Video Model Dimensionality Reduction Attack? Zhejiang University & Harvard Introduce IF-Edit: A "Video Generation" Approach for Training-Free Image Editing!
 12/16 2025
12/16 2025
 668
668
Interpretation: The Dawn of AI-Generated Content
Paper Title: Can Image-to-Video Models Serve as Proficient Zero-Shot Image Editors?
Institutions: Zhejiang University & Harvard University
Introduction: AI-driven techniques for object removal and background replacement have already left us in awe. But have you ever imagined using AI to morph a photo of an "intact cup" into its "shattered state"? Or to transform "raw dough" into a "freshly baked cookie"? Traditional image generation models often struggle to capture such physical transformations and temporal sequences. Enter IF-Edit, a revolutionary method that directly harnesses video generation models (e.g., Wan 2.2) for image editing without any fine-tuning, enabling AI to truly comprehend the physical world!
When Video Models "Step Down" into Image Editing
Current text-to-image models (SD, Flux, etc.) excel at localized replacements but often falter when dealing with non-rigid deformations (e.g., object breaking, melting) or temporal reasoning (e.g., "after one hour," "post-cooking"). Why? Because these changes are inherently dynamic processes, not mere pixel substitutions. Researchers from Zhejiang University and Harvard University have proposed IF-Edit. Their key insight: Large-scale video diffusion models (Video Diffusion Models) already possess robust "world simulation" capabilities. Can we leverage this understanding of physics and time to achieve more realistic image editing?
Witness these effects, all "effortlessly" crafted by video models:

What Sets IF-Edit Apart?
Compared to traditional image editing methods (e.g., InstructPix2Pix, MagicBrush), IF-Edit showcases overwhelming advantages in handling actions, deformations, and causal reasoning.
It requires no training (Tuning-Free), directly repurposing existing Image-to-Video models (this paper utilizes the open-source Wan 2.2).
Seeing is believing—let's compare: When instructed to "saw the chair in half," traditional models merely draw lines on the chair, whereas IF-Edit truly "saws" through its structure. When told to "make the bird bow its head," IF-Edit perfectly preserves the bird's body structure, simulating the action rather than just distorting pixels.

It can even tackle complex reasoning tasks (Reasoning):
"Appearance after one hour" (e.g., increased phone battery charge)
"Appearance after falling from a height" (e.g., shattered glass)
"Appearance after full inflation" (e.g., enlarged balloon)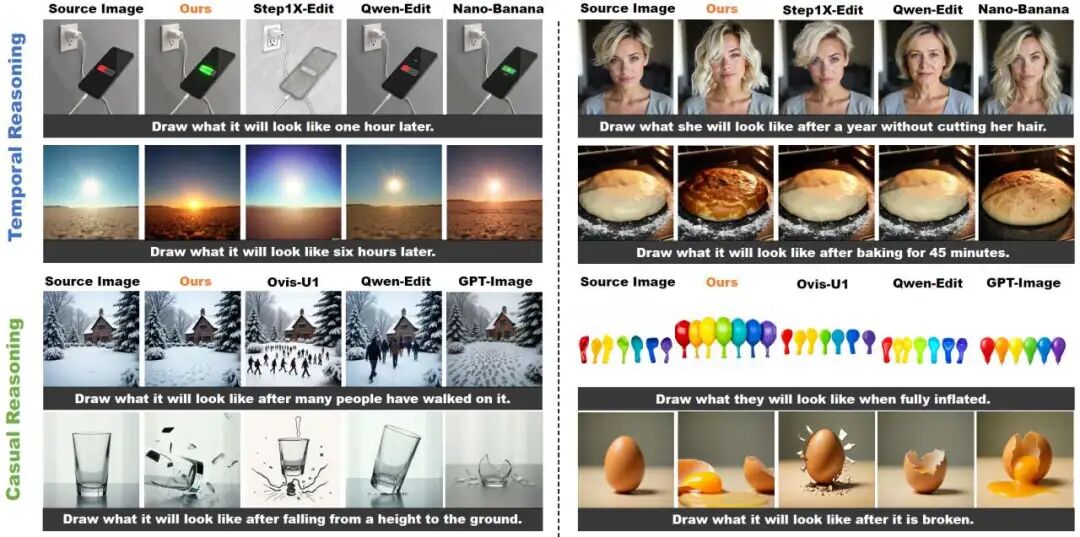
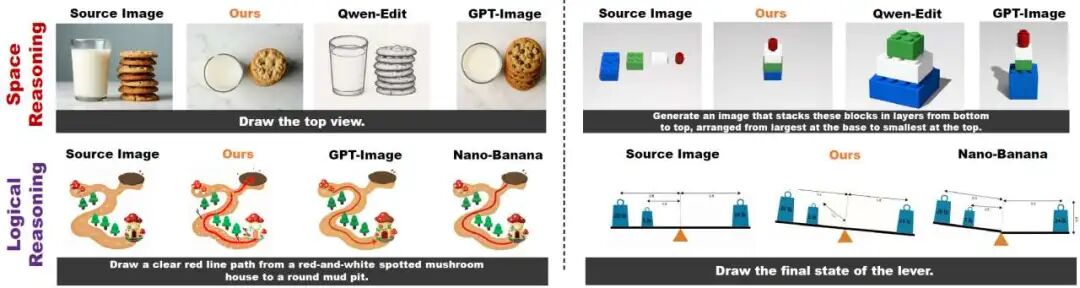
Demonstration of reasoning capabilities on RISEBench. IF-Edit excels in temporal, causal, and spatial reasoning, accurately depicting the expansion of baked cookies or the physical state of broken eggs.
How Does It Work? (Core Principles)
Directly employing video models for image editing presents three major challenges:
Ambiguous Instructions: Video models thrive on detailed dynamic descriptions, while editing instructions are often concise (e.g., "shatter it").
Inefficient Computation: Editing requires just one image, yet generating dozens of video frames is time-consuming and costly.
Blurry Outputs: Video frames often suffer from motion blur, lacking the clarity of photos.
IF-Edit introduces three ingenious modules to address these issues:
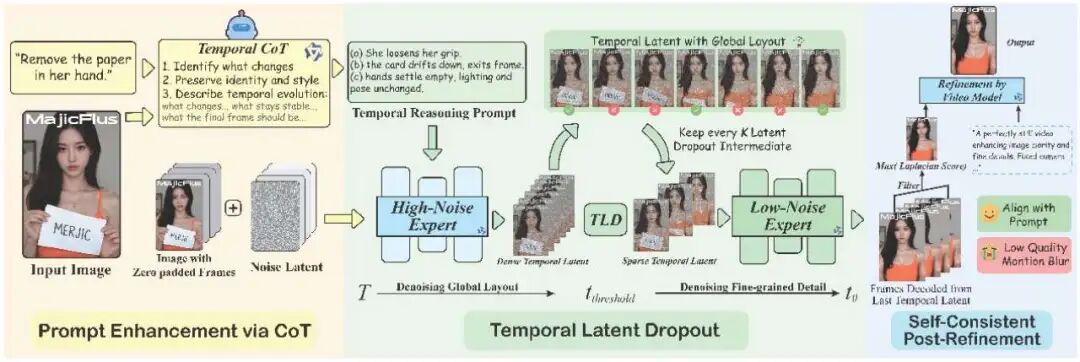
"Chain of Thought": CoT Prompt Enhancement A simple instruction like "remove the paper" is too vague for video models. IF-Edit leverages multimodal large models (VLMs) to transform static instructions into time-evolving dynamic descriptions. Before: "Remove the paper." After: "(a) She releases her hand, (b) The paper drifts and exits the frame, (c) Her hand remains idle..." This enables the video model to grasp the "process of the action" and generate the correct final frame.
"Pruning": Temporal Latent Dropout (TLD) Why generate all intermediate frames when only the last one is needed? Research indicates that the early stages of video generation establish the global layout, while later stages refine textures. IF-Edit employs a "temporal dropout" strategy: after determining the structure in the early denoising stages, it discards redundant computations for intermediate frames and retains only keyframes for subsequent processing. Results: Faster inference, reduced memory usage, and no compromise on final quality.
"Sharpening": Self-Consistent Post-Refinement Single frames from video generation often suffer from motion blur. Instead of introducing additional super-resolution models, IF-Edit "refines in the loop": 1. Automatically selects the clearest frame. 2. Feeds it back into the same video model with the instruction "a perfectly still video..." 3. Leverages the video model's own priors to eliminate motion blur and enhance texture details.
Experimental Conclusions and Limitations
On TEdBench (non-rigid editing) and RISEBench (reasoning editing) benchmarks, IF-Edit achieves state-of-the-art (SOTA) or highly competitive results, particularly excelling in CLIP-T and CLIP-I metrics.
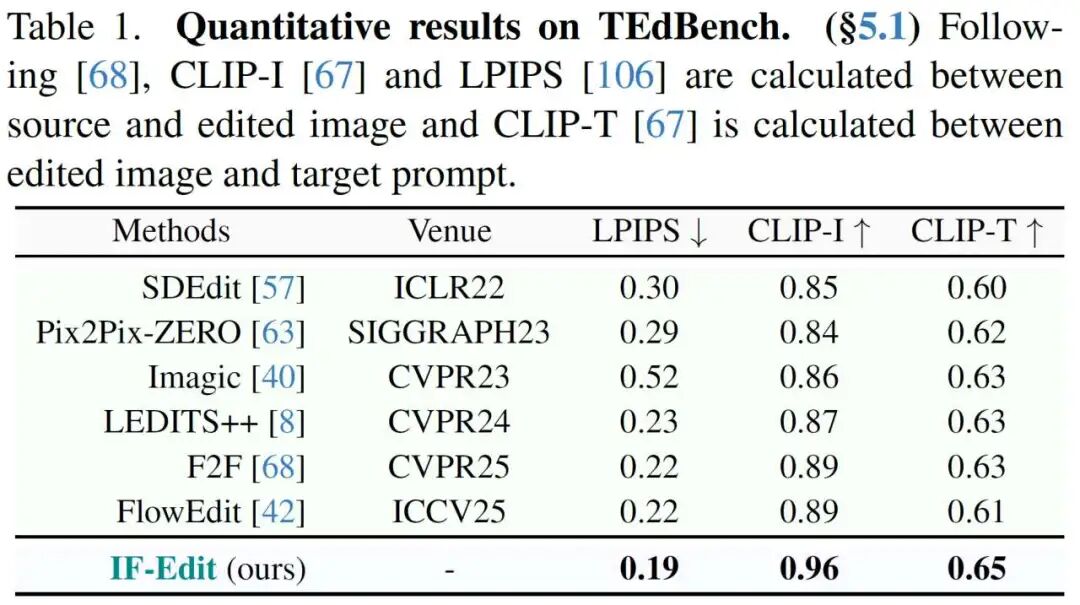
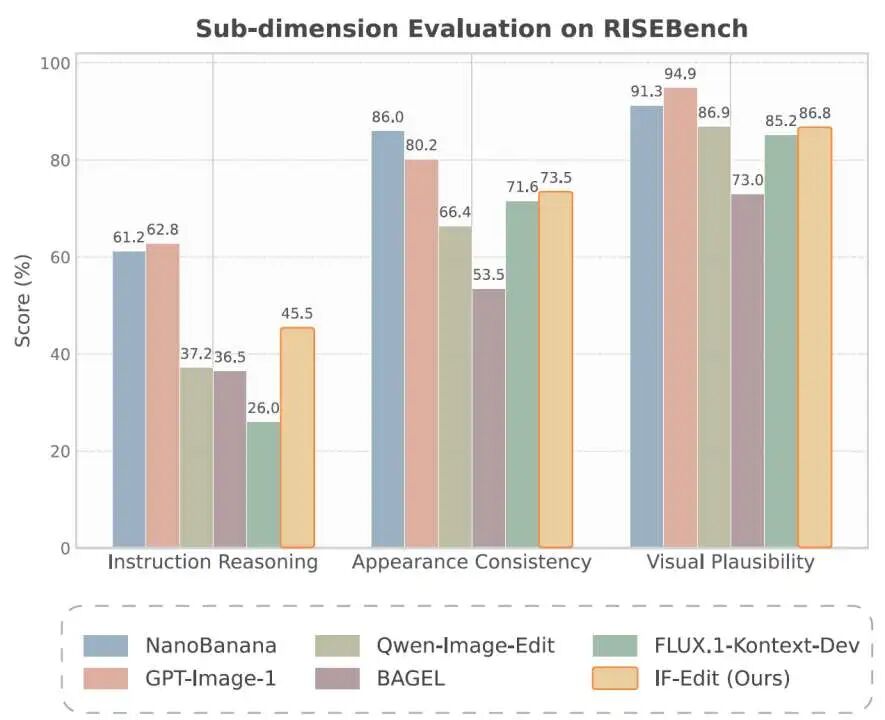
Experimental data reveals that IF-Edit strikes an excellent balance between preserving original image features and responding to text instructions, especially in scenarios requiring physical common sense.
ByteMorph If TEdBench tests deformations, ByteMorph evaluates dynamic physical laws. It is a recently proposed benchmark focusing on instruction-guided motion editing, covering five major dynamic scenarios: camera zoom, camera movement, object motion, human motion, and complex interactions. It demands models not only to edit images but also to comprehend "camera movements" and "joint motions" like a director.
Because IF-Edit borrows the "dynamic brain" of video models, it outperforms traditional editing models like InstructPix2Pix and MagicBrush across all ByteMorph metrics (especially tasks involving physical motion). This proves: To edit "actions" effectively, one must first understand "videos."
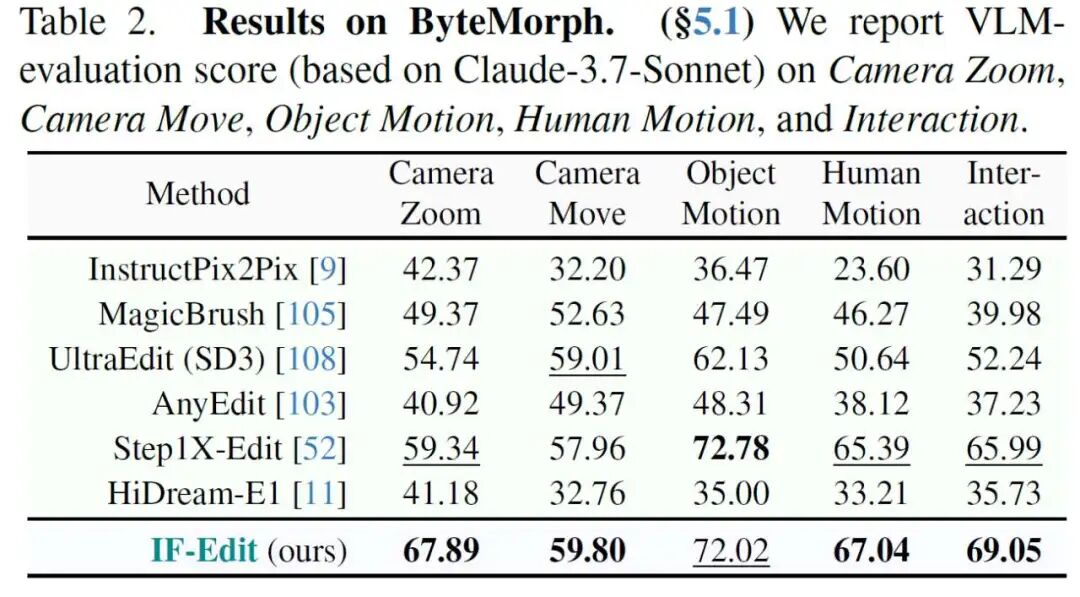

In ByteMorph testing, IF-Edit demonstrates a profound understanding of physical structures, such as yoga pose changes and train movements.
Limitations and Insights: The "Nature" Debate of Video Models Experiments reveal that IF-Edit sometimes falls short of traditional editing models in local attribute edits (e.g., simple color changes, style transfers). This exposes the inductive bias of Image-to-Video models: they prefer generating spatially and temporally coherent "overall evolutions" rather than focusing on local "pixel mappings."
This "specialization" is not immutable. Concurrent work like Video4Edit (Baidu) demonstrates that fine-tuning video models with editing data can strongly compensate for this weakness. Viewing IF-Edit (training-free) and Video4Edit (fine-tuned) together not only validates the innate advantages of video models in physical and structural understanding but also highlights their potential as highly versatile editing foundations.

Conclusion
IF-Edit offers a fresh perspective: Image editing need not be confined to Image-to-Image translation but can also be Image-to-Video-to-Image world simulation.
By repurposing powerful video generation models, we can achieve Zero-Shot image editing that comprehends physics and causality without the need for expensive paired editing data. As video models (e.g., Sora, Wan, HunyuanVideo) continue to evolve, this "dimensionality reduction" approach to image editing may become the mainstream of the future.
References
[1] Are Image-to-Video Models Good Zero-Shot Image Editors?
-
![]()
Why Hasn’t AI-Driven Payment Flourished Despite Tech Giants’ Push?
-
![]()
Intensify Efforts in the High-End Optoelectronic Semiconductor Sector! Aipu Dingchun and Jiangsu Meidong Forge a New Joint Venture
-
![]()
From Endoscopes to Optical Interconnects for AI Computing Power: A Veteran Optical Company's Strategic Shift
-
![]()
Behind the Scenes of Token Factories' Rise as a Capital Market Sensation
-
![]()
What Does MaaS Ultimately Bring to Chinese Cloud Providers? | In-Depth Industry Analysis
-
![]()
China’s Auto Resale Value Report Unveiled: AITO M9 Electric and Hybrid Variants Dominate Rankings
-
![]()
Dialogue with Huang Yangming: On the Eve of the Physical AI Boom, the Value of Data Infrastructure Begins to Materialize
-
![]()
The Experience is a Bit Unusual! Logitech G Cloud Review: Great Feel, but Not Ideal for Cloud Gaming