Financing for Embodied AI Surpasses 30 Billion Yuan, with Data ‘Water Sellers’ Leading the Profit Race
 04/17 2026
04/17 2026
 535
535
"Who is Vying for a Stake in This Multi-Billion-Yuan Market?"
Author | Jian An
Editor | Lu Xucheng
How fervent is China's embodied AI industry? According to incomplete statistics, the total financing since the beginning of the year has exceeded 30 billion yuan, with over 20 embodied AI companies each valued at more than 10 billion yuan. On April 16, Tashi Intelligence announced the completion of a $455 million financing round, marking the latest example of the current craze in embodied AI financing.
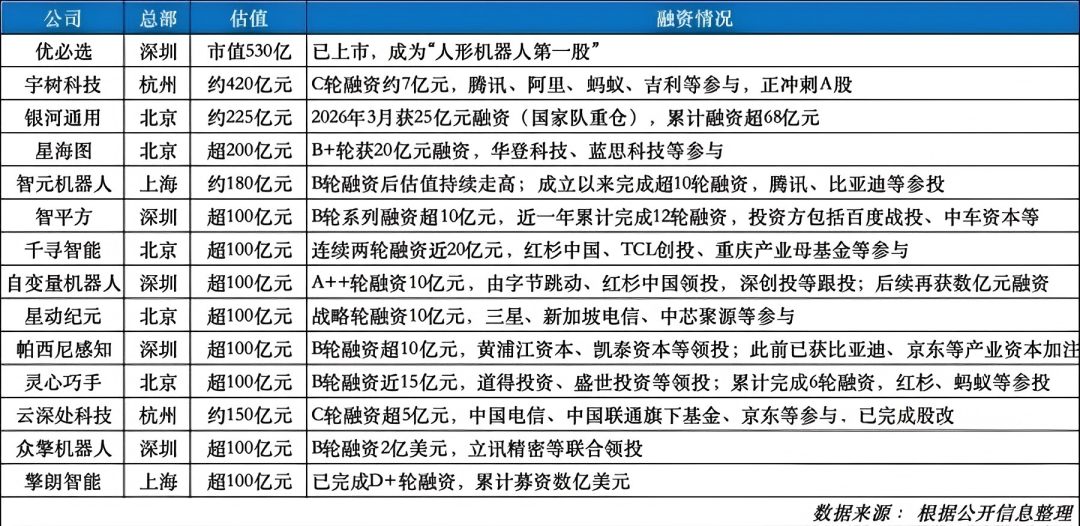
The majority of this over 30 billion yuan in financing has not been directed towards robot ontology (the physical robot body) manufacturing. Beike Finance previously reported that more than half of the year's investments have flowed into two key areas: the "embodied brain" (determining the robot's intelligence) and "dexterous hands" (enhancing its manual capabilities).

Data: The Bottleneck for Embodied AI
Currently, the primary challenge for robots is not their physical limitations but their lack of intelligence. In other words, manufacturing standalone robot hardware is no longer a significant hurdle; the key to unlocking the full potential of embodied AI models and accelerating industry growth lies in acquiring, processing, and utilizing large-scale, multimodal real-world data.
For now, most robots on the market are still at the imitation stage, capable of performing only single, standardized tasks. For instance, a robot may be able to fold clothes but not necessarily make a bed—it needs to learn each movement individually, lacking the ability to generalize like humans.
This single-point imitation capability falls far short of true general intelligence. The root cause of this limitation is the scarcity of high-quality physical interaction data. To overcome this bottleneck, the only viable approach is to feed models with massive amounts of data, enabling robots to develop generalization capabilities through countless interactions. This logic mirrors the evolutionary path of large language models, except that the data requirements differ significantly: large language models gain intelligence by processing decades of accumulated text data from the internet, while robots require vast amounts of multidimensional, complex data from the real physical world—including vision, touch, motion trajectories, spatial positions, etc.—to achieve intelligence.
Unlike autonomous driving, which operates in highly standardized scenarios with uniform national traffic rules and control logic, making data collection relatively straightforward, robots function in non-standardized environments such as homes, supermarkets, and factories. Every scenario, object, and action may vary, exponentially increasing the difficulty of data collection. The scarcity of data has become a bottleneck restricting the development of the entire embodied AI industry.
Yao Maoqing, Chairman and CEO of Mifeng Technology, revealed in interviews with media outlets, including Lansha Finance, that ChatGPT5 was trained on 10 billion hours of data, while embodied AI has only 500,000 hours of effective data—a staggering 20,000-fold gap. If language large models are akin to college students, embodied AI large models are still infants. Consequently, after securing funding, many robot companies prioritize buying and collecting data.
Data 'Water Sellers' Capitalize on Industry Pain Points
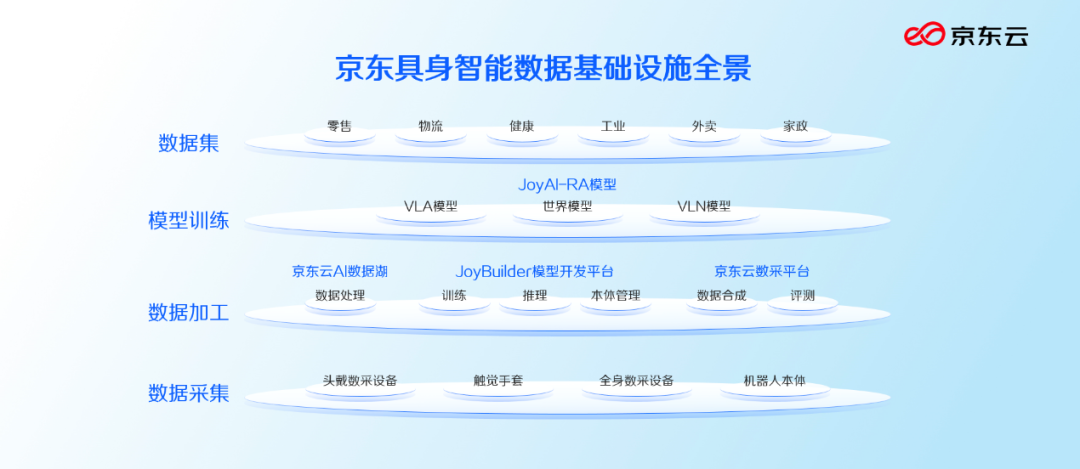
On April 16, JD.com and Zhiyuan Robotics' Mifeng Technology each unveiled a set of solutions for embodied AI data: JD.com globally launched the first embodied AI data infrastructure covering the full chain of "collection, storage, labeling, training, evaluation, simulation, and testing"; Mifeng Technology aims to build a "one-stop physical AI data service platform."

Source: Mifeng Technology CEO Yao Maoqing
The solutions announced by these two companies on the same day highlight a significant shift: the core bottleneck in the embodied AI industry has rapidly shifted from hardware (the "cerebellum") to high-quality training data driving intelligent decision-making (the "brain"). Insiders joke that companies selling robot bodies may not profit quickly, but data 'water selling' businesses might succeed first.
Source: Internet

Embodied AI Data Business Market Size Could Exceed 10 Billion Yuan
Data labeling is not a novel industry. Around 2014, with the rise of deep learning and recommendation algorithms, a wave of data labeling factories emerged.
Back then, they primarily served internet companies like Baidu and Douyin, training algorithms through manually labeled images and videos. Some film and gaming companies also utilized motion capture devices to collect human movement data for creating movie special effects and game animations. However, this early data could not meet the needs of robot training—traditional data labeling was mostly for content AI, with training logic not necessarily aligning with physical AI; film motion capture focused more on visual effects than enabling robots to replicate movements. Thus, many robot companies found that purchased data either lacked precision or mismatched scenarios, rendering it unusable for training embodied AI large models.
With a shortage of high-quality data on the market, some leading robot companies ventured into the data business themselves. For example, Zhiyuan Robotics spun off Mifeng Technology to build a one-stop physical AI data service platform; JD.com released embodied AI data infrastructure covering the full chain; and a wave of startups from autonomous driving and AI labs entered the sector.
Currently, robot data in the industry falls into three categories, each with distinct pricing and uses. Simulated data, generated in virtual environments, mainly supplements rare long-tail scenarios but lacks a large-scale circulation market and has opaque pricing. Non-physical data, collected via wearable devices capturing human movements, is lower-cost and more scalable, priced at roughly one-third to one-half of real robot data under steady-state conditions.
The highest precision data comes from real robots—data collected during actual robot operations, best suited for training models in deployment scenarios, with market prices ranging from 500 to 1,000 yuan per hour. This price may not seem exorbitant; at this rate, if the industry produces 1 million hours of effective data annually, the market size would be 1 billion yuan; if output rises to 10 million hours, the market size would reach 10 billion yuan. Yao Maoqing told Lansha Finance that the current physical AI data market is in a state of "buying as much as available," with supply falling short of demand.
Thus, JD.com and Mifeng both aim for multi-million-hour production capacity. Yao Maoqing stated that Mifeng will achieve multi-million-hour data production by 2026 and aims for 10 billion hours by 2030, jointly building the world's largest physical AI data ecosystem. JD.com also aims to construct the world's largest embodied AI data collection center, accumulating 10 million hours of human real-world video data within two years.
To rapidly scale production, both JD.com and Mifeng adopt asset-light crowdsourcing models, similar to the operational logic of platforms like Meituan and Didi, which build networks of riders and drivers.
JD.com introduced its self-developed wearable ultra-high-definition collection terminal, JoyEgoCam, planning to mobilize up to 600,000 people for "the largest data collection initiative in human history." This goal is achievable; JD.com had over 900,000 employees in 2025. With a word from founder Liu Qiangdong, JD's couriers and delivery riders could take on this income-boosting side job.

Source: JD.com Blackboard Report
Mifeng does not build large-scale data collection centers itself but maintains a team of 100–200 people to create "model rooms" for data collection and provide partners with unified standards, systems, and operational templates to attract regional partners. Partners build their own teams and procure equipment for data collection nationwide, while Mifeng handles order distribution, quality control, and client对接 (docking). This model allows Mifeng to rapidly expand production capacity while promoting Zhiyuan Robotics' hardware sales—partners need to purchase Zhiyuan's robots and equipment to collect real robot data.
Yao Maoqing revealed that achieving multi-million-hour high-quality embodied AI data requires deploying 10,000 collection terminals. Thus, Mifeng's partners alone could help Zhiyuan Robotics sell 10,000 more robots (Unitree Technology sold only 5,500 humanoid robots by 2025). This model resembles BYD's early strategy of primarily selling new energy vehicles to taxi companies.

Source: Mifeng Technology
However, this rapidly developing industry still faces numerous challenges. Non-standardized robot scenarios lead to inconsistent data collection quality; many regional data collection centers suffer from redundant collection and inefficient operations; non-physical data, while efficient to collect, inherently lacks precision; and the industry lacks unified data standards, making cross-platform reuse of data collected by different platforms difficult. Yet, these pain points also constitute barriers to entry for the data business.
Yao Maoqing stated that current embodied AI resembles large models in 2017–2018—a path is visible, but the full emergence of intelligence is not yet apparent. Achieving true general intelligence in robots will take at least four to five more years. This means industry demand for high-quality data will persist long-term and continue to grow.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?