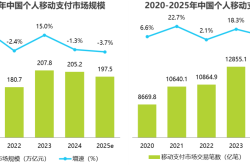
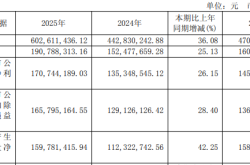
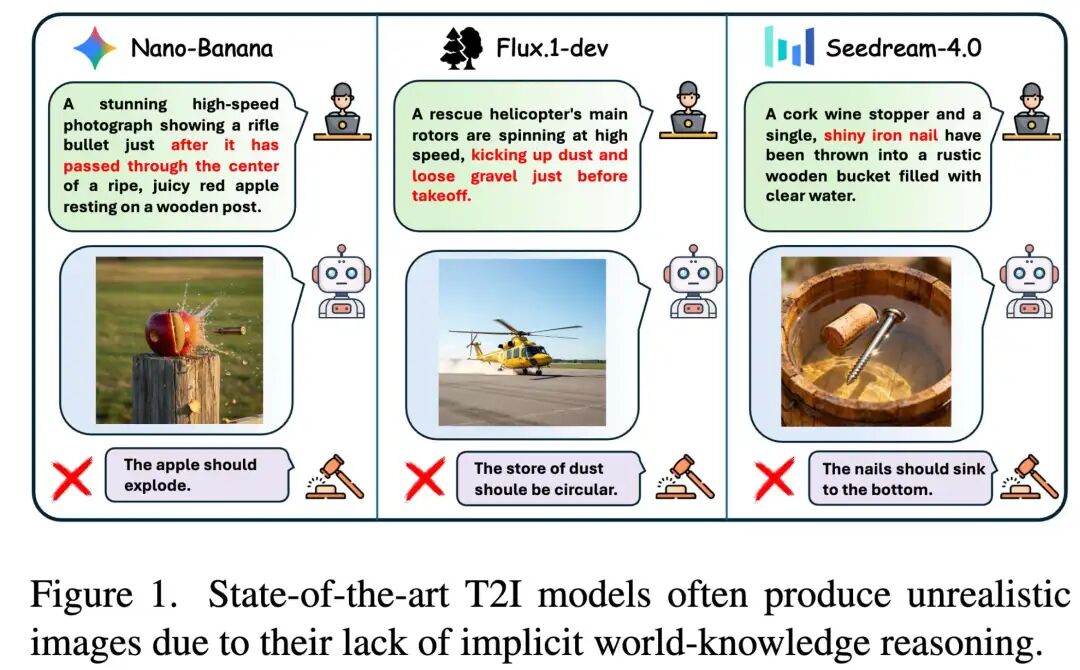
Nails Floating on Water, Bullets Piercing Apples without Exploding? 17 SOTA Models Including Nano-Banana Face Rigorous Physical and Logical Reasoning Tests!
 12/15 2025
12/15 2025
 609
609
Insight: The Future of AI-Generated Content 
The first author of this paper, Tianyang Han, is an Algorithm Research Scientist at Meituan's MeiGen Team, specializing in image generation and multimodal large language models.
Key Highlights
PicWorld: A comprehensive benchmark designed to evaluate the implicit reasoning capabilities of text-to-image models. To our knowledge, PicWorld is the first large-scale, systematic benchmark specifically tailored to assess models' understanding of implicit world knowledge (e.g., adherence to basic physical laws) and logical causal reasoning.
Introducing PW-Agent: A novel automated evaluation framework employing hierarchical assessment through agent-based decomposition. This multi-agent workflow systematically breaks down complex prompts into verifiable physical and logical components, enabling reproducible and scalable analysis of model performance on the benchmark.
Comprehensive experiments demonstrate that existing text-to-image models, particularly open-source ones, exhibit limitations in physical and logical reasoning capabilities, highlighting critical areas for future improvement.
Summary Overview
Addressed Problems
Core Capability Deficits: Current text-to-image models lack understanding of implicit world knowledge and physical causal reasoning. While capable of generating realistic images aligned with instructions, they frequently fail on prompts requiring common sense and logical reasoning.
Inadequate Evaluation Systems: Existing assessment methods focus on either compositional alignment (i.e., whether images contain elements mentioned in prompts) or rely on single-round visual question answering for scoring. This results in severe under-testing of critical dimensions such as knowledge grounding, multi-physics interactions, and auditable evidence.
Unreliable Assessment Methods: Current approaches relying on multimodal large language models for holistic judgment suffer from issues like hallucination (seeing non-existent elements) and central tendency bias (grading toward mediocrity), preventing nuanced and reliable evaluation.
Proposed Solutions
PicWorld Benchmark: Introduces the first comprehensive benchmark for systematically evaluating text-to-image models' grasp of implicit world knowledge and physical causal reasoning. It includes 1,100 prompts spanning three core categories:
Physical World
Abstract Knowledge
Logical and Commonsense Reasoning
PW-Agent Evaluation Framework: Designs an evidence-based multi-agent assessment pipeline for hierarchical, granular evaluation. The framework comprises four specialized agents:
World Knowledge Extractor (WKE): Decomposes prompts into atomic, image-verifiable expectations.
Hypothesis Formulator (HF): Constructs verifiable visual questions based on decomposed expectations.
Visual Perceptor (VP): Searches images for visual evidence to answer questions.
Reasoning Judger (RJ): Aggregates answers through a deductive-based sequential scoring scheme, incorporating checklist-style atomicity and importance weights to produce final scores.
Applied Technologies
Multimodal Large Language Models (MLLMs):
Benchmark Construction: Leverages advanced MLLMs (e.g., Gemini-2.5-Pro) to generate initial prompts, supplemented by rigorous manual curation for quality assurance.
Evaluation Framework: PW-Agent's core components (WKE, HF, VP, RJ) are essentially MLLM-based agents collaborating to perform parsing, questioning, perception, and reasoning judgment tasks.
Multi-Agent Systems: Adopts a collaborative multi-agent framework dividing complex assessment tasks into more specialized, manageable subtasks to enhance accuracy, reliability, and interpretability.
Hierarchical Assessment Dimensions: PW-Agent evaluates images across three levels: Instruction Following → Physical/Logical Realism → Detail and Synthesis Nuance.
Achieved Results
Systematic Evaluation: The PicWorld benchmark provides the first systematic testing of text-to-image models' understanding of scene-implied consequences, rather than merely their explicitly described components.
Granular and Interpretable Analysis: PW-Agent offers fine-grained, multi-layered scores through prompt decomposition and evidence-based verification, enabling deep and interpretable analysis of models' reasoning capability deficits.
Revealing Fundamental Model Limitations: Comprehensive analysis of 17 mainstream text-to-image models demonstrates their widespread fundamental limitations in implicit world knowledge and physical causal reasoning to varying degrees.
Guiding Future Directions: The study emphasizes the need for future text-to-image systems to incorporate reasoning capabilities and knowledge architectures, rather than solely enhancing image quality and explicit instruction-following abilities.
PicWorld Benchmark
Current evaluation methods primarily focus on semantic consistency and compositional accuracy, largely neglecting models' ability to understand basic world dynamics. To fill this gap in assessing text-to-image (T2I) models' implicit world cognition, this work constructs PicWorld, aiming for holistic and granular evaluation of latent natural laws learned by T2I models.
PicWorld Benchmark Construction
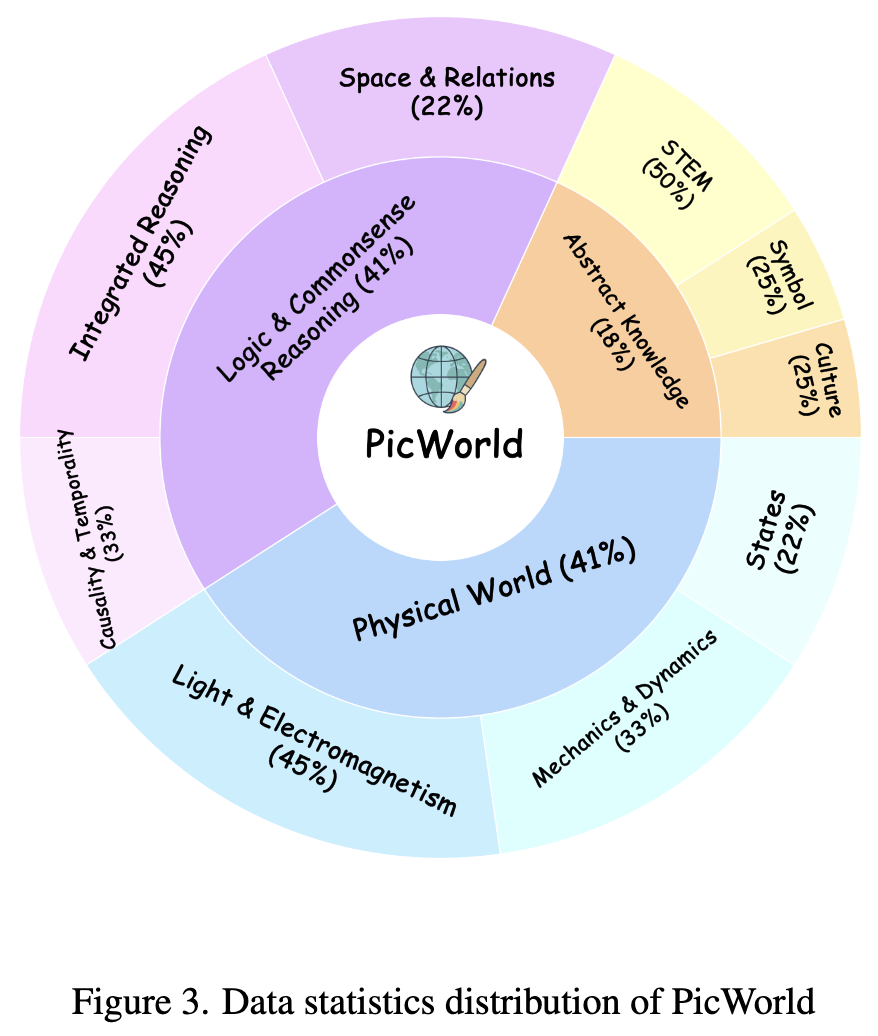
As shown in Figure 3, PicWorld comprises 1,100 carefully curated prompts systematically organized across three major domains. This work manually designed complex prompt templates, each targeting specific aspects of world understanding. Subsequently, Gemini-2.5-Pro generated a large corpus of candidate prompts, which underwent rigorous curation and refinement by human experts to ensure clarity and complexity. Details of the three sections are as follows:
Physical World
The Physical World domain of PicWorld evaluates models' ability to understand and visually simulate fundamental laws governing reality. A truly world-understanding model should not only recognize objects but also depict their behaviors under various physical constraints. Models lacking this intrinsic physical engine function as non-intelligent generators, capable only of depicting static objects without capturing the dynamic causal nature of the world. This domain is further subdivided into three core categories:
Mechanics and Dynamics: Assesses models' understanding of concepts like deformation, motion, fluid dynamics, and projectile motion.
Light and Electromagnetism: Examines models' grasp of phenomena such as reflection, refraction, shadows, and electrical phenomena.
Thermodynamics: Evaluates knowledge of phase transitions and heat transfer. Ultimately, 550 prompts were generated for this aspect.
Abstract Knowledge
This domain contains 200 prompts designed to assess models' ability to understand and accurately reproduce concepts existing purely in human cognitive and cultural spaces. Models lacking this capability can only generate literal depictions without grasping the abstract symbolic roles concepts, diagrams, and cultural narratives play in the world. It is divided into three categories:
STEM Concepts: Tests models' ability to serve as visual knowledge repositories for precise factual concepts. For example, the prompt "Clean, minimalist scientific textbook illustration of a ball-and-stick model of a water molecule" directly measures models' chemical structure knowledge, where accuracy of atomic types, quantities, and bond angles is crucial.
Culture and History: Evaluates models' familiarity with systems of cultural and historical significance.
Humanistic Symbol Systems: Requires models to further decompose understanding of non-narrative symbols such as flags, icons, and musical scores.
Logical and Commonsense Reasoning
This domain assesses higher-order cognitive abilities requiring models to infer logical relationships and construct coherent scenarios. Models lacking this reasoning capability generate images containing correct elements but logically flawed, spatially inconsistent, or causally broken. This work structures the domain into three categories:
Causality and Temporality: Aims to test models' understanding of causal relationships and temporal progression. For example, the prompt "A wet, black umbrella with a long handle is brought indoors, opened, and placed on a smooth, polished wooden floor" challenges models to infer the logical consequences of dry floor patches beneath the umbrella and surrounding water puddles.
Spatial Relationships: Explores models' understanding of complex and precise spatial arrangements.
Integrated Reasoning: Designed as an upper-bound test for state-of-the-art (SOTA) models, requiring them to simultaneously simulate and coordinate multiple distinct physical laws. Ultimately, 350 prompts were generated for this aspect.
Figure 2 below shows some data samples from PicWorld.

Hierarchical Assessment via Agent Decomposition
Unlike previous methods directly evaluating image authenticity or aesthetic quality, this work designs PW-Agent—a hierarchical, step-by-step analytical framework employing structured, non-linear, and perception-confidence-based scoring mechanisms. PW-Agent enables definitive yet highly discriminative and reliable judgments about AI-generated images' physical world understanding. The overall workflow of PW-Agent is shown in Figure 4 below.
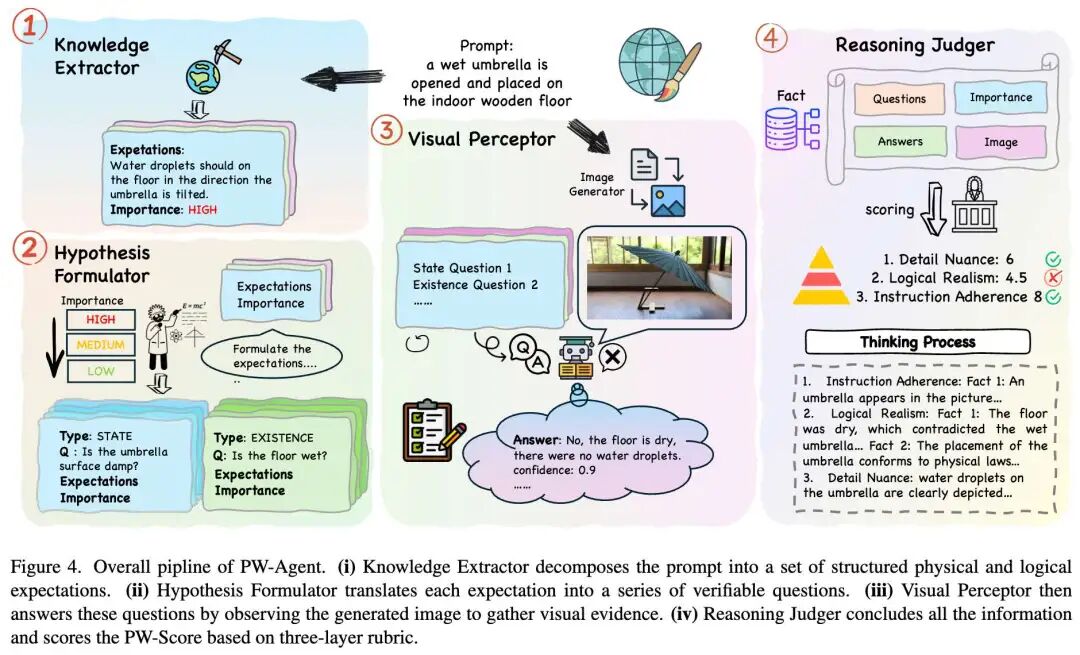
This work assesses images generated for prompts through an evidence-driven pipeline comprising four modules: World Knowledge Extractor (WKE), Hypothesis Formulator (HF), Visual Perceptor (VP), and Reasoning Judger (RJ). This design is inspired by the failures of single-pass judgment and coarse proxy metrics, as well as recent advancements in problem-driven evaluation and capability-centered T2I benchmarking (emphasizing compositionality, commonsense, physics, and world knowledge).
Pseudocode for PW-Agent is provided in the supplementary materials.
World Knowledge Extractor (WKE)
Given a natural language prompt, WKE infers a structured checklist of atomic, image-verifiable expectations. These expectations must hold true in any correct single-frame depiction implied by , focusing on textual implications rather than mere restatements. Each expectation is defined as visible traces in static images (e.g., "rounded ice edges and surrounding puddles" rather than "ice is melting"), with compound assertions systematically decomposed into minimal, independent items to ensure comprehensive coverage of potentially implicit physical laws, causal postconditions, spatial relationships, and factual knowledge in . Besides expectations, WKE outputs numerical importance values defining the extent to which each expectation should be enforced. Typically, WKE generates a set:
where is a textual description and is an importance weight (low/medium/high).
Hypothesis Formulator (HF)
HF transforms each high-level expectation into concrete visual question answering (VQA) pairs serving as auditable evidence. This is achieved by generating a set of binary or descriptive questions , whose affirmative answers confirm expectation fulfillment. This step bridges the gap between abstract reasoning and concrete pixel-level detection.
Visual Perceptor (VP)
VP acts as the system's eyes. It receives image and question set , outputting answers along with confidence scores and bounding boxes or region descriptions as rationales. To minimize hallucination, we employ MLLMs with strong visual capabilities (e.g., GPT-4o or Gemini) for this task, with explicit instructions to base answers solely on visible pixels. For each question , VP outputs:
where is a textual answer and reflects detection certainty.
Reasoning Judger (RJ)
The RJ module does not perform simple averaging but applies a logical hierarchy to compute final scores. It aggregates evidence across three levels:
Level 1: Instruction Adherence This layer quantitatively measures models' ability to follow explicit, literal instructions in prompts. Serving as a foundational check, it verifies Existence-type Q&A pairs, such as the presence of core subjects and accuracy of specified attributes. It operates on a penalty system where severe failures of high-importance instructions result in minimum scores. The score is calculated as:
where is the set of all failed Existence-type facts, and is the penalty score based on fact importance (high: 5.0, medium: 3.0, low: 1.0).
Level 2: Physics/Logical Realism Level 2 evaluates the extent to which generated images conform to basic physical and logical laws, serving as a primary indicator of models' world knowledge and reasoning capabilities. The score is calculated by weighting each correctly described phenomenon (State-type) according to importance and corresponding confidence scores. The score is calculated as:
where is the importance weight for fact , is the corresponding confidence score, and is an indicator function for fulfillment.
Level 3: Detail & Synthesis Nuance Level 3 assesses the quality and complexity of correctly rendered physical phenomena, aiming to distinguish qualified outputs from exceptional ones. It employs bonus and penalty rules: rewarding extremely detailed renderings with bonuses while penalizing logical inconsistencies between different effects. This layer reflects models' advanced capabilities in simulating world complexity with nuance. The score is calculated as:
Among them, represents the base score, represents the excellence bonus, and represents the inconsistency penalty.
Final Aggregation and Reporting This work calculates a total score named PW-Score using the following formula:
To further leverage the strong reasoning capabilities of MLLMs, it is also necessary for the model to document a human-readable thought process, enumerating satisfied/failed expectations, applied penalties/rewards, and intermediate values from the aforementioned formula.
Experiments
Experimental Setup
This work selected 17 state-of-the-art models for evaluation, covering three categories of architectures:
Diffusion-based models: Includes FLUX.1-dev/schnell, Stable Diffusion (SD) 3.5 Large/Medium, SD 3 Medium, HiDream-l1-Full, Lumina-Image-2.0. Unified multimodal models: Includes Emu3, JanusPro-1B/7B, JanusFlow-1.3B, Show-o-512, Bagel (with/without Thinking). Closed-source models: Includes DALL-E-3, Nano-Banana, SeedDream-4.0. PW-Agent uses Qwen2.5-VL-72B as its base model.
Main Results
As shown in Table 1 below:
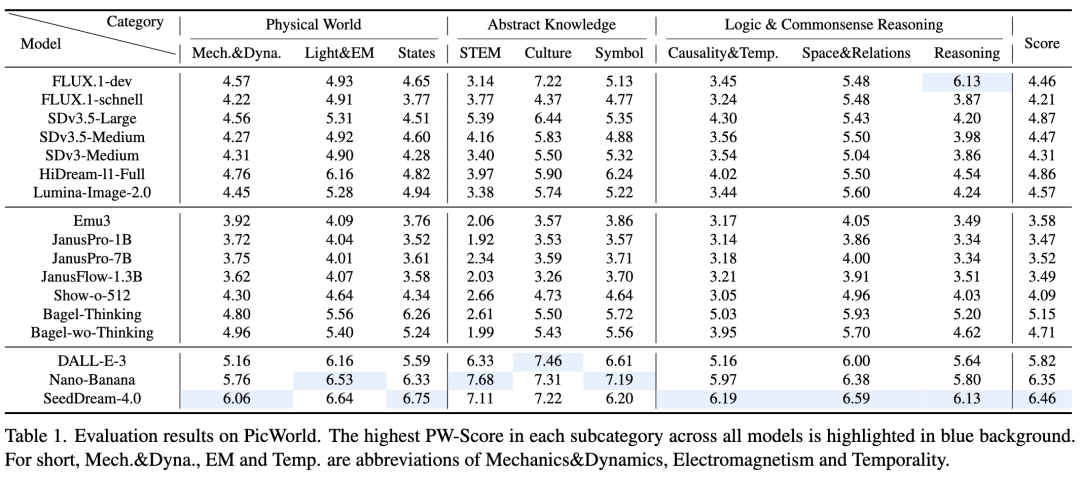
T2I models have limited capabilities in implicit world logic reasoning: Nearly all models consistently score low on STEM and "Causality and Temporality" categories. Even the top-performing SeedDream-4.0 shows relatively low scores on Symbol and STEM. This indicates that models excel at replicating visual appearances (e.g., shadows) but struggle to infer implicit consequences (e.g., ice melting near a heat source).
Closed-source models significantly outperform open-source models: A notable performance gap exists between closed-source models (e.g., SeedDream-4.0) and most publicly available models. This is partly attributed to closed-source systems integrating sophisticated preprocessing and prompt engineering in their reasoning pipelines (leveraging MLLMs to rewrite prompts and transform implicit challenges into explicit instructions).
Models perform better on knowledge-based tasks than reasoning-based tasks: Models generally perform better on Culture and Symbol categories than on STEM and "Causality and Temporality." This is because training data typically contains abundant explicit nominal knowledge but lacks the structured information needed to learn implicit causal or temporal relationships.
The performance of open-source unified multimodal models is significantly lower than that of leading diffusion models: Autoregressive models such as Emu3 and the JanusPro series typically occupy lower performance tiers in the PicWorld benchmark. This may suggest a trade-off between model generality and specialized capabilities for high-fidelity physical simulation.
Evaluation of PW-Agent (Verifying the Effectiveness of PW-Agent):
Consistency with Human Evaluators: As shown in Figure 5 below, through human studies (3 senior engineers, pairwise comparisons), PW-Agent achieves a **90.5%** agreement rate with human preferences, indicating its ability to effectively discern subtle differences in image quality and physical plausibility. 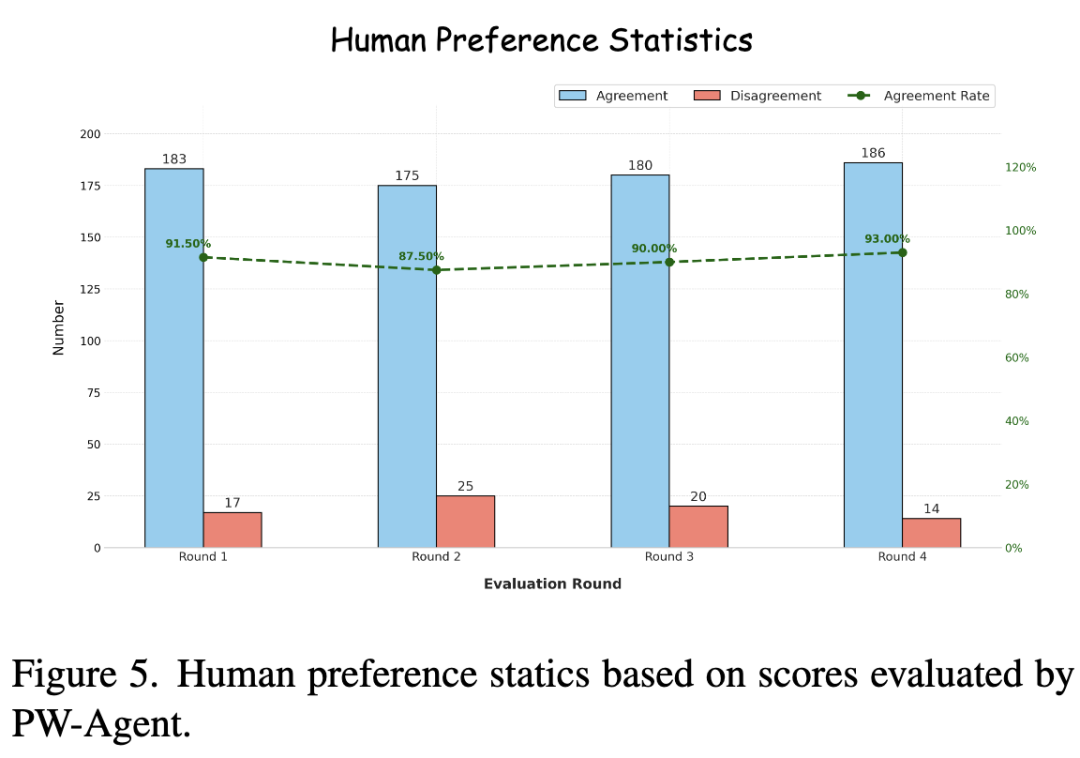
Ablation Study (PW-Agent vs. Direct Judgment):
PW-Agent is compared to a baseline using GPT-4o for zero-shot direct scoring.
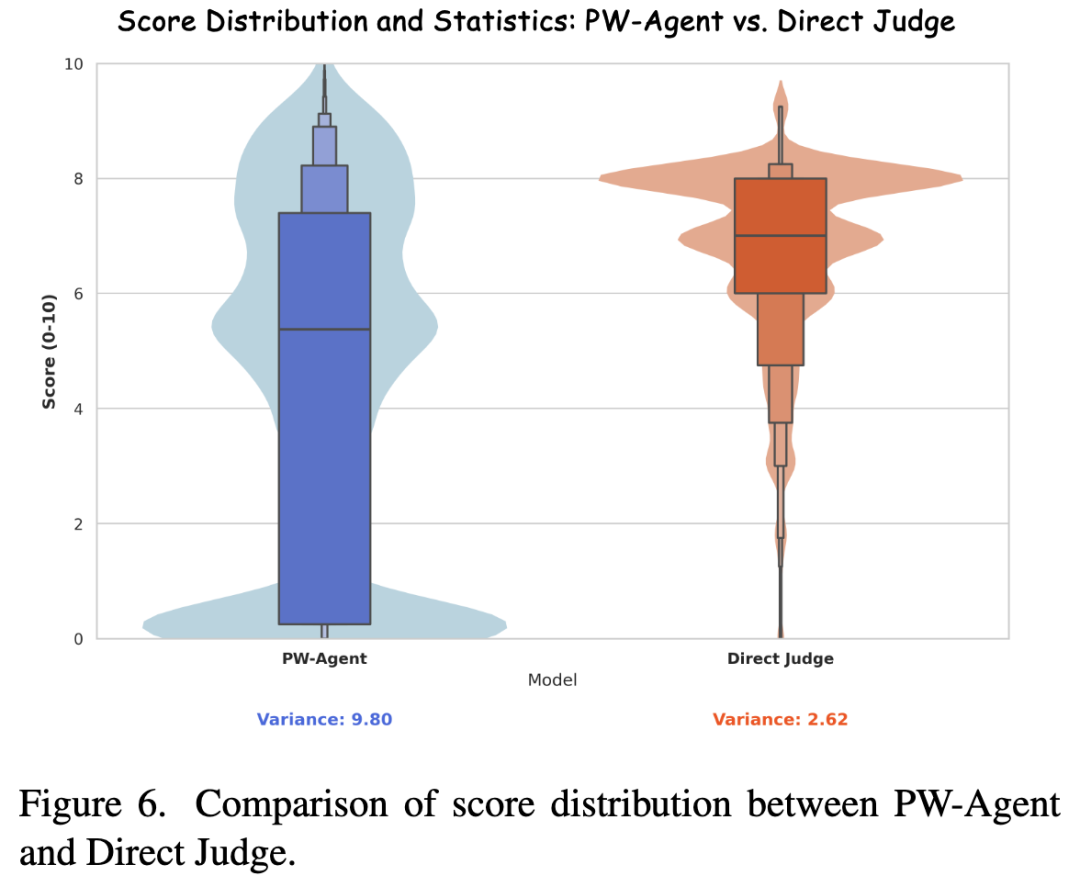
Human evaluators preferred PW-Agent's scores and reasoning in **81.5%** of cases (as shown in Table 2 below).
As shown in Figure 6 below, direct judgment exhibits a strong central tendency bias (compressed score distribution), while PW-Agent utilizes the full scoring range, demonstrating higher variance and discriminative power. 
Conclusion
PicWorld is a capability-centered benchmark that directly tests whether T2I models can leverage implicit world knowledge and generate images consistent with physical laws and causal logic. PicWorld shifts evaluation from coarse "prompt-image" correlation to verified, fact-specific evidence, revealing model behavior in knowledge grounding, multi-physics interactions, and logical consequences beyond explicit prompt specifications.
This work further proposes PW-Agent, an evidence-based evaluator that transforms prompts into auditable checklists and aggregates pixel-level findings into transparent, hierarchical scores. This approach retains the scalability of query-based evaluation while reducing the bias and unreliability of one-shot judgments.
Experiments on PicWorld demonstrate that despite strong prompt adherence capabilities, state-of-the-art systems—particularly open-source models—still struggle with physical realism and causal reasoning. This work hopes that the combined use of PicWorld and PW-Agent will provide actionable diagnostics for model comparison, guiding data curation and driving further methodological advancements.
References
[1] Beyond Words and Pixels: A Benchmark for Implicit World Knowledge Reasoning in Generative Models
-
![]()
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming