Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’
 06/25 2026
06/25 2026
 449
449
Embercore AI has drawn significant attention, not only for its substantial funding rounds but also for its focus on the core challenge of continuous learning in robotics: data collection, simulation enhancement, evaluation, testing, and deployment feedback.

Recently, Embercore AI has been securing funding at an impressive pace.
In March, it raised 1 billion yuan in A++ and A+++ rounds. In May, Ant Group led a new round of financing, pushing its valuation to 2 billion US dollars. In June, another 1 billion yuan strategic financing round followed. At this rate in the embodied AI sector, it's impossible to overlook.
Many interpret this as capital once again targeting an embodied AI data company.
However, I believe the truly significant aspect is that capital is now valuing ‘data-driven learning systems.’ This marks a new signal for the industry’s advancement.
What is a learning system?
It’s not about simply feeding robots a batch of data. Instead, it involves collecting real-world experiences, enhancing them through simulation, evaluating and testing them, and then deploying them for feedback and correction. More directly, it’s about creating a closed loop for robots to ‘learn, test, correct, and learn again.’
Over the past two years, the focus on robots has shifted from their physical bodies to their ‘brains.’ Now, the emphasis is moving toward data and the robots' learning capabilities.
This is where Embercore AI truly stands out.
It doesn’t build robot bodies or directly create robot ‘brains.’ Instead, it focuses on the infrastructure behind robot learning: data, simulation, evaluation, and deployment feedback.
1. Embercore Offers a Data Loop
Those unfamiliar with Embercore AI might mistakenly view it as just a ‘data company,’ which is a limited perspective.
Traditional data companies operate on a straightforward model: Client A submits a request, and Company B collects, cleans, labels, and delivers the data. Once the project ends, the value creation essentially stops.
But in the era of embodied AI, Embercore presents a different narrative.
It aims to create a cycle: Human operations and industrial tasks in the real world are first collected as data. This data enters a simulation system and is amplified into more training scenarios. After model training, industrial-grade evaluations identify failure causes. When robots enter real-world scenarios, on-site feedback loops back into the next round of data production.

This is not just about providing data; it’s about delivering a closed-loop learning system.
This is why Embercore's 550 million yuan in orders in the first quarter is noteworthy. Behind these orders, it's not just model companies and robot companies purchasing data; it's the industry starting to pay for this closed-loop system.
Capital is also betting on this change.
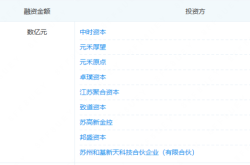
In the March funding round, industry players like New Hope and Aux Group participated, along with financial and state-backed capital such as Jiantou Huake and Guofang Innovation. In May, Ant Group led the round. In June, players like Zhongguancun Science City Fund, Giant Network, and Baotong Technology joined.
The funding comes from various sources, but the underlying logic is the same: Embodied AI cannot just invest in bodies and models; it must also invest in the data systems that support continuous robot learning.
When does an industry truly scale? Not when demos are hottest, but when people start paying for foundational capabilities.
2. Robots Lack Data Dividends
Why are companies like Embercore now coming into the spotlight?
The reason is simple: Robots lack natural data dividends.
Large language models have access to trillions of internet texts, and autonomous driving benefits from road test data from tens of millions of vehicles. Robots, however, face different challenges: real-machine data is expensive, slow, scattered, and limited by the number of physical units.
More troubling is that robots operate in the physical world. Factors like materials, light, and friction are hard to cover with a small amount of real-machine data, and changes are nearly infinite.
So, as embodied AI progresses, the bottleneck becomes clearer: Can high-quality data be stably obtained? Can evaluations be replicated? Can failures be turned into progress in the next round?

This is why Embercore AI founder Xie Chen always talks about ‘non-native data.’
Non-native data refers to data not entirely dependent on real robot bodies, such as human behavior data and simulation-synthesized data. Its value lies in bypassing the issue of insufficient real machines and scaling up robot learning materials.
But data is just the starting point; what’s truly valuable is closing the loop with human data, simulation data, and industrial evaluations.
This is where Embercore differs from ordinary data companies.
3. Is It Really the ‘NVIDIA of Data’?
Some like to call Embercore the ‘NVIDIA of Data.’
I think this is a bold claim and easily overhyped. But if you break it down, it’s not entirely unreasonable.
NVIDIA’s real strength isn’t just GPUs. GPUs are the entry point, CUDA is the interface, the developer ecosystem is the network, and training and deployment toolchains are the infrastructure. What makes it powerful is that the entire industry works around its interfaces.
What Embercore aims to be is the data interface—or more accurately, the learning interface—in physical AI.
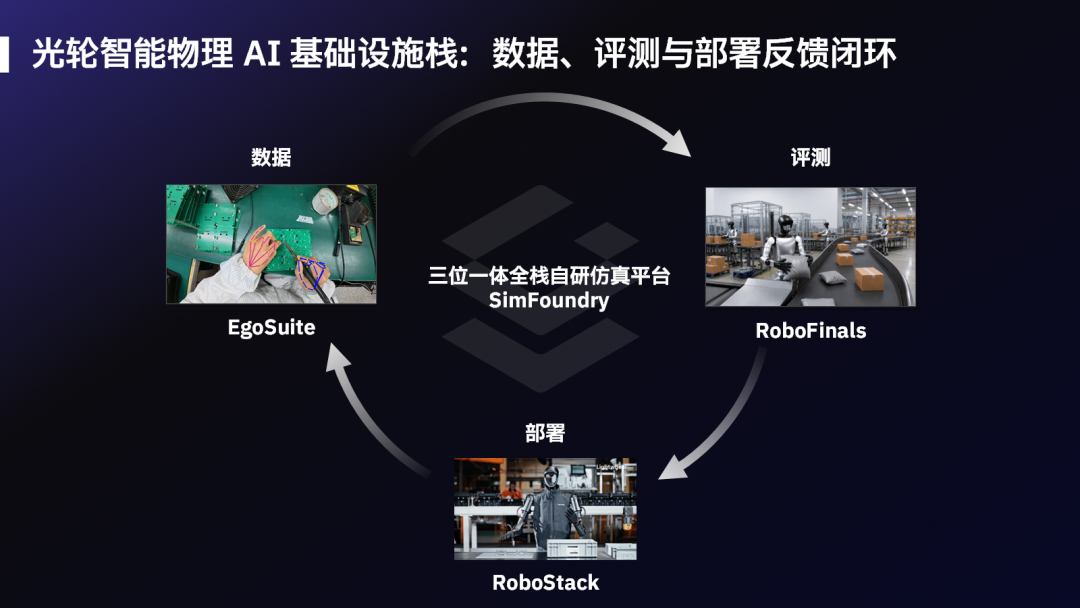
Looking at its product lineup makes this clear. EgoSuite provides human behavior data, SimFoundry and SimReady convert the real world into simulation training grounds, RoboFinals handles evaluations, and RoboStack brings real-world deployment feedback back.

These products all point to one thing: making the robot learning process a producible, measurable, and reusable system.
Its ecosystem moves are also aligned with this direction.
For example, NVIDIA lists Embercore as a core collaborator in Isaac Lab-Arena, noting that its evaluation and task layers were co-designed and developed. The significance lies in the fact that Embercore is not just a data supplier but is recognized as a participant in the evaluation framework and task system.
Another point worth noting: Embercore joined the Newton Technical Steering Committee, participating in the next-generation physical AI simulation standards alongside NVIDIA, Google DeepMind, Disney Research, and Toyota Research Institute.
Who defines the training grounds and evaluation methods will have the opportunity to shape how the industry judges robot progress.
But Embercore also differs significantly from NVIDIA.
NVIDIA has hardware barriers, developer lock-in through years of CUDA, and a clear global standard status.
Embercore does not yet have such strong lock-in capabilities. The robotics industry is still in its early stages, customer needs are fragmented, standards have not fully converged, and many projects are highly customized.
More critically, NVIDIA’s strength ultimately comes from switching costs. Developers, model companies, cloud providers, and application companies all work around its toolchains. Replacing NVIDIA means not just swapping a chip but rewriting an entire workflow.
For Embercore to truly approach the ‘NVIDIA of Data,’ it must also create similar switching costs.
Customers should choose it not because it’s cheap but because once training, evaluation, simulation assets, and deployment feedback are integrated into Embercore’s system, switching means rebuilding an entire robot learning workflow. This is the core of the ‘NVIDIA of Data’ narrative.
So, ‘NVIDIA of Data’ can be a direction, not a conclusion. Embercore is more like vying for this position rather than already securing it.
4. The Bigger the Story, the Harder the Challenges
Of course, the bigger Embercore’s story, the clearer the risks.
An entrepreneur in embodied data told me that the industry’s biggest fear now is not a lack of data but ‘having a lot of data without knowing if it truly makes robots stronger.’
The most prominent issue remains the simulation-to-reality gap.
Just because something works in simulation doesn’t mean it will work stably in real factories, warehouses, or homes. The real world is non-standardized. Embercore must continuously prove that its data and simulation assets are not just advanced-looking but truly improve model capabilities and reduce deployment failure rates.
Another issue is that data scale does not equal data effectiveness.
Embercore has disclosed several metrics: 1.5 million hours of data, over 25,000 environments, and 100,000 tasks. These numbers are impressive. But customers won’t pay just for the numbers; they want to see improved task success rates and reduced deployment costs.
The next phase of the embodied data industry will shift from ‘competing on data volume’ to ‘competing on data effectiveness.’
A more practical issue is that today’s customers could become tomorrow’s competitors.
Leading robot body companies and model companies may buy Embercore’s data and evaluation capabilities early on because the industry is moving too fast for them to build in-house. But in the long run, everyone knows the data loop is a core asset. High-value data, especially failure samples and deployment feedback, is something everyone wants to control.
So Embercore must prove its irreplaceability—not because it can collect data, but because it can organize data, simulation, evaluation, and feedback into a more efficient learning system.
Embercore AI is now in a strong ecological position, but it’s not time to celebrate yet.
It has caught the inflection point as embodied AI moves from demos to scale and has grasped the real challenge of continuous robot learning.
But next, it must prove not just that it can tell the ‘NVIDIA of Data’ story but that it can truly turn real-world experiences into learnable, evaluatable, and reusable capabilities for robots.
If it succeeds, Embercore won’t just be another fast-funded unicorn. It will represent a new signal: Those who learn better will be more likely to stand out.
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’