Switch Revolution in the Era of AI Super Nodes
 03/31 2026
03/31 2026
 548
548

The parameter scale of AI large models continues to grow, and the physical limits of single-card computing power and memory capacity are forcing the continuous expansion of AI training cluster scales. In this AI computing power arms race, network performance has long been the key to determining the efficiency of cluster computing power release. For AI models with ultra-large parameter scales, higher network bandwidth can directly and significantly reduce the completion cycle of model training.
01
The Technical Foundation for AI Computing Power Release: RDMA
To break through the network performance bottlenecks of AI clusters, RDMA technology has become the industry's recognized solution, and its origins trace back to addressing communication bottlenecks in the era of GPU general-purpose computing.
GPU Direct RDMA is a hardware-software collaborative innovation technology jointly developed by Nvidia and Mellanox in 2009. At that time, GPUs had shifted from graphics rendering to general-purpose computing (GPGPU), becoming the core accelerators for HPC. Although GPU computing power was continuously improving, data transmission between GPUs across different nodes in a cluster still relied on CPUs, creating communication bottlenecks. As a result, the advantages of GPU computing power were hindered, leading to low overall cluster efficiency. NVIDIA clearly recognized the need to solve this problem and began exploring solutions for direct GPU-to-NIC communication with partner Mellanox, initially through GPU Direct over InfiniBand. This technology gradually matured and was officially released in 2012 with the Kepler architecture GPU and CUDA 5.0, named GPU Direct RDMA.
Prior to this, traditional data center data transmission was always constrained by the inherent limitations of the TCP/IP architecture. In traditional transmission schemes, memory data access and network data transmission belong to two separate semantic sets, with data transmission heavily reliant on CPUs: applications first request resources and notify sockets, then kernel-mode drivers complete TCP/IP packet encapsulation, and finally, data is sent to the peer via NICs. Data at the sending node undergoes multiple copies through Application Buffer, Socket Buffer, and Transport Protocol Buffer, and upon reaching the receiving node, an equal number of reverse memory copies are required to complete decapsulation before being written into system physical memory.
This traditional transmission method introduces three issues: first, multiple memory copies result in high transmission latency; second, TCP/IP protocol stack packet encapsulation relies entirely on driver software, placing a high CPU load and making CPU performance a bottleneck for transmission bandwidth and latency; third, frequent context switching between user mode and kernel mode in applications further amplifies data transmission latency and jitter, severely restricting network transmission performance.
RDMA (Remote Direct Memory Access) technology emerged precisely to address these pain points. By leveraging host offloading and kernel bypass technologies, it enables reliable direct memory-to-memory data communication between two applications over a network: after an application initiates data transmission, RNIC hardware directly accesses memory and sends data to the network interface, while the receiving node's NIC can write data directly into the application's memory, all without deep involvement from CPUs or kernels.
With these characteristics, RDMA has become a core interconnection technology in fields with stringent requirements for low latency, high bandwidth, and low CPU usage, such as high-performance computing, big data storage, and machine learning. The standardization of RDMA technology protocols also provides a unified specification for interoperability among devices from different vendors, driving the technology from concept to large-scale commercial use. Currently, the mainstream RDMA implementation schemes fall into three categories: InfiniBand protocol, iWARP protocol, and RoCE protocol (including RoCE v1 and RoCE v2).
As AI model parameters surge from billions to trillions, while single-GPU memory capacity continues to expand, data transmission efficiency between servers has become a critical factor determining system scalability and the feasibility of model training objectives. The value of RDMA technology has become increasingly prominent—efficient access to other servers' memory and resources directly determines system scalability, while the ability to directly access remote memory directly enhances overall AI model training performance. It is through RDMA technology that data can quickly reach GPUs, ultimately effectively shortening Job Completion Time (JCT).
02
The Battle Between InfiniBand and Ethernet
In the evolution of AI computing networks, inter-cabinet interconnection initially adopted mature Ethernet solutions. However, as demand for low latency escalated, InfiniBand quickly rose to prominence due to its performance advantages. As the representative of native RDMA protocols, InfiniBand, driven by NVIDIA subsidiary Mellanox, offers extremely low transmission latency below 2 microseconds while achieving zero packet loss, making it the performance leader in the RDMA field.
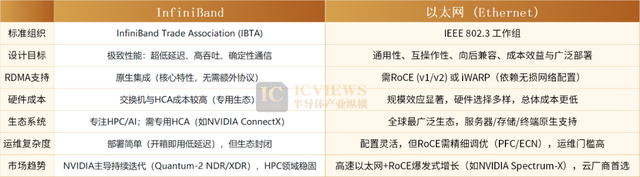
To migrate InfiniBand's RDMA advantages to the Ethernet ecosystem, the RoCE protocol was introduced. RoCE v1 could only operate within Layer 2 subnets, while RoCE v2 enabled cross-subnet routing through IP/UDP encapsulation, greatly enhancing deployment flexibility. Although its latency of approximately 5 microseconds remains higher than native InfiniBand, it allows Ethernet to support the high-bandwidth, low-latency requirements of AI training.
To challenge InfiniBand's dominance in AI, industry giants including Broadcom, Microsoft, and Google jointly launched the UEC 1.0 specification in June 2025, aiming to reconstruct the Ethernet protocol stack to approach InfiniBand's performance, marking Ethernet's all-out counterattack against InfiniBand. The Ultra Ethernet Consortium (UEC) clarified that the UEC 1.0 specification provides high-performance, scalable, and interoperable solutions across the entire network stack, including NICs, switches, fiber optics, and cables, enabling seamless multi-vendor integration and accelerating ecosystem-wide innovation. The specification not only adapts to modern RDMA capabilities for Ethernet and IP but also supports end-to-end scalability for millions of devices while completely avoiding vendor lock-in.
Currently, domestic tech companies such as Alibaba, Baidu, Huawei, and Tencent have joined the UEC Alliance to jointly promote standard implementation. Beyond participating in global standardization efforts, domestic enterprises are also developing independently controllable horizontal scaling architectures, all targeting low latency and zero packet loss as core objectives, directly competing with InfiniBand's performance.
From an industry implementation perspective, the strengths and weaknesses of the two technical routes are clear. The RoCE v2 solution, built on Ethernet architecture, not only delivers RDMA's high bandwidth and low-latency transmission performance but also offers strong device interconnection compatibility and adaptability, with flexible deployment and significant cost advantages. Compared to InfiniBand, Ethernet-based RDMA solutions hold a huge advantage in low cost and high scalability.
Network availability directly determines the stability of GPU cluster computing power, and the AI boom is driving data center switches toward continuously higher speeds. The exponential growth of parameters in AI large models has led to a large-scale increase in computing power demand, but large clusters do not equate to high computing power. To compress training cycles, large-scale model training universally adopts distributed training techniques, with RDMA serving as the core for bypassing the operating system kernel and reducing inter-card communication latency. Currently, the mainstream implementations are the InfiniBand and RoCE v2 schemes. Among them, the InfiniBand scheme offers lower latency but higher costs, with a highly concentrated supply chain around NVIDIA. According to Dell'Oro Group predictions, Ethernet's market share in AI computing networks will officially surpass InfiniBand by 2027.
03
The Rise of Super Nodes Fuels a Golden Era for High-End Switches
As parameter scales of AI large models reach into the trillions, computing power demand has shifted from mere GPU stacking to full-dimensional system architecture reconstruction. Constrained by single-chip physical power density, interconnection bandwidth, and memory capacity bottlenecks, the marginal benefits of computing power growth continue to decline. Current research and engineering practices both indicate that system-level collaborative architectures (such as high-bandwidth domain interconnection) are the primary technical path to breaking through single-chip performance limits, with the fundamental motivation being that single-chip physical limits have become the core bottleneck restricting computing power development.
When model scales far exceed single-chip computing power and memory capacity, traditional distributed training faces challenges such as soaring communication overhead and sharply declining computing power utilization. Against this backdrop, integrating dozens or even hundreds of GPU chips into a unified computing unit through high-speed lossless interconnection technologies, forming an equivalent "supercomputer" externally, has become the globally recognized next-generation computing power architecture breakthrough direction for mainstream AI infrastructure vendors and research institutions.
The emergence of AI super nodes has opened up entirely new growth space for the switch market. Compared to traditional servers, AI servers add GPU modules and require efficient interconnection with servers and switches via dedicated NICs to complete high-speed communication between nodes. This adds a back-end network (Back End) layer to traditional AI server networking architectures, significantly increasing the number of network ports per server and directly driving demand across the entire industrial chain, including high-speed switches, NICs, optical modules, and fiber optic cables.
Meanwhile, large-scale super node deployments accelerate horizontal network architecture scaling (Scale out). Ultra-large cluster networking with tens of thousands, hundreds of thousands, or even millions of cards generates massive demand for high-speed switches. As AI model parameters continue to expand, cluster scales rapidly transition from hundred-card and thousand-card levels to ten thousand-card and hundred thousand-card levels, driving networking architectures to evolve from Layer 2 to Layer 3 and Layer 4, further widening the market gap for high-speed switches.
The rapid global development of the AI industry has imposed unprecedentedly stringent requirements on AI cluster networks regarding networking architecture, network bandwidth, and network latency, driving Ethernet switches—the core communication devices—toward continuous iterative upgrades in directions such as higher speeds, more ports, white-boxization, and optical switches. Ethernet's deep industrial foundation and vast ecosystem of vendors also provide room for its market share in AI networks to continuously rise. Although InfiniBand currently still dominates the AI back-end network market with mechanisms such as low latency, congestion control, and adaptive routing, as Ethernet deployment schemes continue to optimize and the Ultra Ethernet Consortium's ecosystem accelerates its perfection, Ethernet's market share will continue to climb, directly driving demand for Ethernet switches.
04
Full Industry Entry: Domestic and International Vendors Rush into the AI Switch Market
The immense market opportunities in AI switches have attracted comprehensive layout (global technology giants and domestic vendors alike), sparking a technical and market competition around AI switches that spans from chips to complete systems and from traditional equipment vendors to internet companies.
Among international giants, NVIDIA's layout (strategy) has been the most aggressive. Its Spectrum-x platform, an Ethernet solution optimized for hyperscale cluster scenarios, enabled NVIDIA to achieve a cross-border breakthrough in the traditional IT sector of switches in less than three years. Meanwhile, NVIDIA has fully shifted its next-generation Rubin AI platform to a CPO (co-packaged optics) architecture and announced its entry into mass production, turning CPO from a laboratory concept into the "standard configuration" for future AI data centers.
Broadcom also launched the world's first 102.4 Tbps switch chip, Tomahawk 6, last year. This series provides 102.4 Tbps of switching capacity on a single chip, doubling the bandwidth of current Ethernet switches on the market. Designed for next-generation scalable AI networks, Tomahawk 6 offers higher flexibility by supporting 100G/200G SerDes and co-packaged optical modules (CPO). It provides the industry's most comprehensive AI routing functions and interconnection options, aiming to meet the needs of AI clusters with over one million XPUs.
Domestic traditional equipment vendors have also quickly followed suit, launching flagship products one after another.
Huawei released two flagship products in 2025: the industry's highest-density 128×800GE 100T box-type Ethernet switch, CloudEngine XH9330, which breaks through AI cluster scale limits with its industry-leading high-density port design; and the industry's first 128×400GE 51.2T liquid-cooled box-type Ethernet switch, CloudEngine XH9230, which helps enterprises build green, energy-efficient, and ultra-large-scale all-liquid-cooled computing power clusters.
New H3C, a subsidiary of Unisplendour Corporation, took the lead in releasing the 1.6T intelligent computing switch, H3C S98258C-G, in 2024, supporting the All-Optical Network 3.0 solution. With single-port rates exceeding 1.6T and a total switching capacity of 204.8T, it can meet the communication needs of 32,000 AIGC nodes. Equipped with a self-developed intelligent computing engine, the product achieves latency as low as 0.3 microseconds and has been verified by international clients such as Google, becoming a core supplier for their OCS complete systems. Additionally, the company launched the world's first 51.2T 800G CPO silicon photonics data center switch, laying the foundation for technical iterations of its 1.6T products.
Ruijie Networks completed a demonstration of a 51.2T switch commercial interconnection solution based on CPO technology. With ultra-high integration, significant energy efficiency improvements, and maintainability design, this solution perfectly adapts to the high-speed interconnection needs of AI training and ultra-large-scale computing clusters, providing a feasible path for future 800G and 1.6T network upgrades. Its 51.2T CPO switch uses Broadcom's Bailly 51.2Tbps CPO chip, achieving 128 400G FR4 optical switching ports within a 4RU space, greatly enhancing device port density and bandwidth capacity. Its core highlight lies in co-packaging the optical engine and switching chip, significantly shortening electrical interconnection paths and reducing signal attenuation and transmission power consumption.
ZTE launched domestically produced ultra-high-density 230.4T frame-type switches and a full range of 51.2T/12.8T box-type switches, with industry-leading performance that has been commercially deployed at scale in hundred/thousand/ten thousand-card intelligent computing clusters across operators, internet, finance, and other fields.
In addition to traditional switch manufacturers, internet companies have also entered the field, initiating the process of self-developed switches and becoming a significant force that cannot be overlooked in the race.
Tencent initiated the research and development of CPO switches as early as 2022, launching and unveiling the industry's first 25.6T CPO data center switch—Gemini—in the same year. This product integrates a 12.8T optical engine, providing 16 800G optical interfaces, with the remaining 12.8T switching capacity provided through 32 QSFP112 pluggable interfaces on the panel.
ByteDance officially launched a 102.4T self-developed switch on its Volcano Engine to support the new-generation HPN 6.0 architecture, meeting the efficient interconnection needs of GPU clusters with hundreds of thousands of cards. This switch achieves full-port LPO support, deploying 128 800G OSFP ports within a 4U space.
Alibaba showcased its self-developed 102.4T domestic switch at the Apsara Conference, pioneering the application of 3.2T NPO technology in a new-generation domestic four-chip switch. This device integrates four 25.6T domestic switching chips into a single unit, with a total switching capacity of 102.4T. It can also smoothly evolve to a 409.6T platform by upgrading to 4×102.4T chips.
Compared to linear-driven pluggable optics (LPO), near-package optics (NPO) offer higher bandwidth density while reducing the requirements for the main chip's SerDes performance, which is more conducive to the development of the industrial ecosystem. Compared to co-packaged optics (CPO), NPO uses standard LGA connectors, retaining the open and decoupled characteristics of optical modules, avoiding the binding of the main chip and optical engine, and making it easier to be adopted by end-users.
05
Why are internet companies developing switches?
The fact that internet companies are developing their own switches is not coincidental but driven by both technological trends and market demands.
At the technological level, the development of white-box switches provides a foundation for internet companies to develop their own switches. White-box switches achieve decoupling of hardware and software, with hardware composed of open components and software freely selectable and customizable by users or third parties. They offer advantages such as high flexibility, high scalability, and low procurement and maintenance costs. They are now widely used in the networks of internet companies and operators, with an increasingly mature industrial ecosystem. Ruijie Networks, an early player in the white-box switch field, has deep cooperation with internet companies such as Alibaba, Tencent, and ByteDance, participating in the development of next-generation switches through the JDM (Joint Design Manufacturing) model. In 2024, it successively won bids for research and development from multiple leading internet customers, promoting the large-scale deployment of white-box switches in internet data centers. The decoupling characteristic of white-box switches significantly lowers the technical threshold for self-development and has become a key factor for large internet companies to reduce network construction costs.
At the market level, hyperscale data center operators face network requirements that are completely different from those of traditional enterprises. On the one hand, companies like Alibaba, Tencent, and ByteDance have server fleets numbering in the tens or even hundreds of thousands, demanding extreme scalability and operability from their networks. On the other hand, AI training clusters, especially those with tens of thousands of GPUs, have stringent customized requirements for low network latency and high bandwidth. Standardized products provided by traditional switch manufacturers find it difficult to fully match these personalized and extreme business needs, ultimately prompting internet companies to pursue self-development.
Self-developed switches not only deeply adapt to their own business scenarios, enabling customized optimization of network capabilities but also significantly reduce the total cost of ownership (TCO) for cluster construction. In the AI computing arms race, they allow internet companies to grasp the initiative in underlying network capabilities.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?