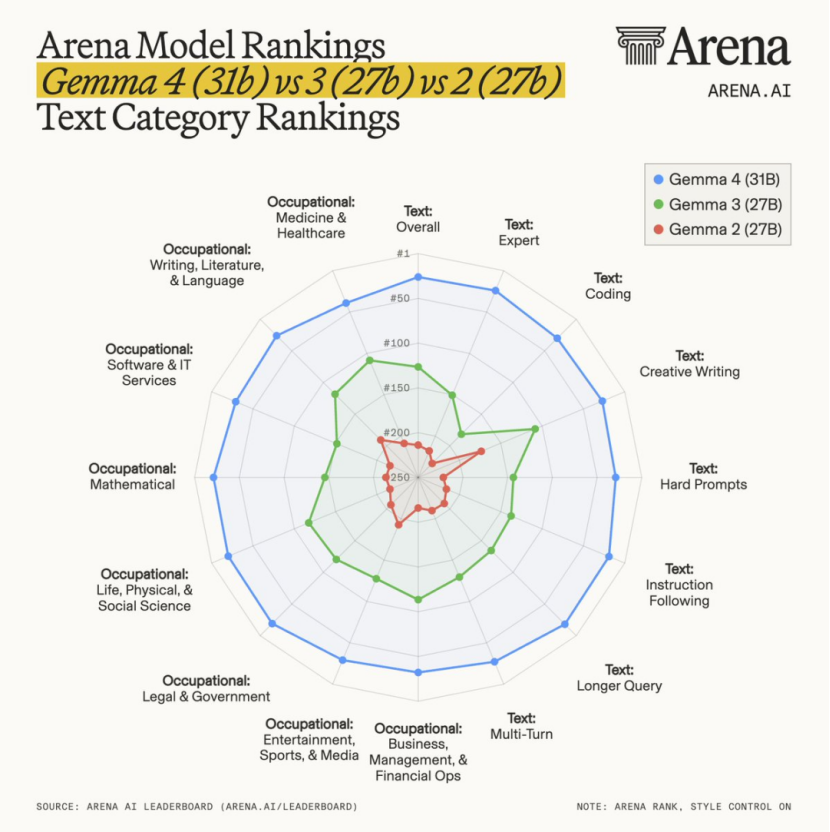
Hot Topic | Google's Gemma 4 Outperforms 397B Model with Just 31B Parameters, Elevating Local AI to Unprecedented Levels
 04/07 2026
04/07 2026
 598
598
Preface:
In the realm of large-scale AI models, the parameter scale has traditionally been seen as the most straightforward metric for competition, with the industry's prevailing belief being that a larger scale equates to superior capabilities.
However, Google's newly launched Gemma 4, boasting a 31B-parameter model, is challenging and even surpassing models with scales nearing 400B in various scenarios, thus disrupting this established paradigm.
Author | Fang Wensan
Image Source | Internet

31B vs 397B: Beyond Mere Numbers
Google DeepMind discreetly released the Gemma 4 series models to the open-source community, without any prior hype or launch event.
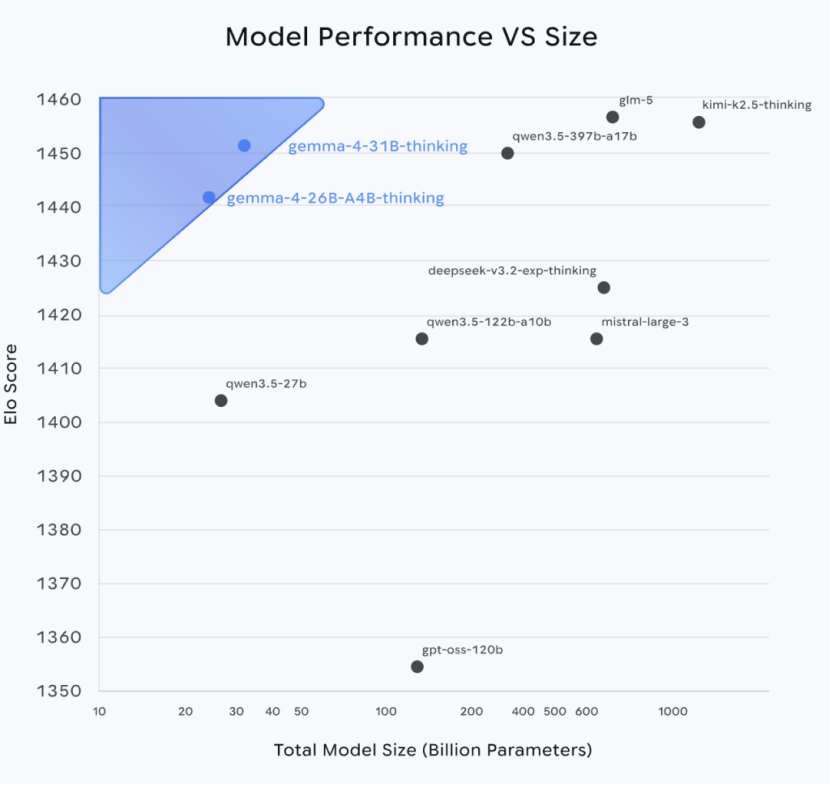
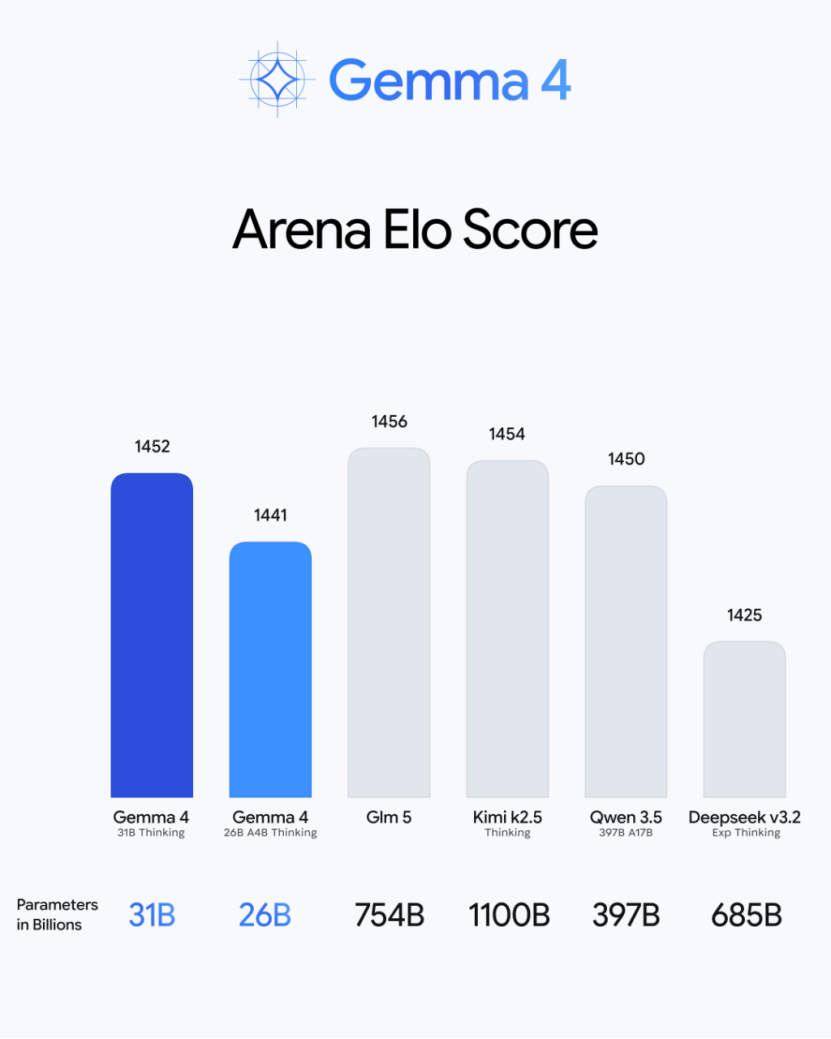
On the industry-recognized Arena AI text ranking, it catapulted to third place among global open-source models, achieving an Elo score of 1452 and directly outperforming the Qwen 3.5 397B model, which boasts nearly 13 times more parameters.
The 26B MoE (Mixture of Experts) version in the same series also ranked sixth with a score of 1441, activating only 3.8 billion parameters during inference while delivering performance comparable to a 30-billion-parameter model.
In the AIME 2026 competition test, representing top-tier mathematical reasoning capabilities, it achieved an accuracy rate of 89.2%.
The previous generation, Gemma 3 27B, scored only 20.8%, marking an improvement of over fourfold.
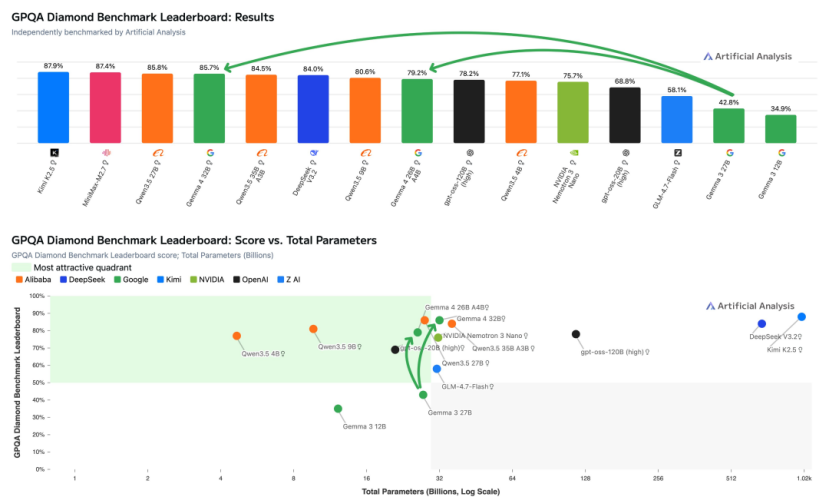
On the GPQA Diamond, a graduate-level scientific question-answering benchmark, it achieved an accuracy rate of 84.3%, doubling the performance of its predecessor.
In the LiveCodeBench v6 code test, the 31B version scored 80.0%, compared to just 29.1% for the previous generation.
In the Codeforces programming competition rating, its ELO score reached 2150, placing it among the top human competitive programmers.
At the comprehensive capability level, on the MMLU Pro benchmark test measuring a model's comprehensive knowledge and reasoning abilities, the 31B version scored 85.2%, placing it in the same league as leading models with hundreds of billions of parameters.
For long-context capabilities, it supports a maximum context window of 256K, with accuracy in the MRCR v2 128K long-text retrieval test jumping from 13.5% in the previous generation to 66.4%.
Multimodal capabilities have not been compromised due to parameter scale control, with all models in the series natively supporting image and video input without the need for additional visual encoders.
In the MMMU Pro multimodal understanding test, the 31B version scored 76.9%, achieving an accuracy rate of 85.6% in MATH-Vision mathematical vision questions.
Even the lightweight E2B and E4B versions for mobile devices support native audio input, delivering stable performance in speech recognition and translation scenarios.
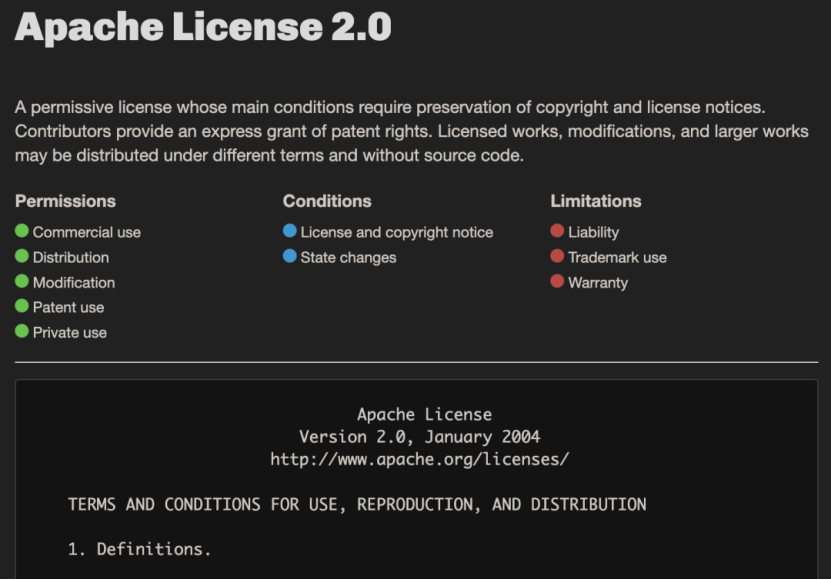
These performance achievements are built on extremely low hardware requirements. The 4-bit quantized model of the 31B version can compress video memory usage to under 20GB, enabling full deployment and smooth inference on a single consumer-grade RTX 4090 graphics card.
Although the 26B MoE version has a total of 26 billion parameters, it activates only 3.8 billion parameters during inference, with running speeds almost on par with a 4-billion-parameter model.
Under the same video memory conditions, inference speed is nearly 2.5 times faster than that of dense models with equivalent capabilities.
The E2B and E4B versions for end-side devices can even run completely offline on Android phones and Raspberry Pis, with latency below 50ms.
What Has Google Done Right?
The core of competition in large models is shifting from parameter scale to effective computational density.
Many models with hundreds of billions of parameters have less than 10% effective parameters, akin to [using 100% effort but achieving only 10% results].
In Gemma 4 31B, all 31 billion parameters participate in every inference step without losses from sparse routing.
This directly results in: effective parameter density > nominal parameter scale, which is why the 31B Dense can outperform the 397B MoE in some tasks.
Model capability = effectively participating computational parameters × data quality × training strategy, not just total parameter count.
The core breakthrough of Gemma 4 is maximizing the efficiency of the Mixture of Experts (MoE) architecture.
The Gemma 4 26B MoE version adopts an 8-expert routing mechanism, dynamically activating the two most relevant experts during inference based on input token characteristics, while keeping all other parameters inactive.
This means that although it has the knowledge reserves of 26 billion parameters, it only needs to mobilize 3.8 billion parameters during actual operation, achieving performance close to that of a 30-billion-parameter model at the computational cost of a 4B model.
This [on-demand activation] design breaks the inherent logic that [performance and computational power must be linearly linked].
It enables models to achieve exponential improvements in inference efficiency while maintaining knowledge breadth.
Even the 31B dense version underwent deep architectural reconstruction, with the core innovation being Per-Layer Embeddings (PLE) technology.
PLE technology equips each layer with dedicated low-dimensional signal channels, allowing each token to receive customized vectors generated from its identity and contextual information at every layer.
With minimal additional overhead, it grants each layer dedicated regulatory capabilities, which is key to the small-scale model's ability to deliver superior performance.
Gemma 4 adopts a hybrid attention mechanism, interweaving local sliding window attention with global attention to ensure that the final layer is always global attention.
Simply put, the model no longer performs full pairwise comparisons of all tokens but captures local semantic details through sliding windows, supplemented by a global attention layer to capture cross-paragraph logical connections.
This design significantly optimizes the growth curve of KV cache and reduces video memory usage for long-text processing without sacrificing long-context understanding capabilities.
Meanwhile, Google introduced shared KV cache technology, where the model's last N layers directly reuse KV tensors from previous layers, with attention layers of the same type sharing the same set of KV states.
This optimization further reduces video memory usage in long conversation scenarios. Combined with the TurboQuant cache compression algorithm, it can compress KV cache to 3-bit without performance loss, directly reducing memory usage by sixfold.
Google employed a multi-teacher distillation technique, directly distilling the reasoning logic, chain of thought, and tool-calling capabilities of the Gemini 3 series closed-source models into the Gemma 4 model.
This is equivalent to a student directly acquiring the core problem-solving approaches of multiple top-tier mentors rather than blindly practicing on vast question banks, naturally achieving a qualitative leap in learning efficiency.
This is why Gemma 4 achieves a generational leap over its predecessor in scenarios requiring deep logical capabilities, such as mathematical reasoning, code generation, and agent workflows.
Apache 2.0 License: Google's Trump Card
Previously, the Gemma series used Google's custom license agreement, which included numerous restrictive clauses criticized by developers.
The core issue was that the old agreement not only imposed many constraints on commercial use but might even extend restrictions to other models trained on synthetic data generated by Gemma. Google also reserved the right to unilaterally modify agreement terms.
This uncertainty deterred many enterprise users and developers from using it in production environments for fear of legal compliance issues.
This [semi-open] model, despite accumulating over 400 million downloads and over 100,000 community-derived variants, could not compete with Meta Llama or domestic open-source models in commercial deployment.
Since 2024, the Meta Llama series has dominated the open-source ecosystem with its permissive license, while domestic players like Tongyi Qianwen, DeepSeek, and Zhipu AI have rapidly captured market share through frequent iterations and friendly agreements.
Domestic vendors have long dominated the top ranks of global open-source model leaderboards, gradually marginalizing Google's Gemma series.
Google is well aware that in the open-source race, the permissiveness of the license is essentially a test of sincerity in building an open ecosystem.
If even basic commercial freedom cannot be guaranteed, developers will vote with their feet, no matter how strong the model's performance is.
For the entire industry, the impact of this shift is far more profound than parameter improvements.
Enterprise users can finally use Gemma 4 in production environments without worrying about compliance risks.
The Apache 2.0 license allows developers to deeply modify and audit the model, which is a core requirement for scenarios with high data security and compliance needs, such as healthcare, finance, and government affairs.
Hugging Face co-founder Clément Delangue called this license switch a [significant milestone in the open-source AI field].
After the license change, Gemma 4's model weights were simultaneously listed on Hugging Face, Kaggle, and Ollama, with mainstream frameworks like Transformers, vLLM, and llama.cpp completing adaptation on the release day.
Developers can quickly deploy it locally via Ollama or llama.cpp, with Unsloth Studio providing quantization model fine-tuning support.
In the cloud, it can be scaled via Google Vertex AI and Cloud Run, forming a complete end-to-cloud development pipeline that is ready to use out of the box.
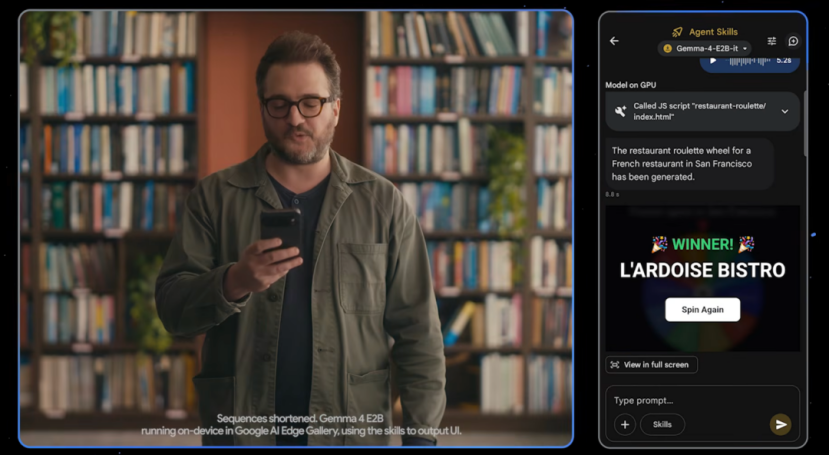
Pushing Local AI to New Heights
For the past three years, the default premise for AI deployment has always been cloud APIs, stable networks, token-based subscription models, and transmitting data to third-party servers.
This premise naturally excludes many scenarios with high requirements for data sovereignty, privacy security, and network environments from AI applications.
Patient records in hospitals, transaction data in financial institutions, production line parameters in factories, commercial contracts in law firms, and confidential documents in government agencies—these scenarios most in need of AI efficiency are precisely those least able to accept data uploads to the cloud.
The core value of local AI is to enable AI capabilities to run entirely on users' own hardware, with data remaining local, offline, and not transmitted back, fundamentally addressing the core pain point of data security.
Through bottom-layer algorithm optimizations, Gemma 4 reduces video memory usage by over 75% after quantizing the model to 4-bit, enabling easy deployment on consumer-grade graphics cards and even phones.
It also optimizes memory allocation to avoid video memory overflow during inference, ensuring stable model operation on ordinary hardware.
Additionally, the Gemma 4 series introduces models specifically designed for end-side devices: E2B and E4B.
The E2B has only 2.3 billion effective parameters, with memory usage compressible to under 1.5GB through quantization, enabling completely offline operation on Raspberry Pis, phones, and edge computing devices.
The E4B is deeply optimized for Android devices, with a context length of 128K and performance surpassing the previous generation's 7B model, suitable for phones, tablets, and other mobile devices.
Google has also collaborated closely with the Pixel team, Qualcomm, and MediaTek to perform chip-level optimizations for the Android ecosystem. The Gemini Nano 4 on next-generation Pixel phones will be built on the E2B/E4B variants of Gemma 4.
This means that ordinary people's phones will soon have high-performance local AI assistants capable of offline speech recognition, real-time translation, image analysis, and other functions, completely independent of network connectivity.

Conclusion:
With the combination of Gemini's homologous technology and the Apache 2.0 license, Google has officially joined the fierce competition in the open-source arena.
This presents both challenges and opportunities for Meta's Llama series and domestic models like Qwen, DeepSeek, and GLM.
The boundaries of AI capabilities are also extending from cloud data centers to mobile devices and offline scenarios without network coverage.
Partial reference sources: APPSO: [Tiny Triumphs Over Giant! Google's Most Powerful Small Model Just Released, Runs on Phones], AI Thought Summit: [Google Open-Sources Gemma 4, Defeats 13x Larger Qwen3.5], InfoQ: [Google's Major Open-Source Release: Gemma 4! Runs Agents Offline on Phones, Reduces Memory, Forces Qwen into Direct Competition], TMTPost AGI: [Byte for Byte, Google's Most Powerful Open-Source Model Gemma 4 Enters Mobile Devices], Phoenix Technology: [Google's Gemma 4 Launches Major Counteroffensive, Will Chinese Open-Source Models Rise to the Challenge?]
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?