-R1 serves as a reasoning critic, providing scalable and high-quality feedback on the reasoning traces generated by the VLA. This process assesses behavioral consistency and the quality of causal reasoning, encouraging the model to generate reasoning that not only accurately describes driving behavior but also maintains causal integrity.
Dataset CoC-Action Consistency: The CoC-Action Consistency reward mechanism ensures the model's interpretability and reliability. It does so by performing a strict, rule-based matching between the model's linguistic output (reasoning) and its physical output (actions). This step is crucial for achieving trustworthy autonomous driving.
Regarding Low-Level Trajectory Quality, or Output Motion Control, we ensure that the generated motion trajectories are physically feasible, comfortable, and safe. This involves three main aspects: the smoothness of the trajectory curve, which should mimic human driving; collision penalties to discourage accidents; and jerk penalties to penalize sudden or uncomfortable movements. These criteria guide the model's learning towards human-like, safe, and comfortable motions.
With these steps, the construction of the entire VLA is essentially complete. Subsequent model upgrades will focus on repairs and optimizations based on feedback from extreme scenarios.
Epilogue
Wu Xinzhou is undoubtedly a talented individual. Joining NVIDIA at a time of fierce competition in the L2+ market, he faced significant challenges in making substantial progress. However, he has now carved out an L4 battlefield using the most advanced technologies available, effectively marking a new phase in his career.
For algorithms, the VLA represents the optimal solution for achieving the productization of autonomous driving in the current landscape, where large language models are mature, yet spatial intelligence remains largely in the laboratory stage.
In any case, data and data processing capabilities have emerged as the core of artificial intelligence algorithm software.
References and Images
Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail - NVIDIA
*Reproduction or excerpting without permission is strictly prohibited-*
-
![]()
Hunan’s Wealthiest Entrepreneur Eyes Comeback with Apple’s Foldable iPhone
-
![]()
Planning to Secure 1.055 Billion Yuan to Propel AR Optics Forward! Lante Optics Receives Green Light for Private Placement on the Science and Technology Innovation Board
-
![]()
MiniMax: At the Heart of the AI Maelstrom
-
![]()
Securing 600 Million Yuan in Funding: This AR Optics Company Steps into the Limelight!
-
![]()
From a 706% Surge to a $340 Billion Market Cap Plummet: Has MiniMax's Moment Passed?
-
![]()
High Demand, Low Stock Price: Can the Emotional Companion Robot Ease UBTECH’s Worries?
-
![]()
Why Does Yin Qi, Who 'Doesn't Listen to Advice,' Insist on Making AI Agent Smartphones? | Interview with Jieyue Xingchen
-
![]()
AI-Generated Code Reveals Surprise That Thrills China